正则表达式基础用法整理
正则表达式
正则表达式
正则表达式的使用
文本的获取
使用requests库来获取B站首页html页面,将其写入到文本中,避免每次测试都需要动用网络资源
immport requests
# 将html页面写入到文本
with open("data.html","w",encoding="utf-8") as html:
response = requests.get("https://www.bilibili.com/")
html.write(response.text)
# 读取文本内容
text = ''
with open("data.html",'r',encoding="utf-8") as html:
text = html.read()
正则表达式学习网站
学习过程中可以使用网站:regex101,来查看匹配效果(上面为正则表达式,下面为文本内容,右侧为匹配的详细信息):
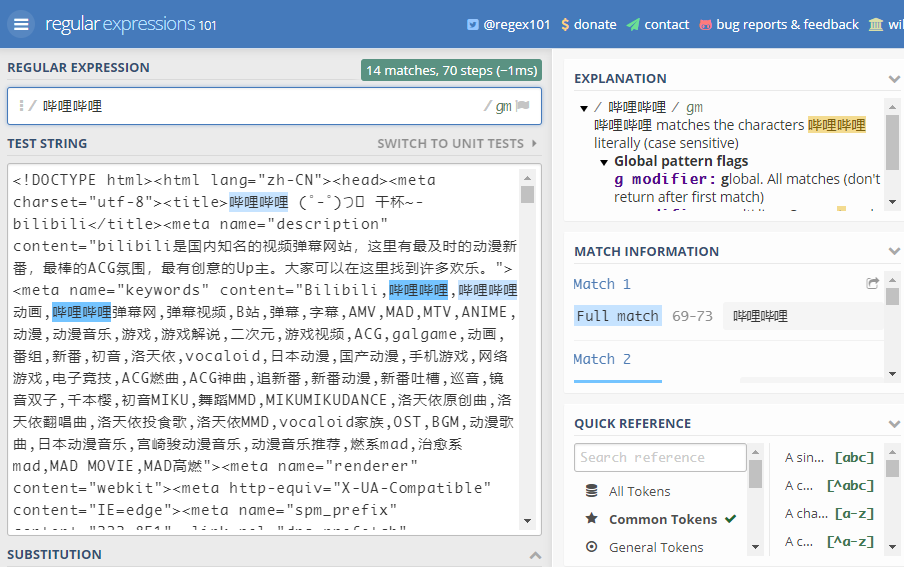
使用python匹配正则表达式 re 库
导入re(regular expression)库
import re
re.Pattern 类
该类通过传入的正则表达式构造Pattern对象,用于去寻找匹配的字符串,通过 re.compilr(pattern string) 函数生成:
pattern = re.compile(r"正则表达式")
通常使用 r"字符串"来表示这是一个原始字符串,即不对一些特殊字符,如"\","\t"等进行转义,以下为两者区别的示例:
>>> str = "this is a string.\n \tand this is the second line."
>>> print(str)
this is a string.
and this is the second line.
>>> str = r"this is a string.\n \tand this is the second line."
>>> print(str)
this is a string.\n \tand this is the second line.
pattern.finall(str)
该方法为pattern对象的方法,用于依据正则表达式在匹配传入文本中的所有内容,将符合规则的字符串存入列表中,最后返回该列表。
例:
re.compile(r"哔哩哔哩")
strList = patern.findall(text)
print(strList)
<class 'list'>
['哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩
哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩',
'哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔
哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩']
正则表达式中的特殊元字符
正则表达式的特殊字符包括:. * + ? \ [ ] ^ $ { } | ( )
按照字符出现次数匹配
任意字符 .
. 表示要匹配除了换行符之外的任何单个字符。
例:
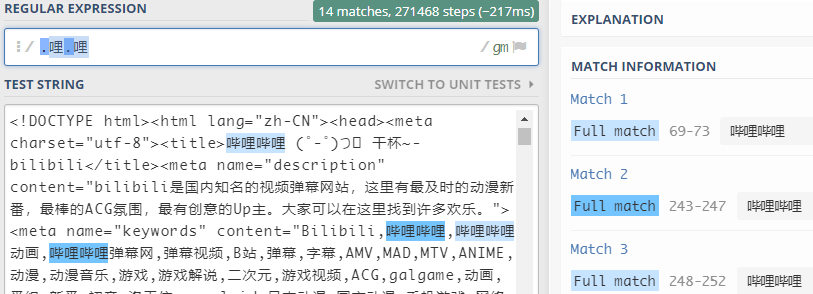
例:python示例:
pattern = re.compile(r'.哩.哩')
strList = pattern.findall(text)
print(strList)
['哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩
哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩',
'哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔
哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩', '哔哩哔哩']
-
可以设置字符匹配模式为
DOTALL模式来使得.匹配换行符content = ''' <div class="el"> <p class="t1"> <span> <a>Python开发工程师</a> </span> </p> <span class="t2">南京</span> <span class="t3">1.5-2万/月</span> </div> <div class="el"> <p class="t1"> <span> <a>java开发工程师</a> </span> </p> <span class="t2">苏州</span> <span class="t3">1.5-2/月</span> </div> ''' pattern = re.compile(r'class=\"t1\">.*?<a>(.*?)</a>', re.DOTALL) print(pattern.findall()) [Python开发工程师, java开发工程师]
任意个数字符 *
*表示匹配前面子表达式任意次。
例:
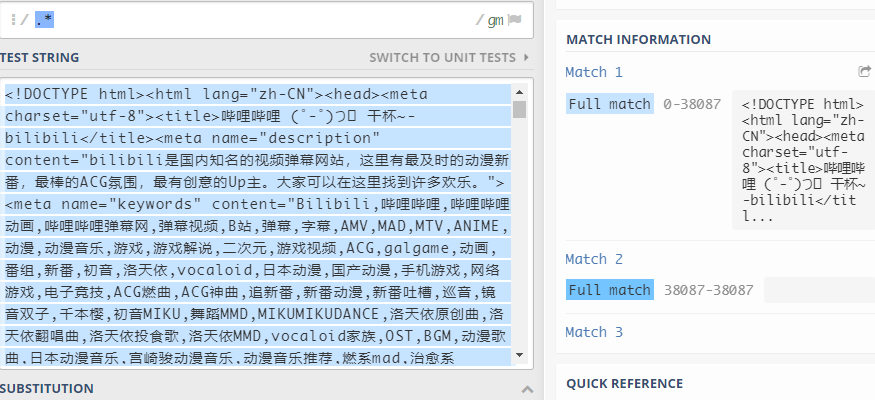
该处 . 匹配任意字符, * 匹配前面任意字符的任意重复字符串,故匹配的字符串为全文
例:
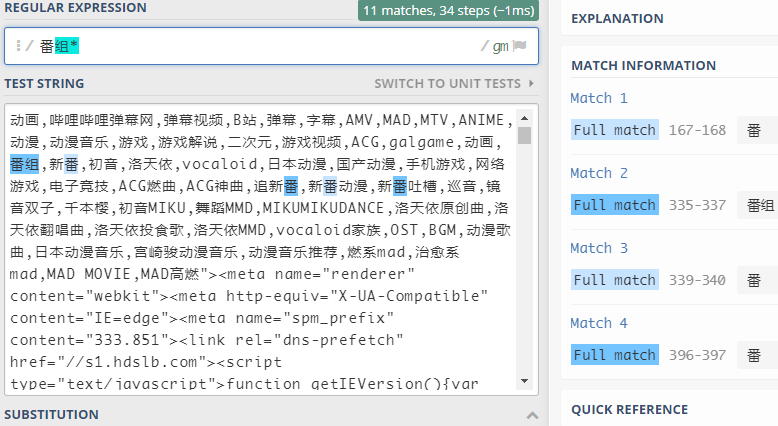
该表达式表示匹配"番"+"组"*n (n>=0)这种形式的字符串
存在或多个字符 +
+表示匹配前面的子表达式1次或者多次,不包括0次
例:
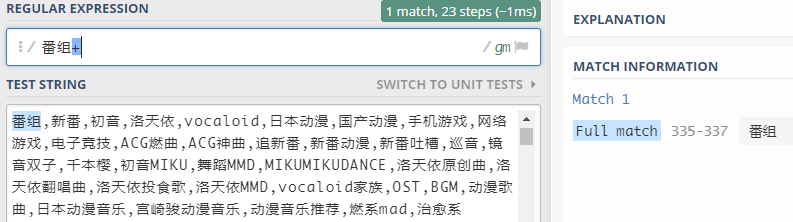
该表达式表示匹配"番"+"组"*n (n>=1)这种形式的字符串
非确定字符是否存在 ?
?表示匹配前面的子表达式0或1次
例:
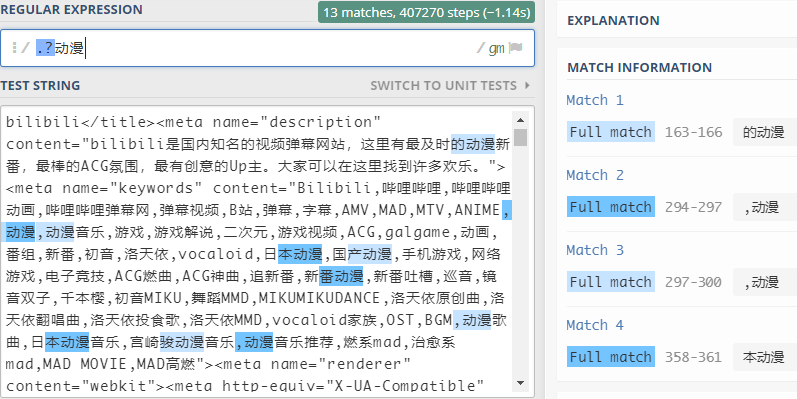
指定字符出现次数 {m,n}
-
{m,n}表示匹配前面的子表达式m至n次,它会以最大匹配次数来进行匹配 -
{m,}表示匹配前面的子表达式至少m次,它会以最大匹配次数来进行匹配 -
{m}表示匹配前面的子表达式m次,它只会匹配m次,即时后面还有可匹配的
例:
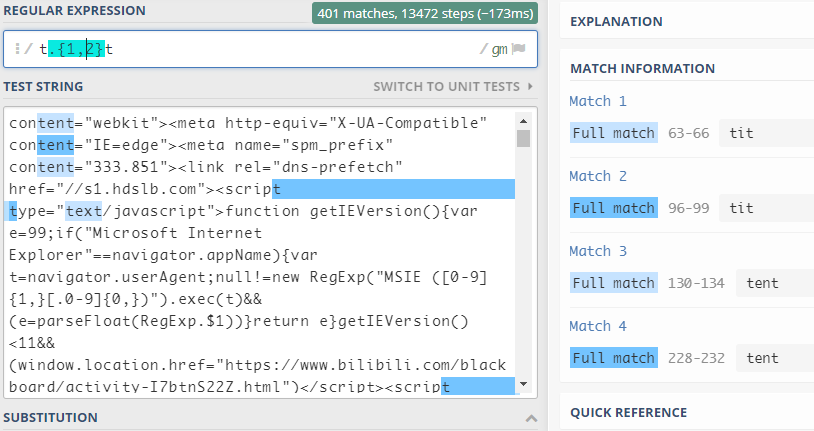
例:

例:
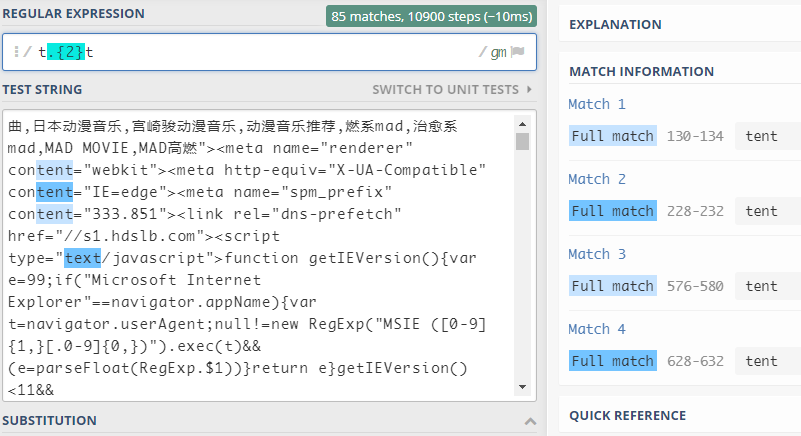
制定字符的范围
指定字符范围 []
-
[abcd]表示该字符只要符合为括号中的一项即可; -
[m-n]表示在m至n的范围内都符合该规则; -
特殊字符在
[]中不再表示其特殊含。字符
\依旧会有转义作用,故若想匹配字符\需要"[\\]"。
例:
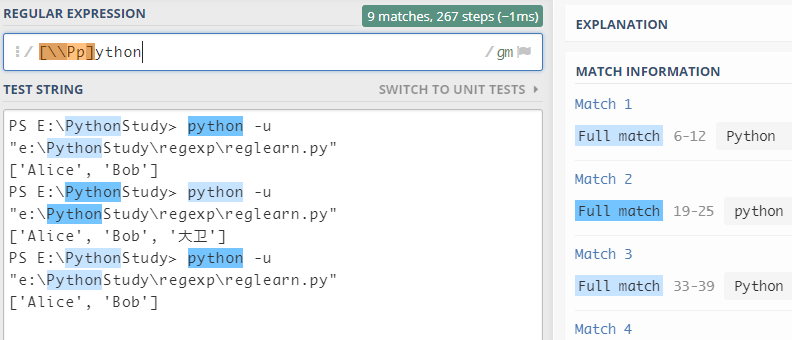
从本例看出,虽然原始文本中有
\Python,但是正则表达式只会匹配括号中的一个字符。
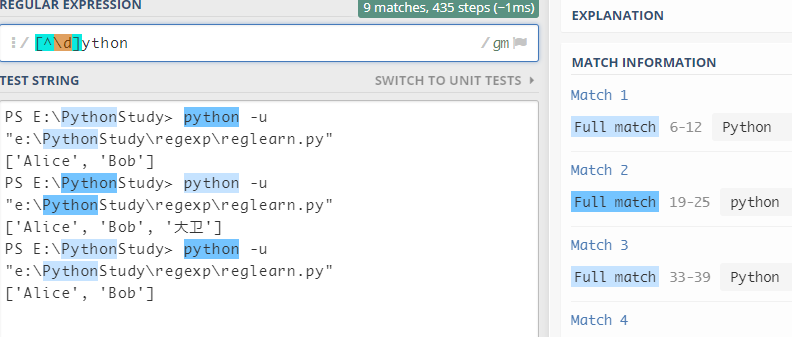
如果在方括号中使用 ^ ,表示匹配不是括号中的字符
例:
| 字符簇 | 描述 |
|---|---|
^[a-zA-Z_]$ |
所有的字母和下划线 |
^[[:alpha:]]{3}$ |
所有的3个字母的单词 |
^a$ |
字母a |
^a{4}$ |
aaaa |
^a{2,4}$ |
aa,aaa或aaaa |
^a{1,3}$ |
a,aa或aaa |
^a{2,}$ |
包含多于两个a的字符串 |
^a{2,} |
如:aardvark和aaab,但apple不行 |
a{2,} |
如:baad和aaa,但Nantucket不行 |
\t{2} |
两个制表符 |
.{2} |
所有的两个字符 |
位置匹配
开头 ^
表示匹配文本的起始位置;
-
如果是单行模式 ,表示匹配整个文本的开头位置;
例:
text = """PS E:\PythonStudy> python -u "e:\PythonStudy\regexp\reglearn.py" ['Alice', 'Bob'] PS E:\PythonStudy> python -u "e:\PythonStudy\regexp\reglearn.py" ['Alice', 'Bob', '大卫'] PS E:\PythonStudy> python -u "e:\PythonStudy\regexp\reglearn.py" ['Alice', 'Bob'] """ pattern = re.compile(r'^P.*?>') strList = pattern.findall(text) print(strList) ['PS E:\\PythonStudy>'] -
如果是多行模式 ,表示匹配文本每行的开头位置;
例:
pattern = re.compile(r'^P.*>',re.MULTILINE) strList = pattern.findall(text) print(strList) ['PS E:\\PythonStudy>', 'PS E:\\PythonStudy>', 'PS E:\\PythonStudy>']
通过向
re,compile函数传入re.MUTILINE或者re.M构建pattern对象,实现多行匹配模式。
结尾 $
表示匹配文本的结束位置:
-
如果是单行模式,表示匹配整个文本的结尾位置;
例:
text = """Alice say : <== privateKey Bob say : ==> publicKey """ pattern = re.compile(r'\S*$') strList = pattern.findall(text) print(strList) ['publicKey', '', ''] -
如果是多行模式,表示匹配文本每行的结尾位置;
例:
pattern = re.compile(r'\S*$',re.M) strList = pattern.findall(text) print(strList) ['privateKey', '', 'publicKey', '', '']
其他
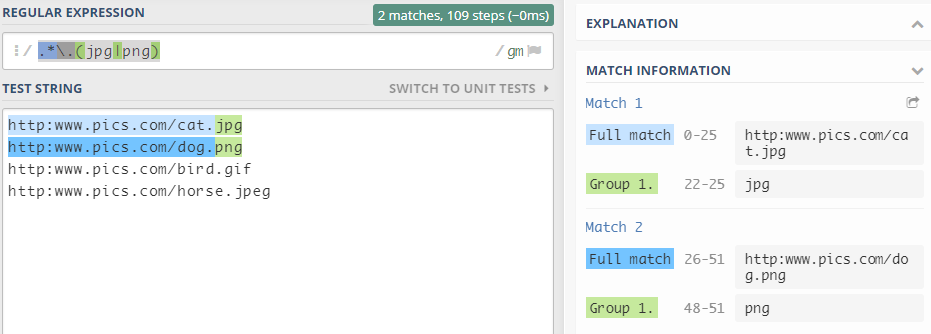
其中之一|
表示匹配前者或者后者,必须符合其中一个标准
例:
转义 \
对特殊字符进行转义,用于将特殊字符看做普通字符,参与匹配过程:
| 模式 | 含义 |
|---|---|
\w |
匹配数字字母下划线等价于[ a-zA-Z0-9 ],缺省情况下也包括Unicode文字字符,可以指定为只包括Ascll字符 |
\W |
匹配非数字字母下划线,等价于[ ^a-zA-Z0-9 ] |
\s |
匹配任意空白字符,等价于 [ \t\n\r\f ](tab,换行,空格) |
\S |
匹配任意非空字符,等价于[ ^\t\n\r\f] |
\d |
匹配任意数字,等价于 [0-9]。 |
\D |
匹配任意非数字,等价于[ ^0-9 ] |
\A |
匹配字符串开始 |
\Z |
匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
\z |
匹配字符串结束 |
\G |
匹配最后匹配完成的位置。 |
\b |
匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
\B |
匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
\n, \t, \f,\v |
匹配一个换行符,等价于 \x0a 和 \cJ;匹配一个制表符, 等价于 \x09 和 \cI;等;匹配一个换页符,等价于 \x0c 和 \cL;匹配一个垂直制表符。等价于 \x0b 和 \cK |
数字:
| 模式 | 含义 |
|---|---|
\xn |
匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。 |
\num |
匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 |
\n |
标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
\nm |
标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
\nml |
如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
\un |
匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
对于\w,如果不指定风格,则会包含unicode编码字符
例:
text = """
Alice
Bob
大卫
"""
pattern = re.compile(r'\w{2,5}')
strList = pattern.findall(text)
print(strList)//['Alice', 'Bob', '大卫']
可以使用指定方式re.A,或则re.ASCII指定匹配模式为字符只包含ascii码的字符。
例:pattern = re.compile(r'\w{2,5}',re.A) strList = pattern.findall(text) print(strList)//['Alice', 'Bob']
PHP内置的通用字符簇
| 字符簇 | 描述 |
|---|---|
[[:alpha:]] |
任何字母 |
[[:digit:]] |
任何数字 |
[[:alnum:]] |
任何字母和数字 |
[[:space:]] |
任何空白字符 |
[[:upper:]] |
任何大写字母 |
[[:lower:]] |
任何小写字母 |
[[:punct:]] |
任何标点符号 |
[[:xdigit:]] |
任何16进制的数字,相当于[0-9a-fA-F] |
分组
当通过正则表达式寻找匹配字符串时,可以通过加入 () 的方式来对结果进行分组,从而获取匹配字符串中的有效信息。
例:
text = """
2020-4-13 22:04:27 Alice : hello,world.
2020-4-13 22:04:32 Bob : nice to meet you.
"""
# 使用分组
pattern = re.compile(r'(\w*)\s:\s(.*).',re.M)
strList = pattern.findall(text)
print(strList)
# 不使用分组
pattern = re.compile(r'\w*\s:\s.*.',re.M)
strList = pattern.findall(text)
print(strList)
结果:
[('Alice', 'hello,world'), ('Bob', 'nice to meet you')]
['Alice : hello,world.', 'Bob : nice to meet you.']
通过使用()将所需要的信息分离出来,最终会以元素为元组的列表作为返回结果。
贪婪模式与非贪婪模式
贪婪模式
贪婪模式是指在匹配时会尽可能的多匹配,当匹配的字符串已经符合要求时,如果后面的字符串依旧符合要求,则会继续进行匹配,直到后面的字符串不符合规则。
例:


在寻找""pic":xxxxx.jpg"时,即时到第3行就已经匹配完成了,在该模式下,依旧会进行匹配,直至找到最后一个.jpg
+,*都为贪婪模式,会尽可能地去匹配
非贪婪模式
该模式匹配到第一个符合表达式规则的字符串就会停止。
通过在 + , *, {} 后面加上 ? 来使之以非贪婪模式匹配,只要满足第一次符合规则的情况就可以
例:
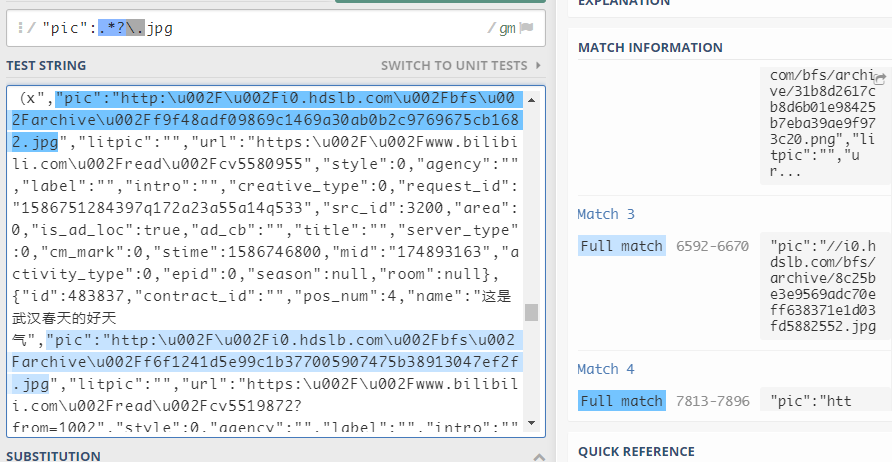
在寻找到第一个符合表达式就停止,输出匹配字符串,再继续检测
例:
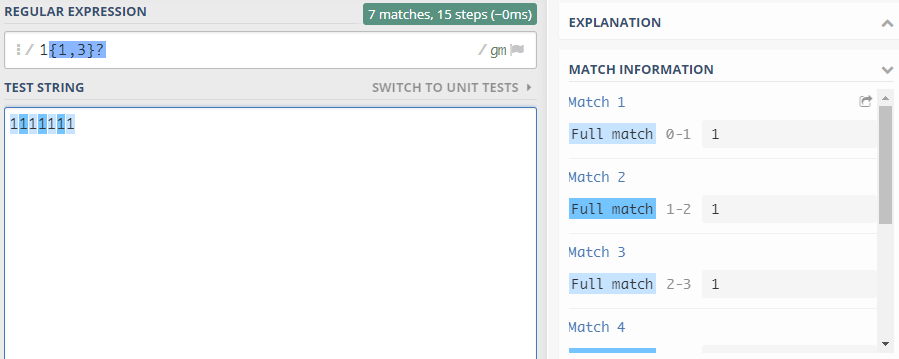
本来结果应该是111,111,1,加入?之后只要有一个1即符合表达式,所以结果为1,1,1,1,1,1,1
运算符优先级
从左向右计算、遵循优先级顺序
| 运算符 | 描述 |
|---|---|
\ |
转义符 |
(), (?:), (?=), [] |
圆括号和方括号 |
*, +, ?, {n}, {n,}, {n,m} |
限定符 |
^, $, \任何元字符、任何字符 |
定位点和序列(即:位置和顺序) |
| |
替换,"或"操作 字符具有高于替换运算符的优先级,使得"m|food"匹配"m"或"food"。若要匹配"mood"或"food",请使用括号创建子表达式,从而产生"(m|f)ood"。 |
python正则表达式使用
re库函数
re.match(pattern, string, flags=0)
该方法只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None;
如果匹配成功返回 match 对象,通过 group 方法来获得结果。
例:
text = """http:www.pics.com/cat.jpg
http:www.imgs.com/dog.png
http:www.imgs.com/doge.png
http:www.pics.com/bird.gif
http:www.pics.com/horse.jpeg
"""
pattern = 'http.*\.(.*)\.com.*(\S*\.\S*)'
print(re.match(pattern, text).group(0))
print(re.match(pattern, text).group(1))
print(re.match(pattern, text).group(2))
print(re.match(pattern, text).group())
http:www.pics.com/cat.jpg
pics
.jpg
http:www.pics.com/cat.jpg
match.group(0):为匹配到的整体结果;match.group(n):为匹配到的第n个分组;
re.search(pattern, string, flags=0)
扫描整个字符串并返回第一个成功的匹配。
re.sub(pattern, repl, string, count=0, flags=0)
用于替换字符串中的匹配项:
-
repl: 替换的字符串,也可为一个函数 -
count: 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配
该方法返回一个新的被替换的字符串,源字符串不受影响。
例:
print(re.sub(pattern,"哈哈",text))
哈哈:www.pics.com/cat.jpg
哈哈:www.imgs.com/dog.png
哈哈:www.imgs.com/doge.png
哈哈:www.pics.com/bird.gif
哈哈:www.pics.com/horse.jpeg
re.compile(pattern[, flags])
用于编译正则表达式,生成一个正则表达式( Pattern )对象,提供 match() 和 search() 这两个函数使用
Pattern对象拥有re中的函数方法,实际上查看函数的实现方式就是先构造一个Pattern对象,再调用相应的方法。
例:
pattern = re.compile(r'pics.*/(\S+).*')
print(re.sub(pattern,"哈哈",text))
print(pattern.sub("哈哈",text)) # 两者效果相同
python源码:
# 这是re.search方法,其它类似
def search(pattern, string, flags=0):
"""Scan through string looking for a match to the pattern, returning
a Match object, or None if no match was found."""
return _compile(pattern, flags).search(string)
- re.中的匹配函数全部为套娃方法,即先构造Pattern对象,再利用该对象的方法完成其功能
re.findall(string[, pos[, endpos]])
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
re.finditer(pattern, string, flags=0)
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串的 match 对象,并把它们作为一个迭代器返回
例:
pattern = re.compile(r'pics.*/(\S+).*')
for match in pattern.finditer(text):
print(match.group(1))
cat.jpg
bird.gif
horse.jpeg
re.split(pattern, string[, maxsplit=0, flags=0])
split 方法按照能够匹配的子串将字符串分割后返回列表。
例:
pattern = re.compile(r'/')
print(pattern.split(text))
['http:www.pics.com', 'cat.jpg\nhttp:www.imgs.com', 'dog.png\nhttp:www.imgs.com', 'doge.png\nhttp:www.pics.com', 'bird.gif\nhttp:www.pics.com', 'horse.jpeg\n']
python中的匹配模式
源码:
class RegexFlag(enum.IntFlag):
ASCII = sre_compile.SRE_FLAG_ASCII # assume ascii "locale" 指定字符集为ascii码
IGNORECASE = sre_compile.SRE_FLAG_IGNORECASE # ignore case 忽略大小写
LOCALE = sre_compile.SRE_FLAG_LOCALE # assume current 8-bit locale
UNICODE = sre_compile.SRE_FLAG_UNICODE # assume unicode "locale" 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B
MULTILINE = sre_compile.SRE_FLAG_MULTILINE # make anchors look for newline 多行匹配
DOTALL = sre_compile.SRE_FLAG_DOTALL # make dot match newline 使 . 匹配包括换行在内的所有字符
VERBOSE = sre_compile.SRE_FLAG_VERBOSE # ignore whitespace and comments 这个选项忽略规则表达式中的空白和注释,并允许使用 ’#’ 来引导一个注释。这样可以让你把规则写得更美观些
A = ASCII
I = IGNORECASE
L = LOCALE
U = UNICODE
M = MULTILINE
S = DOTALL
X = VERBOSE
# sre extensions (experimental, don't rely on these)
TEMPLATE = sre_compile.SRE_FLAG_TEMPLATE # disable backtracking
T = TEMPLATE
DEBUG = sre_compile.SRE_FLAG_DEBUG # dump pattern after compilation

 浙公网安备 33010602011771号
浙公网安备 33010602011771号