最后的寒假作业
此次选取第一个题目
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/Freshman |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/Freshman/homework/11734 |
| 作业目标 | <学习库的使用,爬取影评的方法,生成词云图以及用 Git 进行源代码管理> |
| 作业源代码 | https://github.com/ningning-zi/WinterVacationHomework |
| 学号 | <212014147> |
一、词云图
第一步:数据采集
打开《你好,李焕英》的豆瓣影评
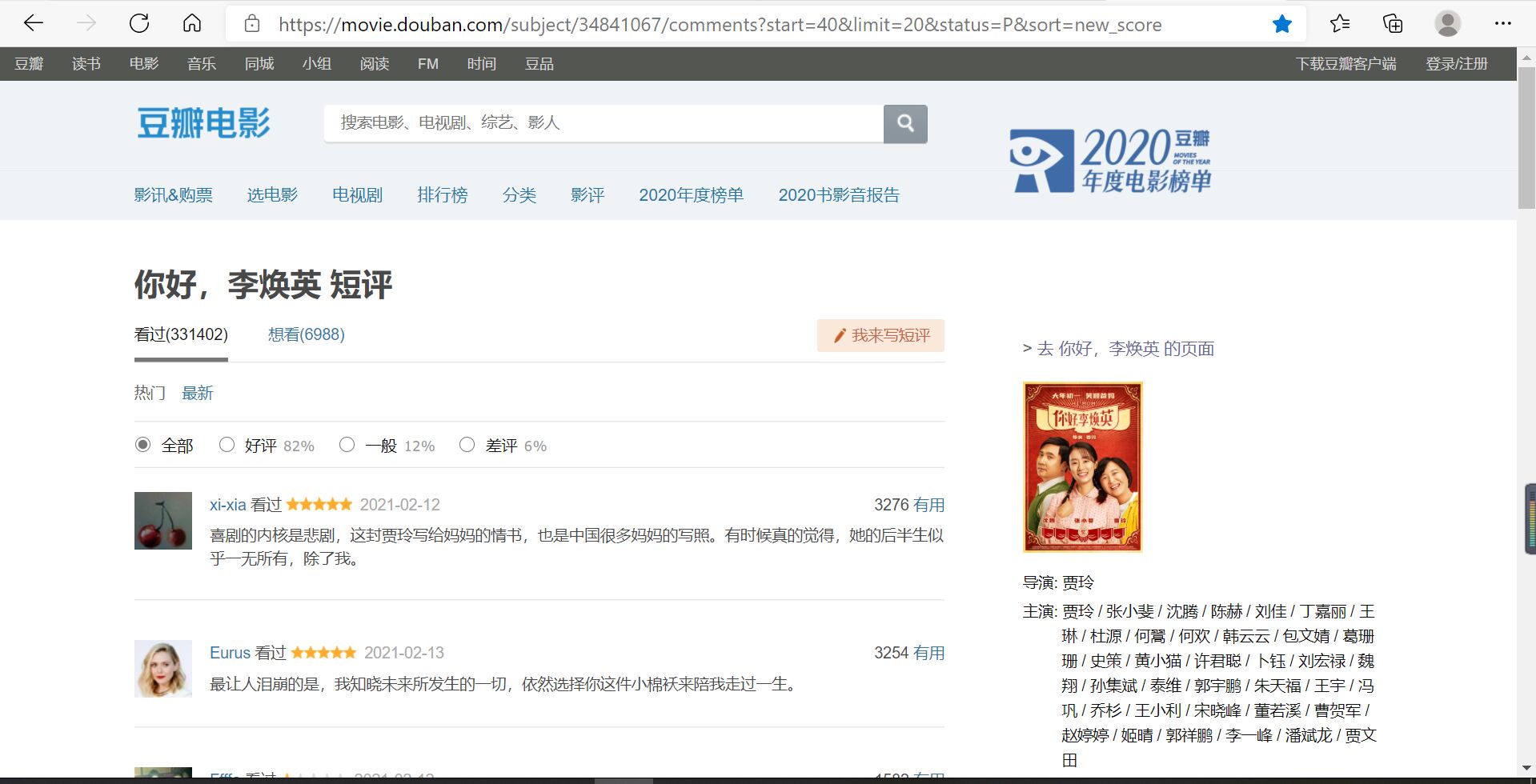
查看源代码

第二步:数据处理
安装所需要的库:requests, jieba, wordcloud, bs4, imageio, beautifulsoup......
爬取影评
import requests
import re
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74'
}
for i in range(0,220,20):
url = 'https://movie.douban.com/subject/34841067/comments?start=%d'%i+'&limit=20&status=P&sort=new_score'
page_text = requests.get(url=url,headers=headers).text#使用通用爬虫对url对应的一整张页面进行爬取
ex = '<span class="short">(.*?)</span>'
text_list = re.findall(ex,page_text)#使用正则解析得到目标数据
print(text_list)
text_list = '\n'.join(text_list)
file = open("hello,mom.txt", "a+",encoding='UTF-8')#保存目标数据至hello,mom.txt
file.write(text_list + "\n")
file.close()
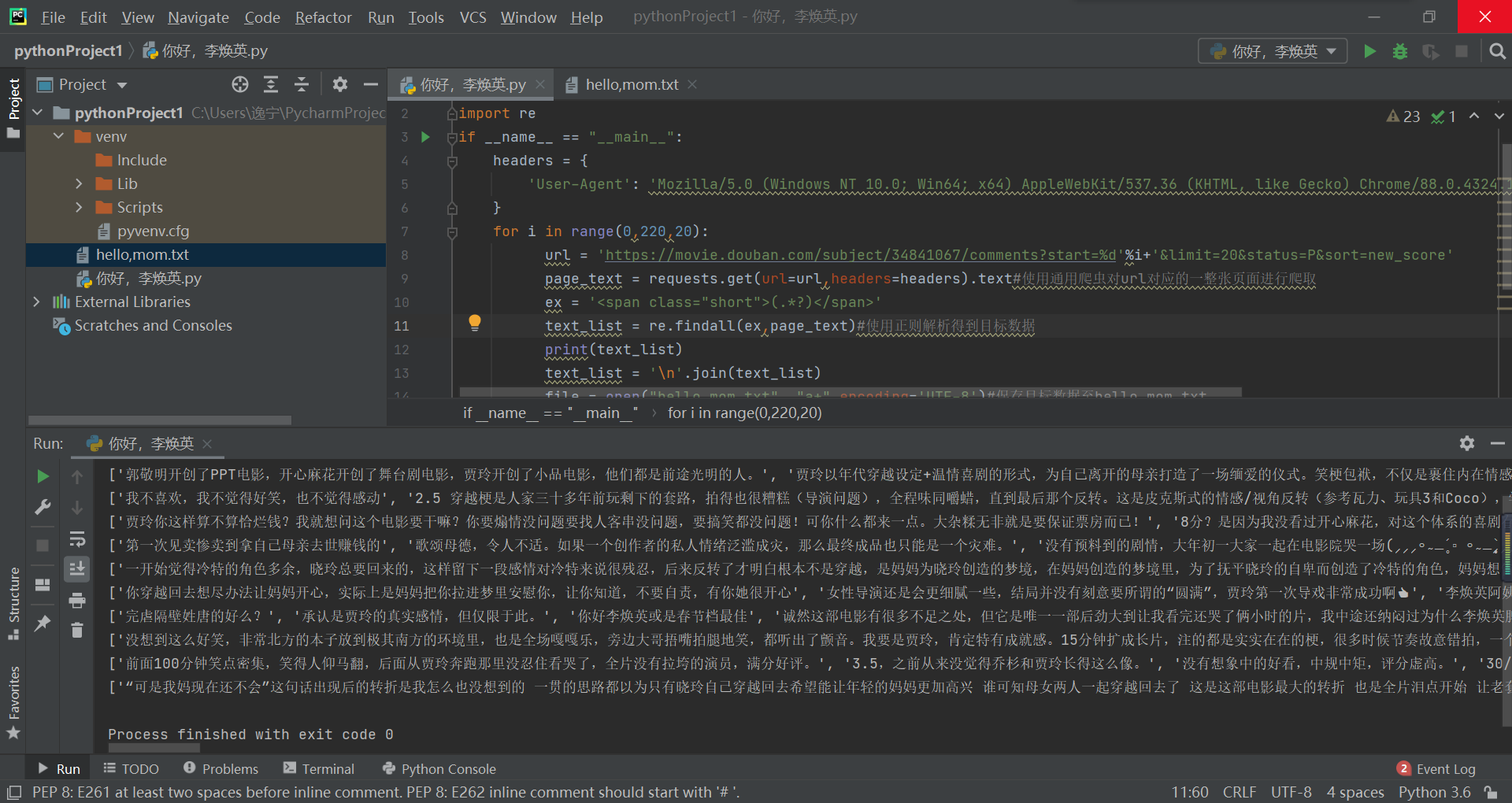
数据将被输出保存到hello,mom.txt中
分词
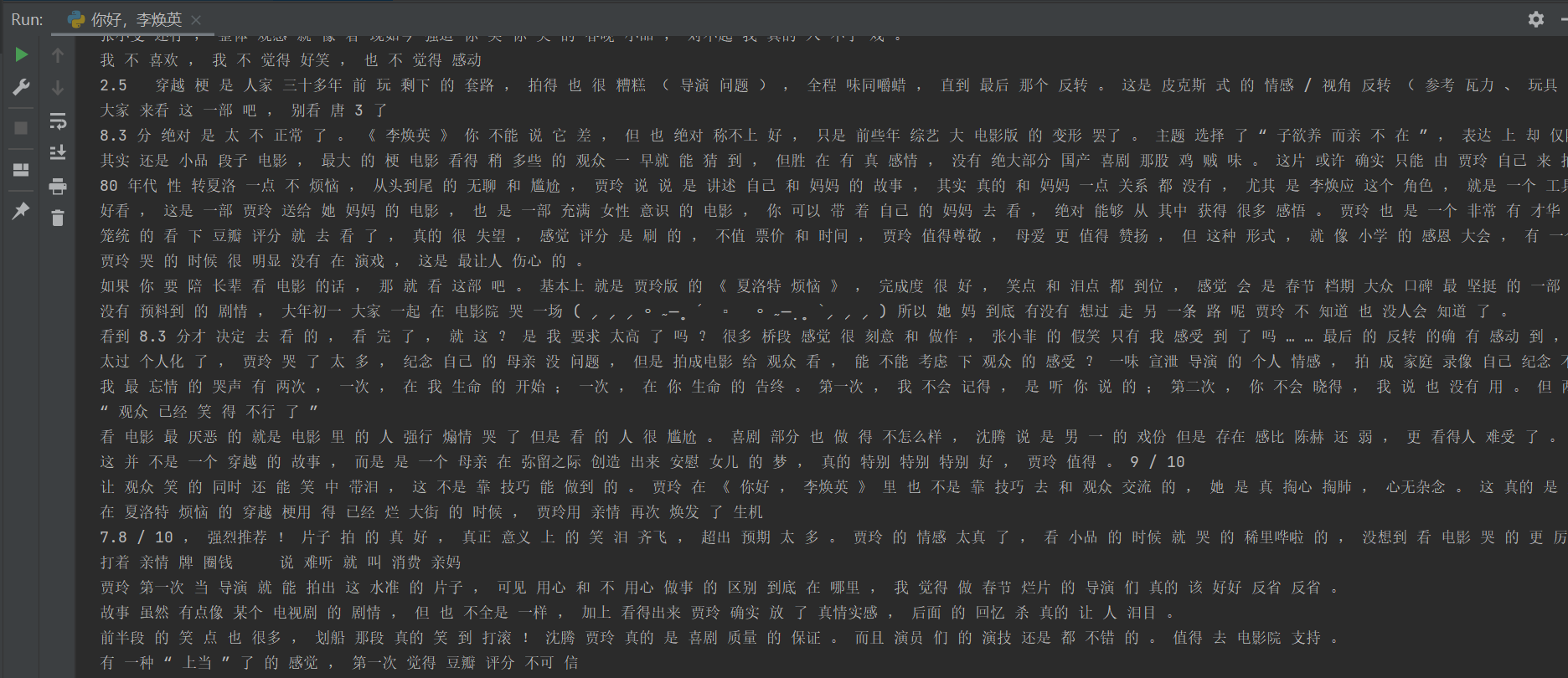
第三步:数据可视化
敲代码,制作词云图
完整代码
import requests
import re
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74'
}
for i in range(0,220,20):
url = 'https://movie.douban.com/subject/34841067/comments?start=%d'%i+'&limit=20&status=P&sort=new_score'
page_text = requests.get(url=url,headers=headers).text#使用通用爬虫对url对应的一整张页面进行爬取
ex = '<span class="short">(.*?)</span>'
text_list = re.findall(ex,page_text)#使用正则解析得到目标数据
print(text_list)
text_list = '\n'.join(text_list)
file = open("hello,mom.txt", "a+",encoding='UTF-8')#保存目标数据至hello,mom.txt
file.write(text_list + "\n")
file.close()
import jieba
import wordcloud
import imageio
f = open('hello,mom.txt',mode="r", encoding='utf-8')
txt = f.read()
txt_list = jieba.lcut(txt)
# print(txt_list)
string1= ' '.join((txt_list))
print(string1)
img = imageio.imread("高冷.png")
w = wordcloud.WordCloud(width=250,
height=300,
background_color='black',
mask=img,
font_path='msyh.ttc',
scale=15,
stopwords=set([line.strip()for line in open("stopwords.txt",mode="r",encoding="utf-8").readlines()]),
contour_width=5,
contour_color='white'
)
w.generate(string1)
w.to_file('hello,mom.png')

添加词云图形状,设计代码如下图所示



二、git
三次commit
第一次

第二次
第三次

三、随笔
| 代码行数 | 需求分析时间 | 编码时间 |
|---|---|---|
| 40 | 45min | n hour |
《你好,李焕英》的影评生成词云图圆满完成,然而在制作词云图的路上实则无比艰难。尤其是安装各种库的时候,常常在ping install 某某库的时候,十有八九都会出现一大串红色的字体,然后开始上网查资料,问度娘和搜狗,各种查,基本网上都有解决的办法。但是,网上搜索制作词云图的方法实在是太多了,要下载的库也不尽相同,需要自己一一筛选排查,最终也学会了词云图的制作和pycharm的用法,希望未来继续学习python的各种用途!!!
参考资料
https://blog.csdn.net/m0_46278037/article/details/113979199
https://www.cnblogs.com/wsmrzx/p/9527087.html
https://www.acfun.cn/v/ac4586568
https://www.acfun.cn/v/ac25926265
https://kanny.blog.csdn.net/article/details/79963042?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-4.control&dist_request_id=94d38c28-507a-4b60-b6d1-1c34d8317ad5&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-4.control
https://blog.csdn.net/weixin_30475039/article/details/98740242?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-16.control&dist_request_id=e935728a-745d-4b40-bf21-bb7f0420a430&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-16.control

 浙公网安备 33010602011771号
浙公网安备 33010602011771号