

redis数据结构及其使用场景、持久化、缓存淘汰策略
Redis 单线程高性能,它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能损耗问题。redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
1.Redis数据结构及简单操作指令、应用场景
String、list、set、hash、zset(有序set)
总体来说redis都是通过Key-Value的形式来存储数据的。只是不用数据类型Value的形式不同。
String:最简单数据结构,比如我们将一个对象转成json串来存储
set key value 存放数据
get key 获取数据
exists key 查看数据是否存在,存在返回1否则0
del key 删除数据 返回操作成功的条数
mset key1 value1 key2 value2 key3 value3...存放多组数据
mget key1 ke2y key3... 获取多个key的数据,返回一个集合,类似Map的values方法
expire key second 设置key 过期时间,单位秒
expire key second 设置key 过期时间,单位秒
setex key second value设置key 过期时间,单位秒(等价于先set,再expire)
setnx key value 如果key不存在就set 返回1.如果存在返回0(可以基于此实现分布式锁)
应用场景:
1.普通的单值存储key-value
2.分布式锁 setnx key value
3.计数器 incr key 原子加,比如统计文章的阅读量
4.分布式seesion
List:并不是java里面的list,redis的list更像一个链表或者说队列/栈的结构。这就意味着它的删除插入快,但是通过索引定位就比较慢了。当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收。
Redis 的列表结构可以来做异步队列使用。将需要延后处理的任务塞进 Redis 的列表,另一个线程从这个列表中轮询数据进行处理。list的索引有正向索引和反向所以,正向索引以0开始,反向索引以-1结束。
rpush key value1 value2 value3... 插入list数据
llen key 查看长度
lpop key 按加入顺序获取(先进先出,类似队列)
rpop key 后进先出,有点类似栈
lrange key start stop 查看此索引访问内的数据,可以使用正向索引或者反向索引,这个操作不会弹出数据。
blpop key timeout 从左边弹出一个元素如果没有则阻塞等待timeout秒,如果timeout=0表示一直阻塞等待
brpop key timeout 同上从右边弹出一个元素
列表取数据,使用pop取完后整个列表都被回收了,就是说只能取一次数据。
应用场景
1.常用数据结构模拟:
栈:lpush + lpop 后进先出
队列:lpush + rpop 先进先出
阻塞队列:lpush + brpop
2.订阅消息推送:A用户关注B公众号,B发布文章的时候就往一个关于A的key里面写入文章关键信息,lpush B:A:msg 文章ID,每次A进入订阅信息的时候:lrange B:A:msg 0 4 就可以看到最新的5条消息
3.
Hash:类似java的hashMap,和字符串相比,我们存储数据的时候可以只存储对象的部分属性,而字符串则需要完整将整个对象转换。当然hash存储结构的消耗肯定是高于字符串的,缺点只能对rediskey进行一些属性设置操作,不能操作设置里面hashkey,比如设置过期时间这些,只能是针对rediskey。
hset redisKey hashKey1 value1
hset redisKey hashKey2 value2 插入数据
hgetall redisKey 获取数据,key value间隔出现
hlen redisKey 查看hash长度
hget redisKey hashKey 获取hashKey 对应的value
hmset redisKey hashKey1 value1 hashKey2 value2 hashKey2 value3 批量插入值
应用场景
1.购物车实现:
添加商品:hset cart:用户ID 商品ID 数量
增加数量:hincrby cart:用户ID 商品ID 数量
商品总数:hlen cart:用户ID
删除商品:hdel cart:用户ID 商品ID
获取购物车所有商品:hgetall cart:用户ID
Set : 类似HashSet无序,
sadd key value
sadd key value1 value2 批量添加
smembers key 查看所有
sismember key value 查询某个值是否存在,存在返回1
scard key 查看大小
spop key 获取一个元素 最后一个数据取完之后,该结构会被清理,无法再次获取数据
srandmember key count 从集合中选出几个元素,此操作不会删除数据
sinter key... 交集运算,求出多个集合的交集
sinterstore newkey key... 将交集结果存入newkey中
sunion key... 求并集
sunionstore newkey key... 将并集结果存入新key中
sdiff key... 求差集
sdiffstore newkey key... 将差集结果存入新key中
应用场景
1.随机抽奖活动:将参与者放入set中,抽奖时如果可以重复参与一二三等奖,就用srandmember key count ,如果不能重复参与就世界pop出去。
2.红包瓜分,参考随机瓜分百万红包,这里面其实应该用set,文章中用的list,因为是在代码层面做了一次随机性。
3.微博的关注模型:可以使用set的交,并,差操作来实现。
Zset:带一个分值大小的set集合,基于大小排序的集合。
zadd key score value 往有序集合key中加入带分值score的元素
zrem key value 从有序集合key中删除元素
zscore key value 返回有序集合key中元素value的分值
zincrby key increment value 为有序集合key中元素value的分值加上increment
zcard key 返回有序集合key中元素个数
zrange key start stop 正序获取有序集合key从start下标到stop下标的元素(从小到大)
zrevrange key start stop 倒序获取有序集合key从start下标到stop下标的元素(从大到小)
zunionstore newkey numkeys key... 并集计算将多个key求并集 如果value一样的则会将score相加 得到一个新的zet,numkeys是后面集合数量
zinterstore newkey numkeys key... 交集计算,同样会将其score相加
应用场景:
1.排行榜,投票排名等需要排序的场景
2.一周排行数据汇总,zunionstore或者zinterstore
原子计数操作
如果value是整数的话还可以实现自增操作(也可以用于实现分布式锁,该增长有限,最大到long max,超过该值会直接报错)
incr key 自增 如果key不存在默认从0自增1
incrby key step 设置增加步长step
2.redis持久化
虽然说redis都是内存级别的操作,其实也是有持久化的。
一种是基于RDB快照,
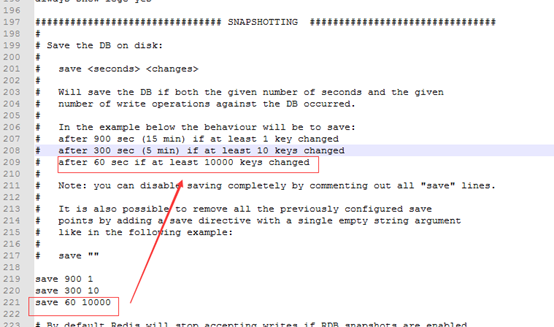
Redis 将内存数据库快照保存在名字为 dump.rdb 的二进制文件中。

可以对 Redis 进行设置, 让它在N 秒内数据集至少有 M 个改动这一条件被满足时, 自动保存一次数据集。
也可以执行sava或者bgsave指令手动生成快照。save是同步的会阻塞其他指令执行,bgsave是另起线程去生成快照,不会阻塞客户端指令。
另一种是AOF(append-only file)
快照并不可靠,上次快照之后,还未到达下一次快照条件时,这时候服务出现了问题,那么这期间的数据是无法保存到快照版本中的。这个时候就需要AOF了,它将每一条指令都记录进文件,当redis重启的时候,重新执行这个文件里面指令,就可以恢复所有的数据到内存中了。
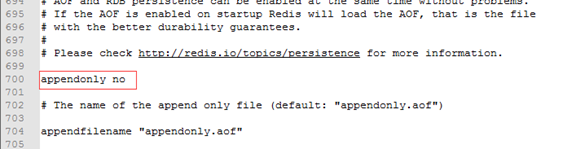
可以通过配置appendonly yes 来开启AOF,默认是关闭的
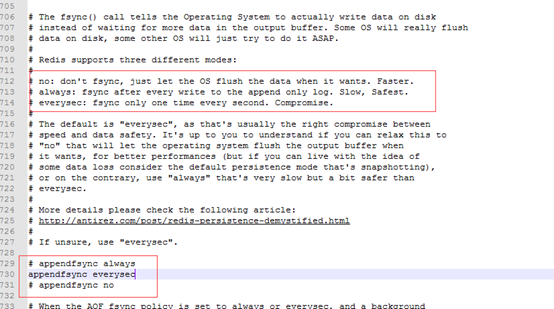
AOF也有三种同步数据的策略,
每次有操作都去刷新文件,很慢,但安全
每秒同步刷新一次:可能会丢失一秒内的数据
从不同步同步刷新:让操作系统在需要的时候刷新数据,不安全
默认的是每秒刷一次
这样一来可能AOF中有很多没用的记录,比如多次set 其实只有最后一次的数据才是有效的,前面全是无效的,保存下来,既占用磁盘,执行的时候也耗费时间,这个时候就有AOF重写。AOF重写是啥呢,其实就是整理我们的执行指令,前面那些本来会被覆盖的指令就不需要再记录了,只保留最后一次修改的指令就可以了,这样一来文件就可以小很多,既省了磁盘,后续恢复数据执行起来也快。
有两个参数:
混合持久化:
RDB快照数据恢复速度快,但是可能会有大量数据丢失,所以通常恢复数据还是用的AOF日志重放,但是AOF相对来说速度会很慢,尤其是在数据量大的时候。因此在4.0的时候带来了混合持久化,也就是AOF在刷新的时候,先记录上次的快照版本,然后记录上次快照版本到现在的增量操作,然后合并成一个文件,覆盖原来的appendonly.aof文件。Redis重启的时候,先加载RDB快照的内容,在重放AOF日志中增量操作的内容就可以了。
开启混合持久化:aof-use-rdb-preamble yes
混合持久化中appendonly.aof内容格式,一部分是RDB文件内容格式,另外的才是AOF文件的内容格式。
连接redis之后可以通过monitor指令监控输入的命令
3.缓存淘汰策略:
当 Redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换 。会让 Redis 的性能急剧下降,对于访问量比较频繁的 Redis 来说,这样存取效率基本上等于不可用。
在生产环境中我们是不允许 Redis 出现交换行为的,为了限制最大使用内存,Redis 提供了配置参数 maxmemory 来限制内存超出期望大小。
当实际内存超出 maxmemory 时,Redis 提供了几种可选策略 (maxmemory-policy) 来让用户自己决定该如何腾出新的空间以继续提供读写服务。
maxmemory <bytes> # MAXMEMORY POLICY: how Redis will select what to remove when maxmemory # is reached. You can select among five behaviors: # # volatile-lru -> Evict using approximated LRU among the keys with an expire set. # allkeys-lru -> Evict any key using approximated LRU. # volatile-lfu -> Evict using approximated LFU among the keys with an expire set. # allkeys-lfu -> Evict any key using approximated LFU. # volatile-random -> Remove a random key among the ones with an expire set. # allkeys-random -> Remove a random key, any key. # volatile-ttl -> Remove the key with the nearest expire time (minor TTL) # noeviction -> Don't evict anything, just return an error on write operations. # # LRU means Least Recently Used # LFU means Least Frequently Used # # Both LRU, LFU and volatile-ttl are implemented using approximated # randomized algorithms. # # Note: with any of the above policies, Redis will return an error on write # operations, when there are no suitable keys for eviction. # # At the date of writing these commands are: set setnx setex append # incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd # sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby # zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby # getset mset msetnx exec sort # # The default is: # # maxmemory-policy noeviction
noeviction 不会继续处理写请求 (del,read请求可以继续进行)。这样可以保证不会丢失数据,但是会让线上的写相关的业务不能持续进行。这是默认的淘汰策略。
volatile-lru 尝试淘汰设置了过期时间的 key,最少使用的 key 优先被淘汰。没有设置过期时间的 key 不会被淘汰,这样可以保证需要持久化的数据不会突然丢失。
volatile-ttl 跟上面一样,除了淘汰的策略不是 LRU,而是 key 的剩余寿命 ttl 的值,ttl 越小越优先被淘汰。
volatile-random 跟上面一样,不过淘汰的 key 是过期 key 集合中随机的 key。
allkeys-lru 区别于 volatile-lru,这个策略要淘汰的 key 对象是全体的 key 集合,而不只是过期的 key 集合。这意味着没有设置过期时间的 key 也会被淘汰。
allkeys-random 跟上面一样,不过淘汰的策略是随机的 key。
volatile-xxx 策略只会针对带过期时间的 key 进行淘汰,allkeys-xxx 策略会对所有的 key 进行淘汰。如果你只是拿 Redis 做缓存,那应该使用 allkeys-xxx,客户端写缓存时不必携带过期时间。如果你还想同时使用 Redis 的持久化功能,那就使用 volatile-xxx 策略,这样可以保留没有设置过期时间的 key,它们是永久的 key 不会被 LRU 算法淘汰。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号