
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
从与谷歌系统的关系,关键时间节点,1.x,2.x与3.x的区别,不同公司发行版本等方面来讲。
Hadoop起源于Nutch,是Lucene的子项目。以谷歌发表的为解决数十亿网页的存储和索引问题提供了可行的解决方案的论文为基础,Nutch的开发人员完成了相应的开源实现谷歌分布式文件系统(GFS)的架构(03年)、MapReduce系统(04年)、HDFS(04年),并从Nutch中剥离成为独立项目Hadoop。06年Google发表了关于BigTable的论文,促使了后来的Hbase的发展。因此,Hadoop及其生态圈的发展离不开Google的贡献。
1.不同版本的区别
- 1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等,该版本已被淘汰
- 2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性,是现在使用的主流版本。
- 3.x版本系列:对HDFS、MapReduce、YARN都有较大升级,还新增了Ozone key-value存储。
2.社区版本
一、免费开源版本Apache:
优点:拥有全世界的开源贡献者,代码更新迭代版本比较快,
缺点:版本的升级,版本的维护,版本的兼容性,版本的补丁都可能考虑不太周到
二、免费开源版本HortonWorks:
hortonworks核心产品软件HDP(ambari),HDF免费开源,提供一整套的web管理界面,供我们可以通过web界面管理我们的集群状态,2018年,大数据领域的两大巨头公司Cloudera和Hortonworks宣布平等合并。
三、软件收费版本Cloudera:
cloudera主要是美国一家大数据公司在apache开源hadoop的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题。
2.用图与自己的话,简要描述名称节点、数据节点的主要功能及相互关系、名称节点的工作机制。
①名称节点的主要功能:负责管理分布式文件系统的命名空间。
②数据节点的主要功能:负责数据的存储和读取。
③名称节点与数据节点的相互关系:名称节点在系统每次启动时扫描数据节点重构得到信息,数据节点向名称节点定期发送自己所存储的块的列表。
④名称节点工作机制:
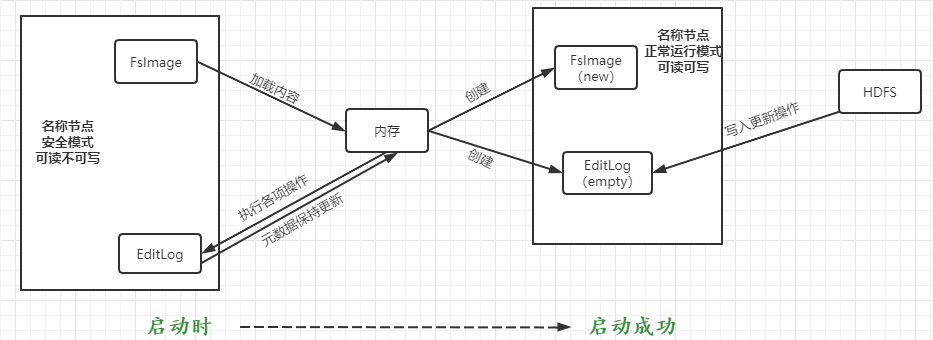
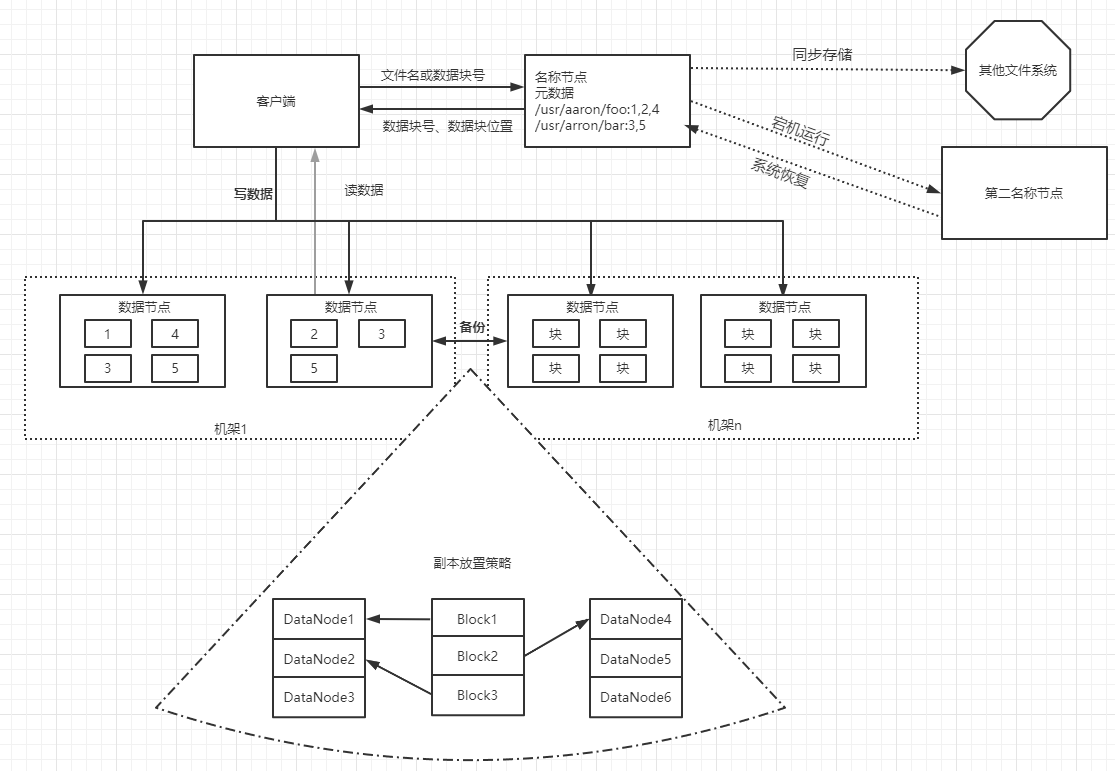
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据节点与集群
- 数据节点与名称节点
- 名称节点与第二名称节点
- 数据节点与数据节点
- 数据冗余
- 数据存取策略
- 数据错误与恢复
4.简述HBase与传统数据库的主要区别
主要体现在以下几个方面:
(1)数据类型。传统数据库采用关系模型,具有丰富的数据类型和储存方式,HBase则采用了更加简单的数据模型。
(2)Hbase无法实现像传统数据库中那样的表与表之间的连接操作。
(3)传统数据库是基于行模式存储的,基于行模式存储就会浪费许多磁盘空间和内存带宽。HBase是基于列存储的,可以获得较高的数据压缩比。
(4)传统数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。与关系数据库不同的是,HBase只有一个索引——行键,由于HBase位于Hadoop框架之上,因此可以使用Hadoop MapReduce来快速、高效地生成索引表。
(5)在传统数据库中,更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在。而在HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍旧保留。
(6)传统数据库很难实现横向扩展,纵向扩展的空间也比较有限。相反,HBase能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩。
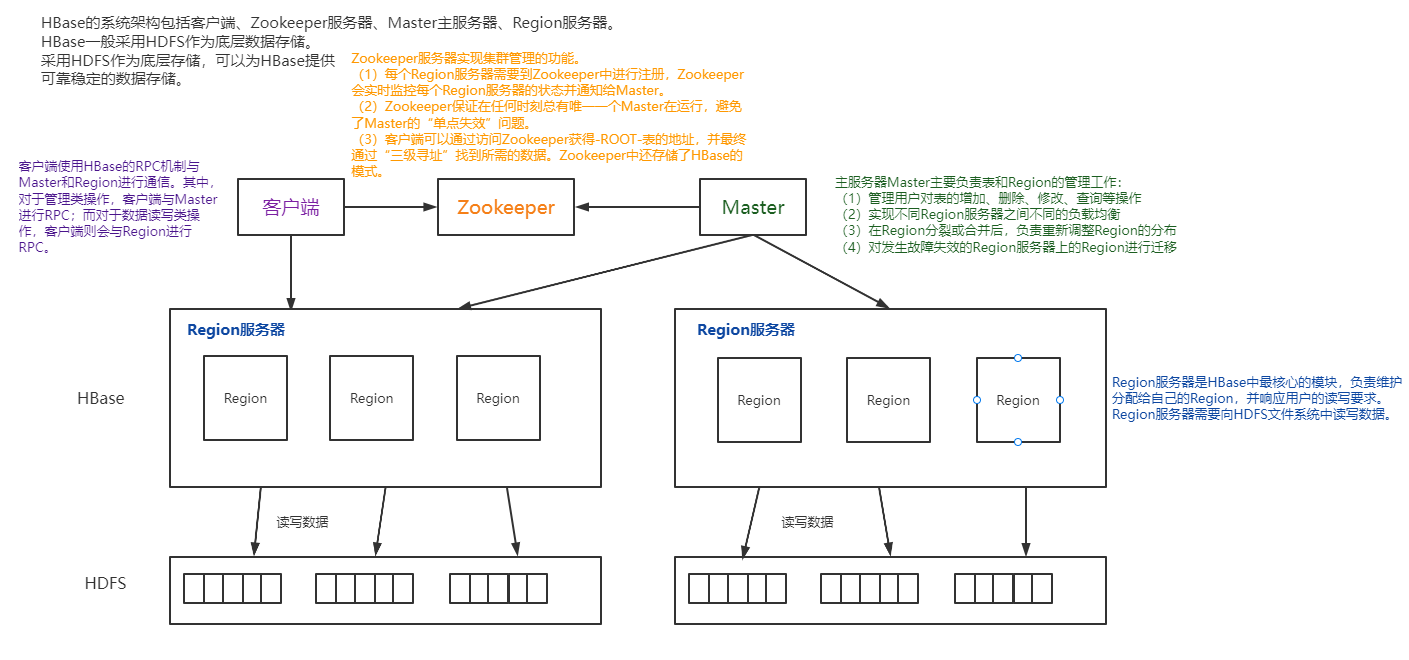
5.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 四者之间的相系关系
- 与HDFS的关联

 浙公网安备 33010602011771号
浙公网安备 33010602011771号