【学习笔记】Python3-爬虫-xpath
1. 筛选人人影视,迅雷下载地址
//table//td//a[starts-with(@href ,"magnet")]/@href
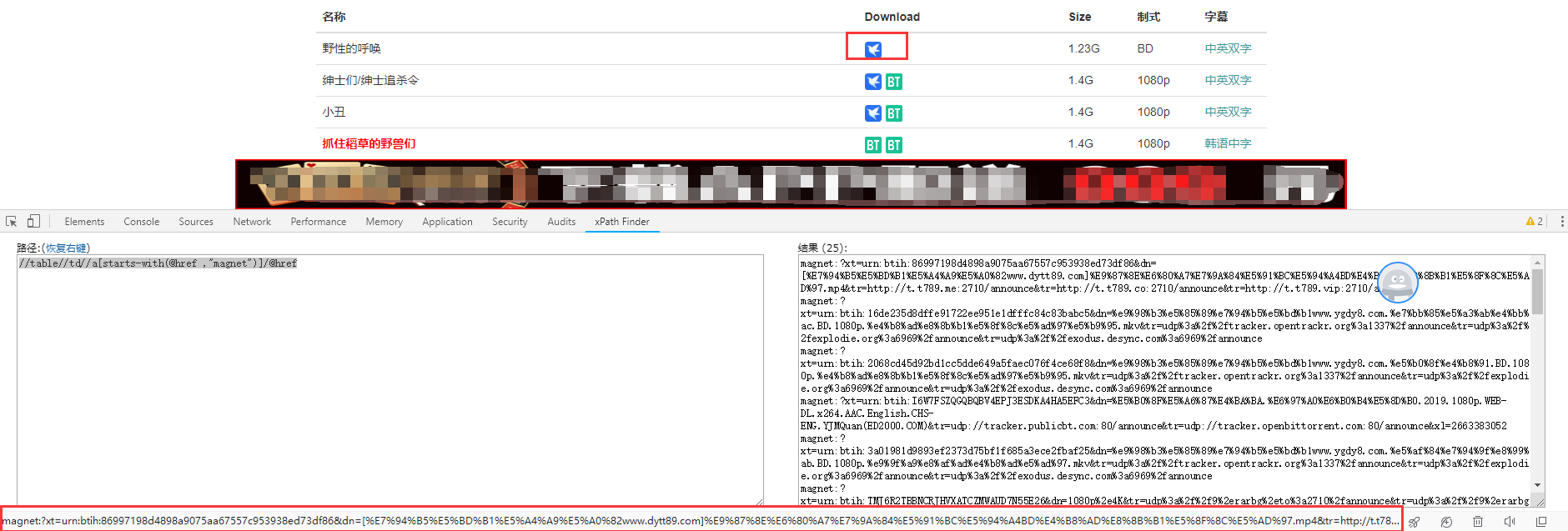
2.筛选人人影视页面所有下载地址
//table//td//a/@href

3. 筛选 页面标题
//table//td[1]/text()

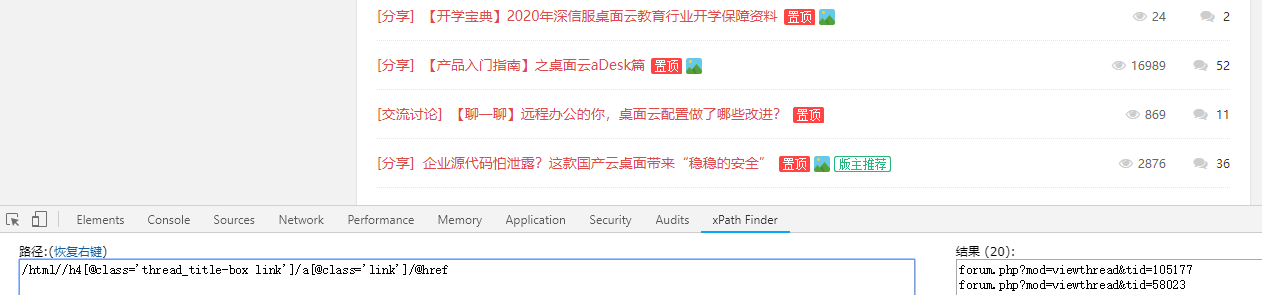
4.筛选深信服桌面云论坛
/html//h4[@class='thread_title-box link']/a[@class='link']/@href
5.看雪论坛
/html//a[@class='bbs_home_page_list_title']/@href

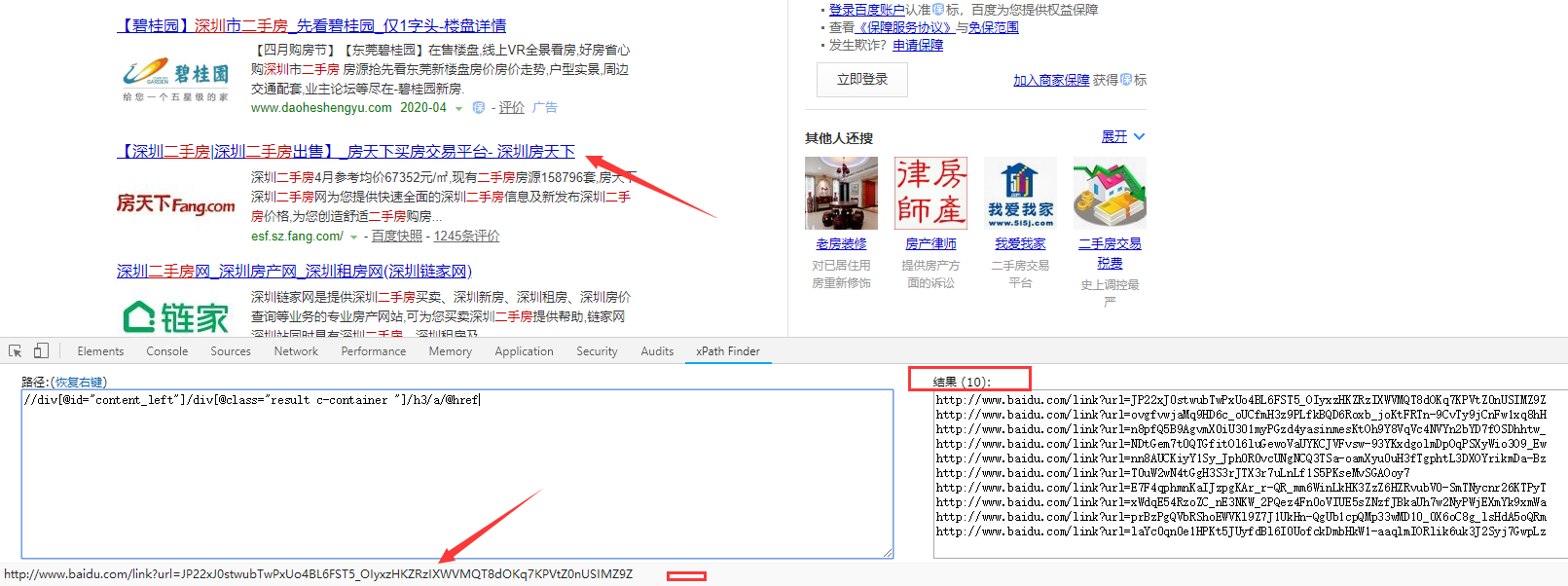
6.百度搜索结果筛选,去掉广告
//div[@id="content_left"]/div[@class="result c-container "]/h3/a/@href
广告的连接非常长,可以看出结果里面没有广告
7.360搜索,去除广告
在360浏览器里,这个xpath插件居然不好使了,嘿嘿嘿。。。..
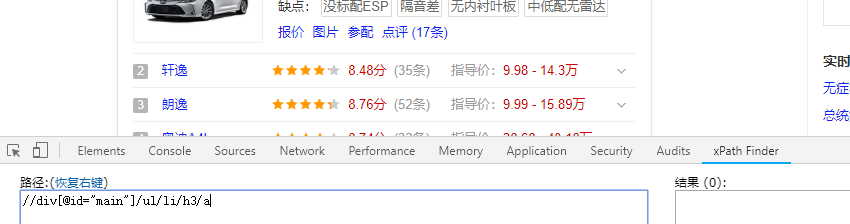
更换Google浏览器后,结果正常
//div[@id="main"]/ul/li/h3/a/@href

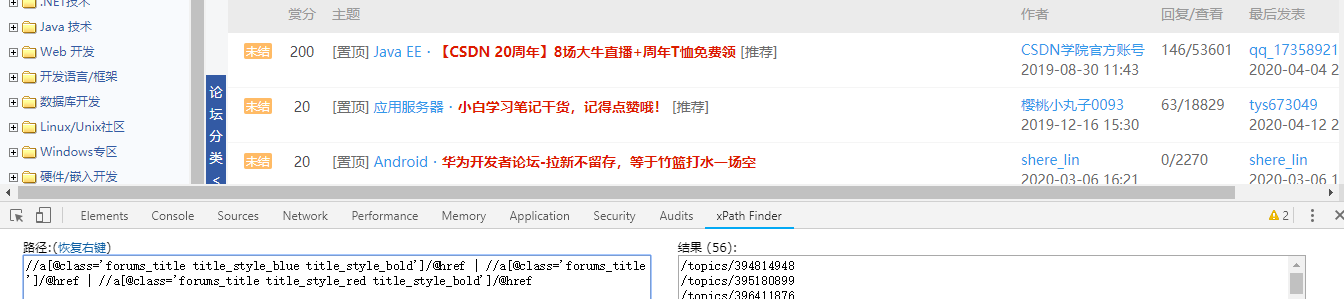
8.CSDN论坛帖子
//a[@class='forums_title title_style_blue title_style_bold']/@href | //a[@class='forums_title ']/@href | //a[@class='forums_title title_style_red title_style_bold']/@href
9. freebuf 文章
//div[@class='news-info']/dl/dt/a[1]/@href | //a[@class='article-title']/@href

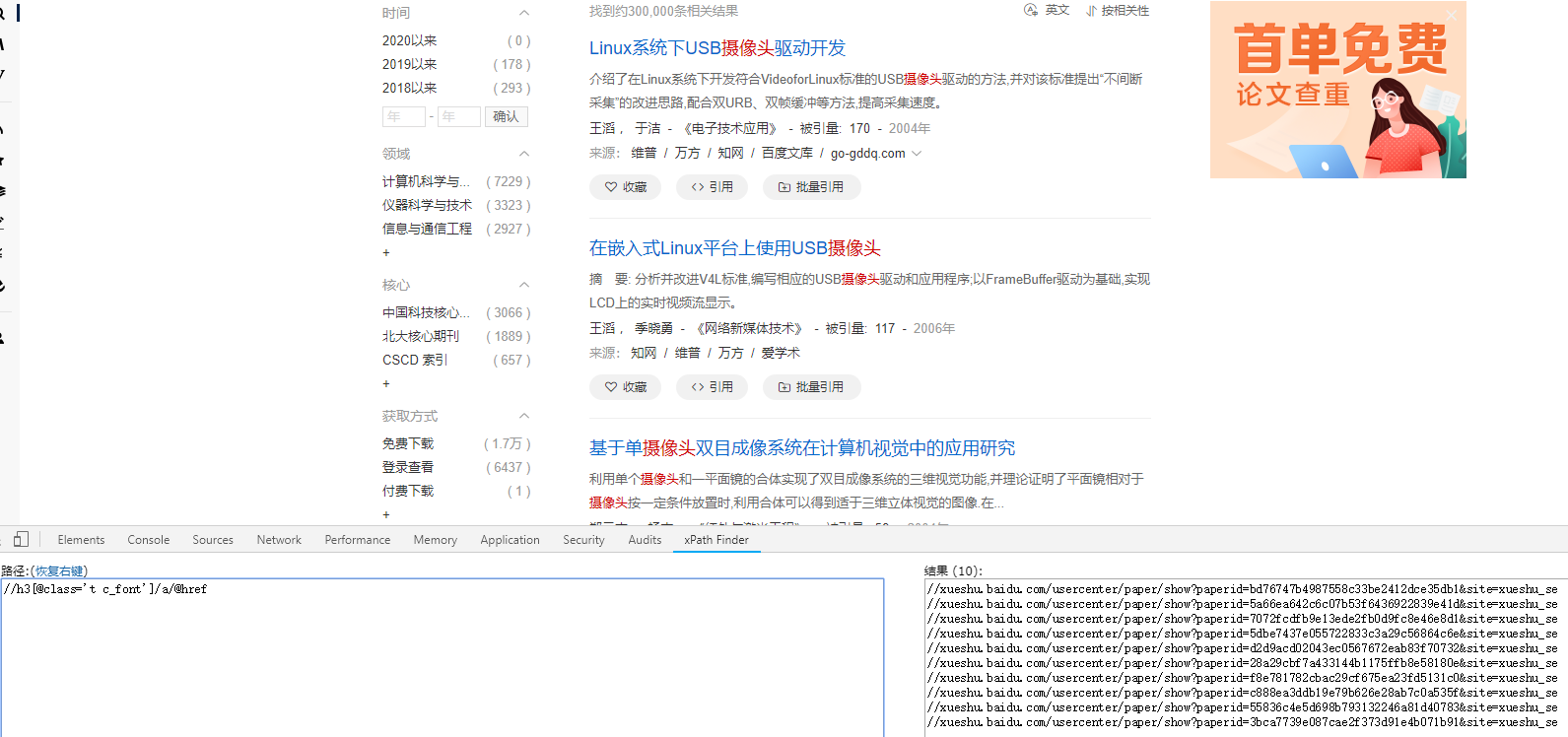
10. 百度学术
//h3[@class='t c_font']/a/@href
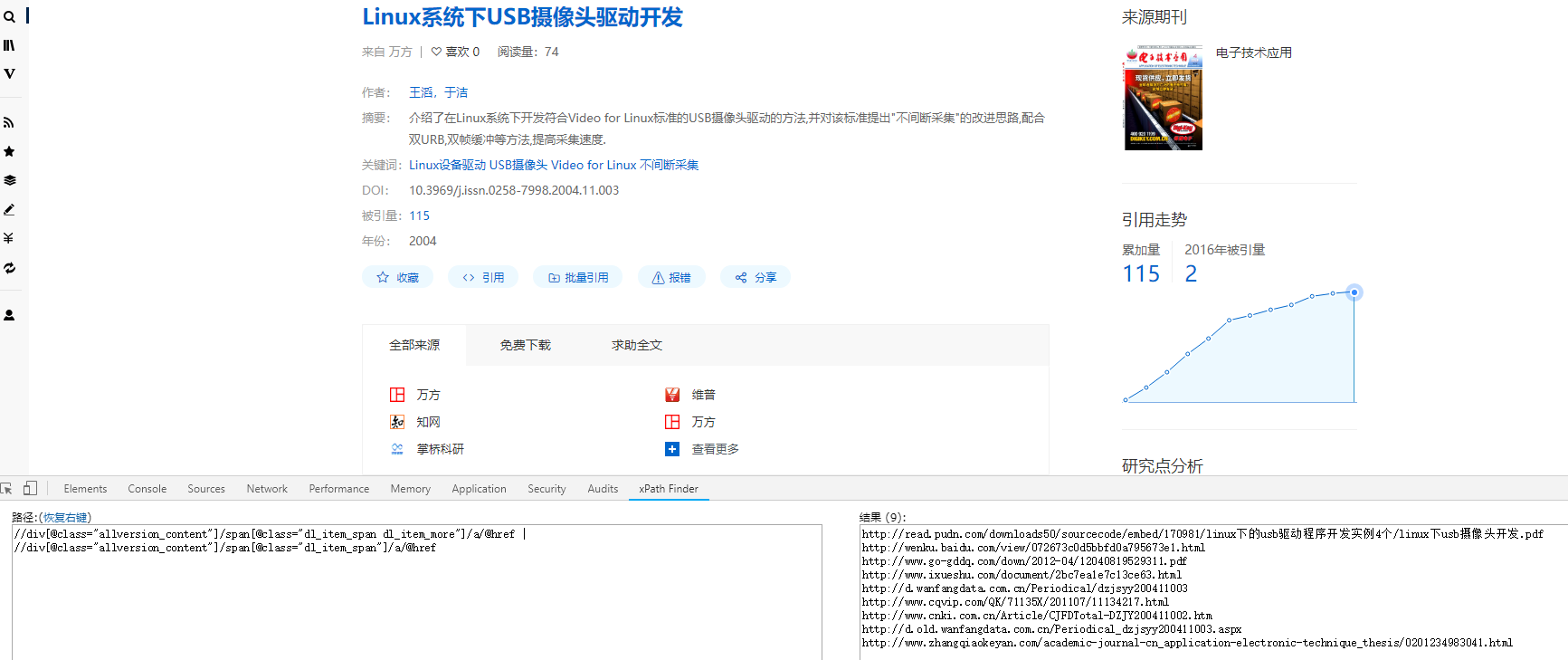
详情:
//div[@class="allversion_content"]/span[@class="dl_item_span dl_item_more"]/a/@href | //div[@class="allversion_content"]/span[@class="dl_item_span"]/a/@href
***************************** 2020-04-15 更新 ***********************************************

 浙公网安备 33010602011771号
浙公网安备 33010602011771号