

java基础知识整理
数组的length返回的是申请空间的大小。申请后初始化默认值。

比如Math.sum()



equals()没有重写使用的还是object类的比较的是对象地址,重写一般比较属性值是否相等。
hashcode()方法通过比较散列值比较两个对象是否相等,我们比较的时候可以先用hashcode,如果不相等可以直接不等,相等再比较equals。
hashcode是为了降低比较成本的。如果不重写hashcode方法,引用object类的 两个对象不可能相等(该方法通常用来将对象的内存地址转换为整数之后返回)。也就不能用hashcode比较,失去了意义。
包装类型的常量池技术:
Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回 True or False。
也就是说加载的时候会创建相应的缓存数据,装箱的时候(valueOf)如果在常量池范围内会返回常量池的对象。如果不在则创建新对象。比如Integer a = new Integer(1);
Integer b = 1; b会返回常量池里的对象,而a是新创建的对象,两者不相等。如果没有常量池比如Float和Double,都会返回新对象。
装箱:根据字节码其实就是调用valueOf()方法,拆箱实际上就是调用xxxValue()方法。频繁的装箱拆箱会影响系统性能,应该避免。

一个类即使没有声明构造方法也会有默认的不带参数的构造方法。如果我们自己添加了类的构造方法(无论是否有参),Java 就不会再添加默认的无参数的构造方法。如果我们重载了有参的构造方法,记得都要把无参的构造方法也写出来(无论是否用到),因为这可以帮助我们在创建对象的时候少踩坑。
构造方法不能被重写,但是可以重载。
面向对象三大特性:封装(get、set方法)、继承、多态(多态,顾名思义,表示一个对象具有多种的状态。具体表现为父类的引用指向子类的实例)。


Object类:
public final native Class<?> getClass()//native方法,用于返回当前运行时对象的Class对象,使用了final关键字修饰,故不允许子类重写。
public native int hashCode() //native方法,用于返回对象的哈希码,主要使用在哈希表中,比如JDK中的HashMap。
public boolean equals(Object obj)//用于比较2个对象的内存地址是否相等,String类对该方法进行了重写用户比较字符串的值是否相等。
protected native Object clone() throws CloneNotSupportedException//naitive方法,用于创建并返回当前对象的一份拷贝。一般情况下,对于任何对象 x,表达式 x.clone() != x 为true,x.clone().getClass() == x.getClass() 为true。Object本身没有实现Cloneable接口,所以不重写clone方法并且进行调用的话会发生CloneNotSupportedException异常。
public String toString()//返回类的名字@实例的哈希码的16进制的字符串。建议Object所有的子类都重写这个方法。
public final native void notify()//native方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
public final native void notifyAll()//native方法,并且不能重写。跟notify一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
public final native void wait(long timeout) throws InterruptedException//native方法,并且不能重写。暂停线程的执行。注意:sleep方法没有释放锁,而wait方法释放了锁 。timeout是等待时间。
public final void wait(long timeout, int nanos) throws InterruptedException//多了nanos参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上nanos毫秒。
public final void wait() throws InterruptedException//跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念
protected void finalize() throws Throwable { }//实例被垃圾回收器回收的时候触发的操作
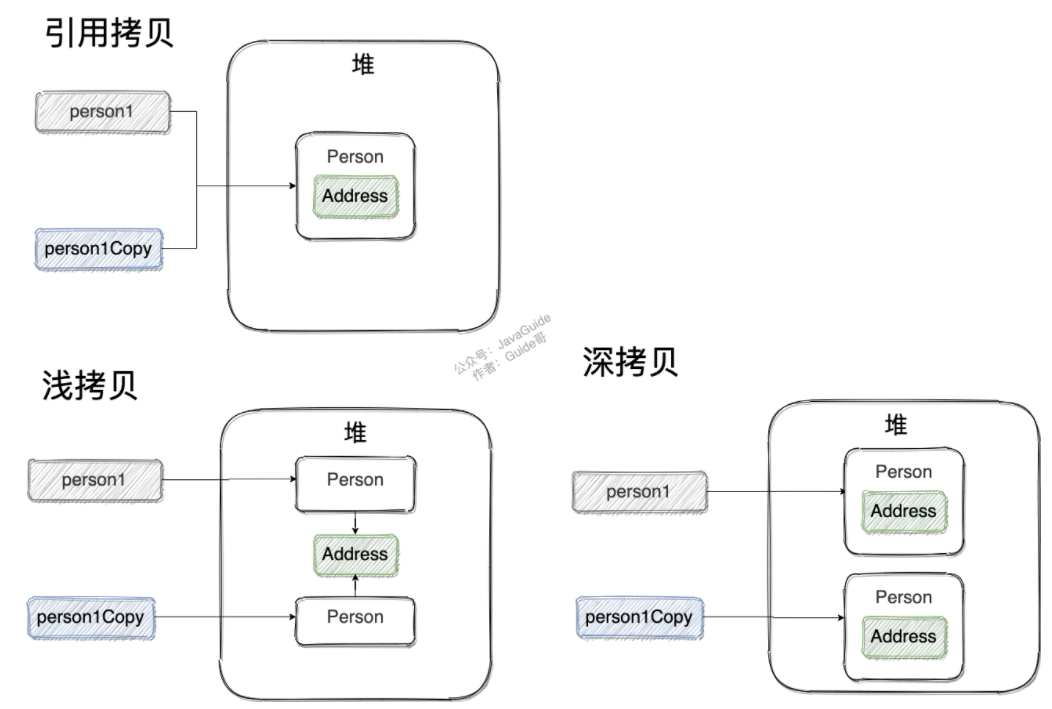
引用拷贝、浅拷贝、深拷贝:
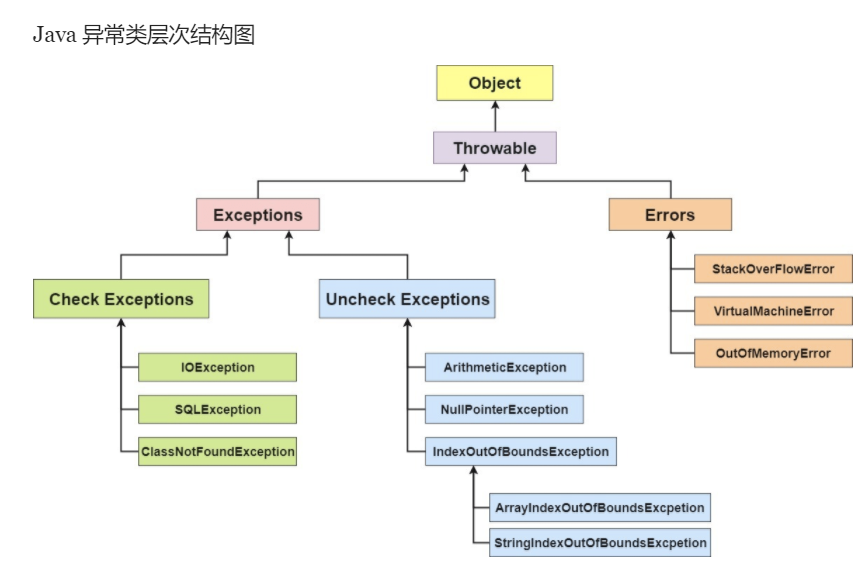
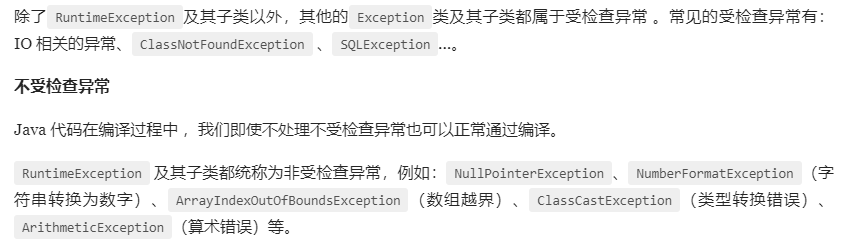
error是无法处理的只能尽量避免,error只要发生只能线程终止。
一个try跟1个或多个cache,如果没有跟cache,则必须有finally。
使用try-with-resource替代try-catch-finally。即将全局资源,比如输入输出等放到try参数里,变成局部变量。

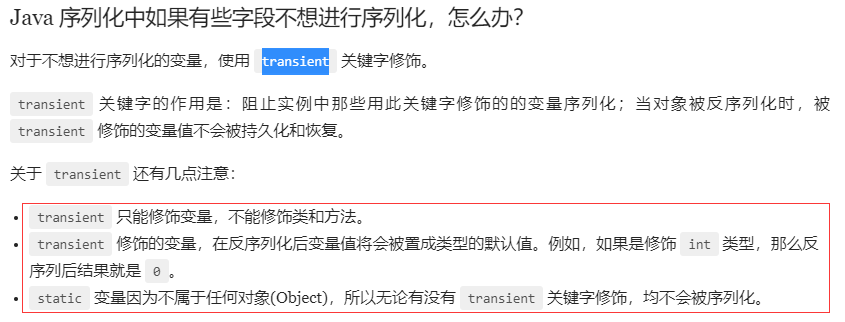

既然有了字节流,为什么还要有字符流?
问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
回答:字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。

java中动态代理和注解都用到了反射。
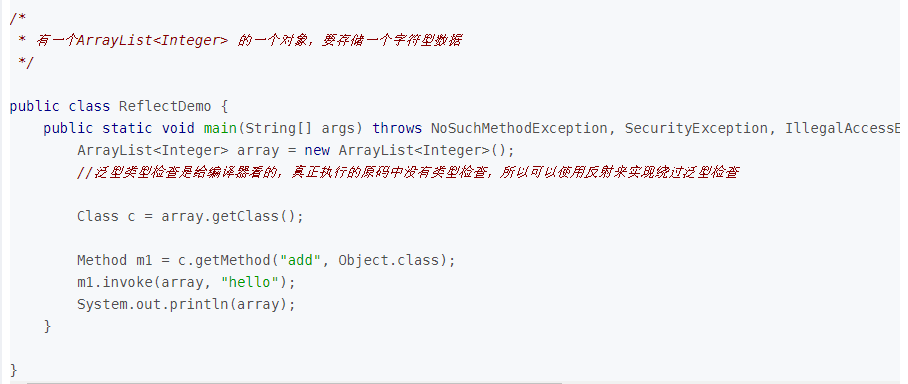
反射为什么能绕过泛型安全检查:泛型安全检查发生在编译时,编译时会擦除泛型信息。反射发生在运行时,也就是说,只要能编译通过(骗过编译器),就可以使用反射操作泛型方法。如下图:


I/O多路复用可以理解为单个线成Selector便可以管理多个客户端连接。
I/O多路复用比同步非阻塞的优势:同步非阻塞会一直轮询调用read,浪费很多系统资源。I/O多路复用实际上就是把多个read轮询换成了查询,直到数据准备好了才返回相应,然后再发read,会直接返回。
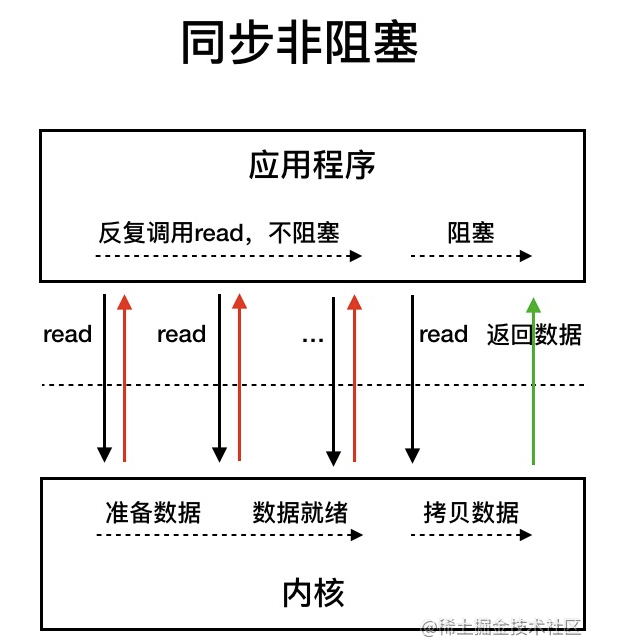
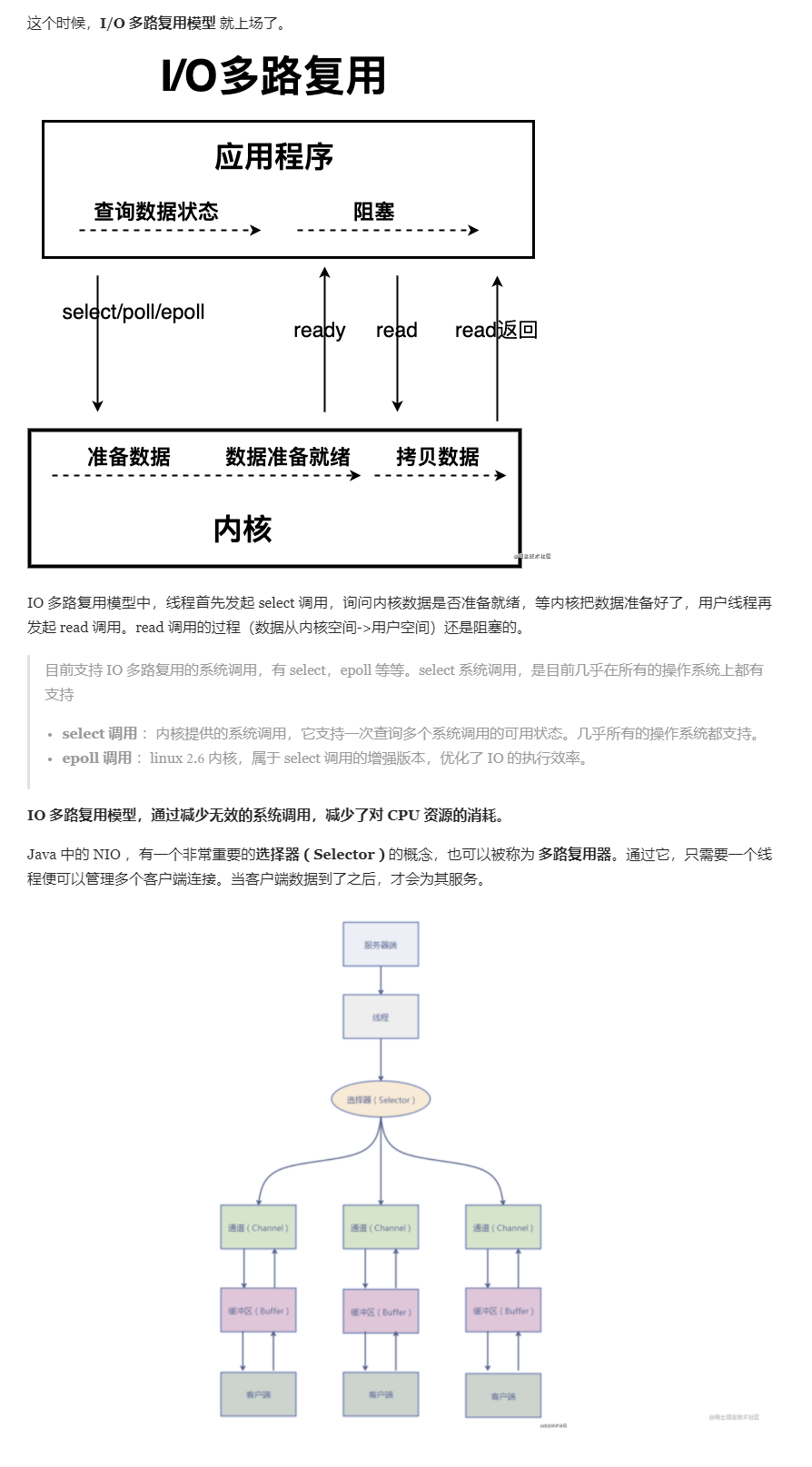
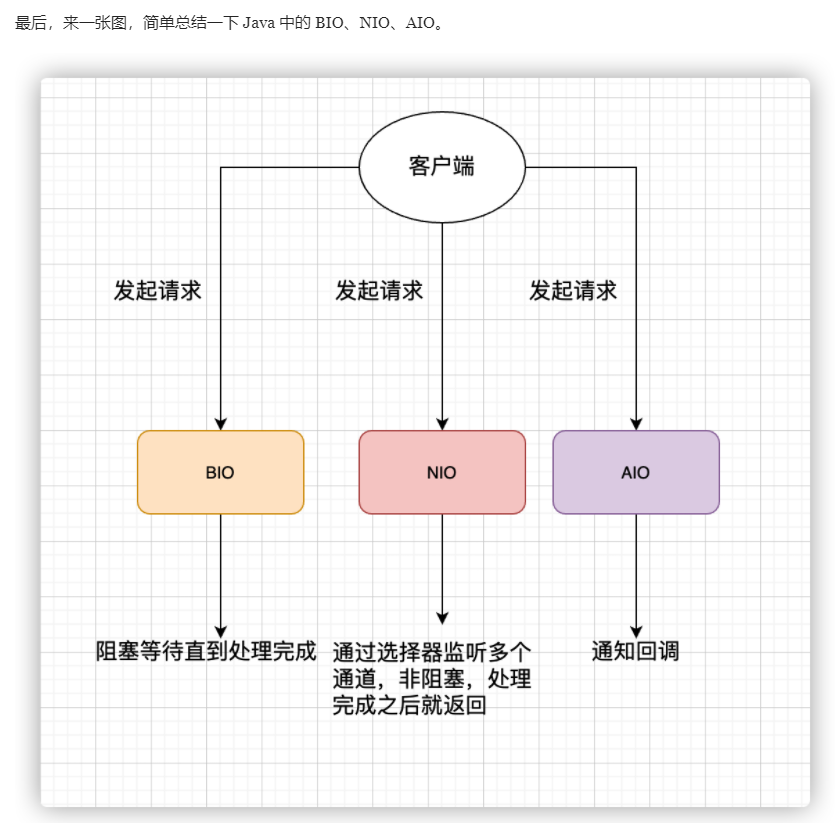
同步异步、阻塞非阻塞理解: https://www.zhihu.com/question/19732473
整理自:https://javaguide.cn/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号