
一只想成长的爬虫——requests库~~
requests库
1安装

2.使用
3.其他方法

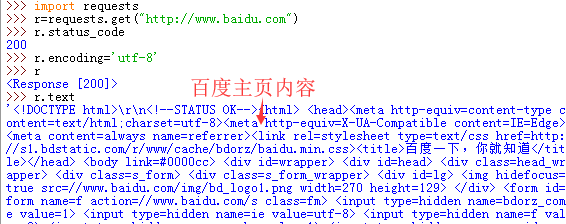
*requests的get方法
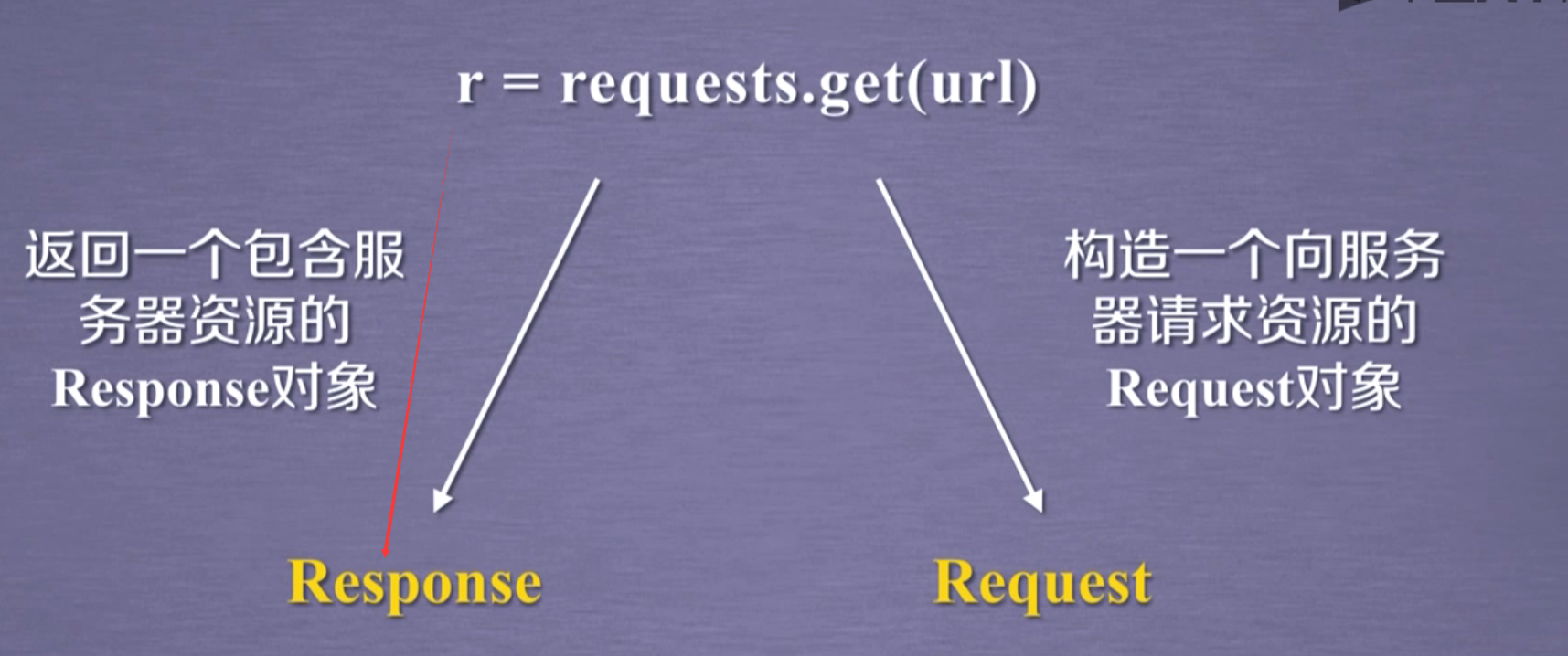

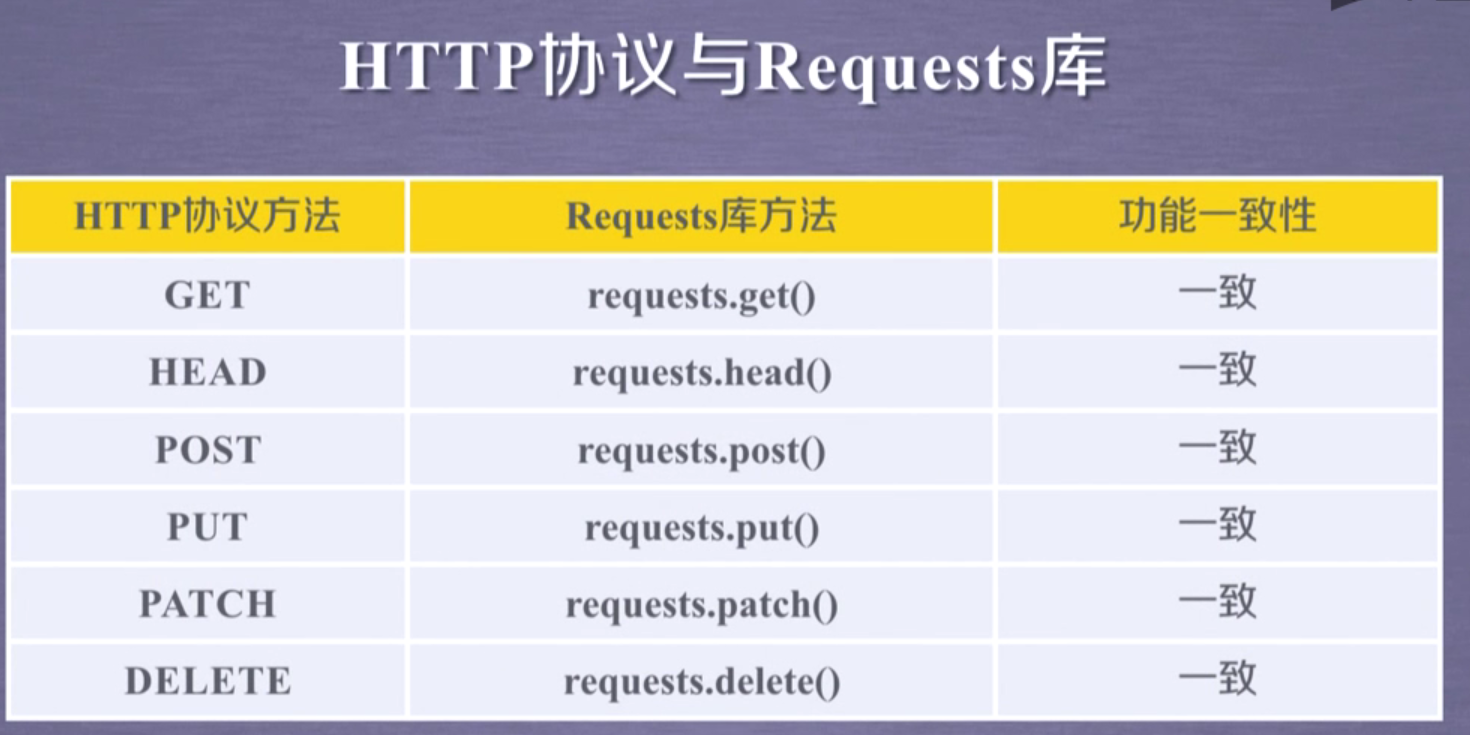
他返回和我使用urllib.request构建走的:
rq=urllib.request.Request(url[,data][,header])
response=urllib.request.urlopen(rq)
一样


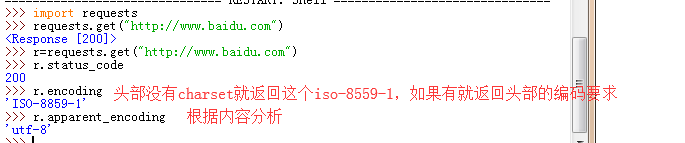


使用下图,利用response当返回的不是200(成功)的时候就产生HTTPError的异常






put()将原有的数据覆盖掉

requests.request方法


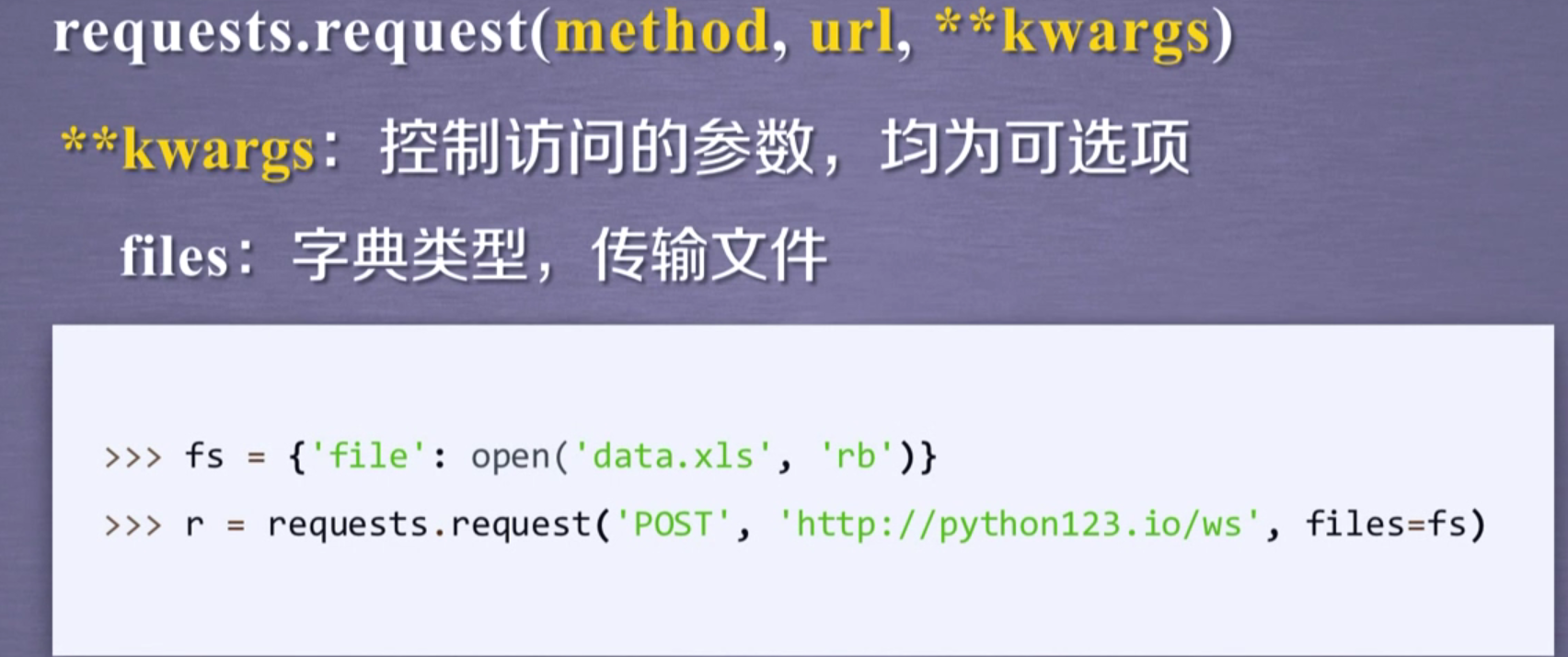
13个控制访问参数
**开头就需要把参数也给写上,如下面params=kv






增加代理~~~


params:对url进行修改的字段
data:如果等于键值对,传入到Form中,以键值对显示,如果不是键值对,那么直接上传到data中
json:将json传输出去
*headers:定制头部信息,修改headers!!!
cookies:
auth:
*files:向指定网址或服务器上传文件,常和open一起使用
timeout设置超时时间 /秒
*proxies:字典/设置代理服务器
allow_redirects:重定向开关
stream:获取内容立即下载开关
verify:认证SSL证书开关
cert:本地SSL证书路径
requests.get方法【最常用的的方法】
【因为HTTP协议中向服务器提交是严格受控的】
访问参数就是除了request中除了params的参数
下面以此类推,总之,所有方法都在request的13个方法内

head..

post

put

patch...

delete..

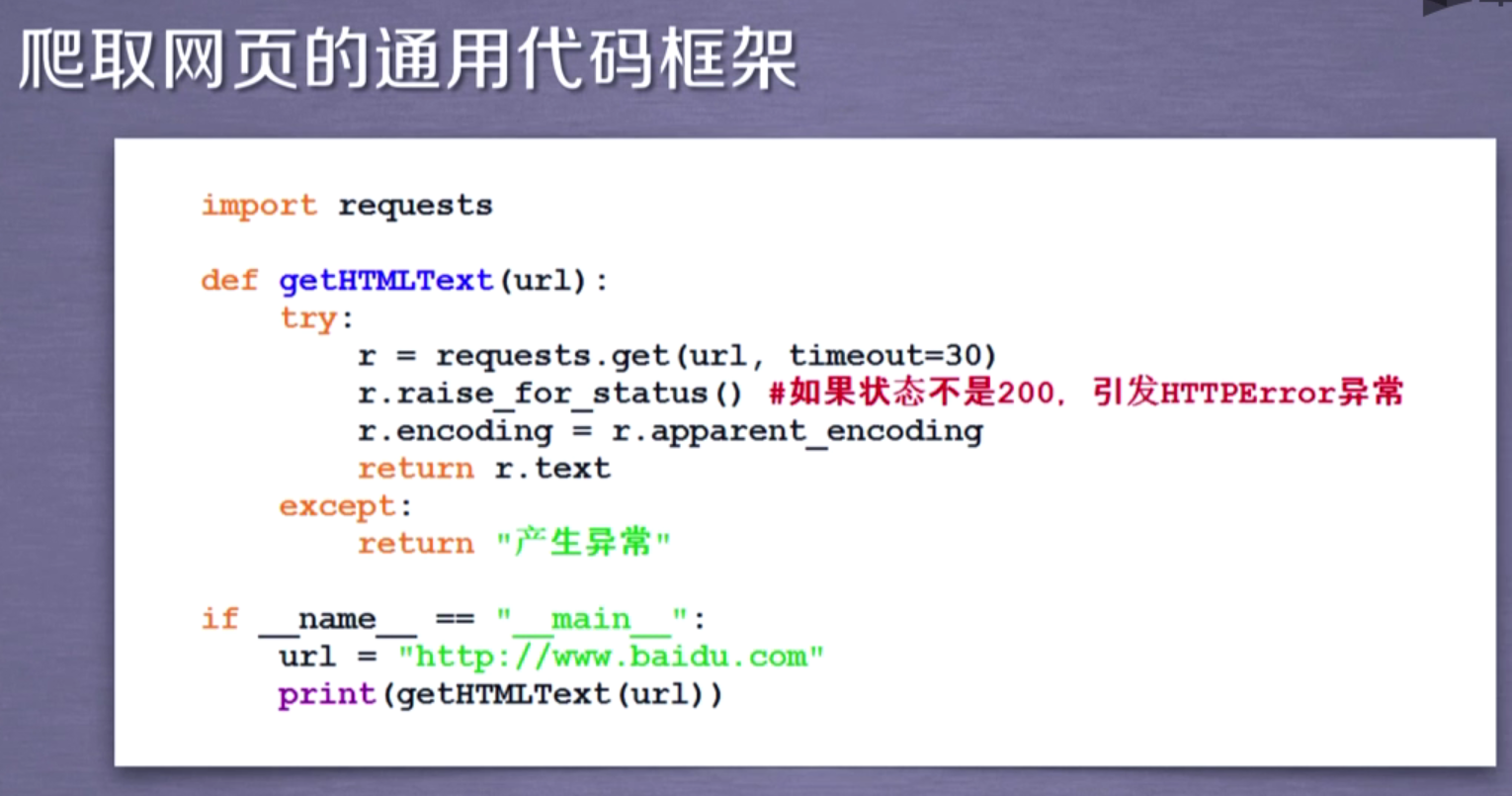
一定要用try..except 方式保证异常能有效处理


网络爬虫引发的问题~~~~



 浙公网安备 33010602011771号
浙公网安备 33010602011771号