文件的读写和我的第一个网页
一、文件读写的学习笔记
1、基本操作:
1 f = open('ex.txt','r+') #encoding参数可以指定文件的编码 2 print(f.readline()) #读一行 3 print(f.readlines())#读取所有文件内容,返回一个list,元素是每行的数据,大文件时不要用,因为会把文件内容都读到内存中,内存不够的话,会把内存撑爆 4 print(f.read()) #读取所有内容,大文件时不要用,因为会把文件内容都读到内存中,内存不够的话,会把内存撑爆 5 print(f.readable()) #判断文件是否可读 6 print(f.writable()) #判断文件是否可写 7 print(f.encoding) #打印文件的编码 8 print(f.tell()) #获取当前文件的指针指向 9 f.seek(0) #把当前文件指针指向哪 10 f.write('稻香') #写入内容 11 f.writelines(['稻香','周杰伦']) #将一个列表写入文件中 12 f.flush() #写入文件后,立即从内存中把数据写到磁盘中 13 f.truncate() #清空文件内容 14 f.close() #关闭文件
2、文件的打开模式:
‘r’ 只读模式。如果文件不存在,返回异常FileNotFoundError,默认值;
‘w’ 覆盖写模式,文件不存在则创建,存在则完全覆盖;
'x' 创建写模式,文件不存在则创建,存在则返回异常FileExistError;
‘a’ 追加写模式,文件不存在则创建,存在则在文件最后追加内容;
‘b’ 二进制文件模式;
‘t’ 文本文件模式,默认值;
'+' 与r/w/x/a一同使用,在原功能的基础上增加同事读写的功能
3、文件的指针:
f = open('ex.txt','a+') print('f.read',f.read())#读不到东西,因为a+模式指针默认指向文件末尾 f.seek(0) print('f.read',f.read())#加入seek(0)后可以读到 f.write('test') f.seek(0) print('f.read',f.read())#seek移动完文件指针后,是只能读,写的时候还是在文件末尾写
4、读取大文件的高效做法:
用上面的read()和readlines()方法操作文件的话,会先把文件所有内容读到内存中,这样的话,内存数据一多,非常卡,高效的操作,就是读一行操作一行,读过的内容就从内存中释放了。
import pandas as pd def xlsx_to_csv_pd(): data_xls = pd.read_excel('Python成绩.xlsx', index_col=0) data_xls.to_csv('1.csv', encoding='utf-8') if __name__ == '__main__': xlsx_to_csv_pd()
import pandas as pd def xlsx_to_csv_pd(): data_xls = pd.read_excel('Python成绩登记信计.xlsx', index_col=0) data_xls.to_csv('2.csv', encoding='utf-8') if __name__ == '__main__': xlsx_to_csv_pd()
更改其中数据:
fo=open("1.csv",'r') ls=[] for line in fo: line = line.replace('\n','').replace('优秀','90').replace('良好','80').replace('合格','60') ls = line.split(',') lns='' for s in ls: lns+="{}\t".format(s) print(lns)
fo=open("2.csv",'r',encoding='utf-8') ls=[] for line in fo: line = line.replace('\n','').replace('优秀','90').replace('良好','80').replace('不合格','0') line = line.replace('合格','60') ls = line.split(',') lns='' for s in ls: lns+="{}\t".format(s) print(lns)
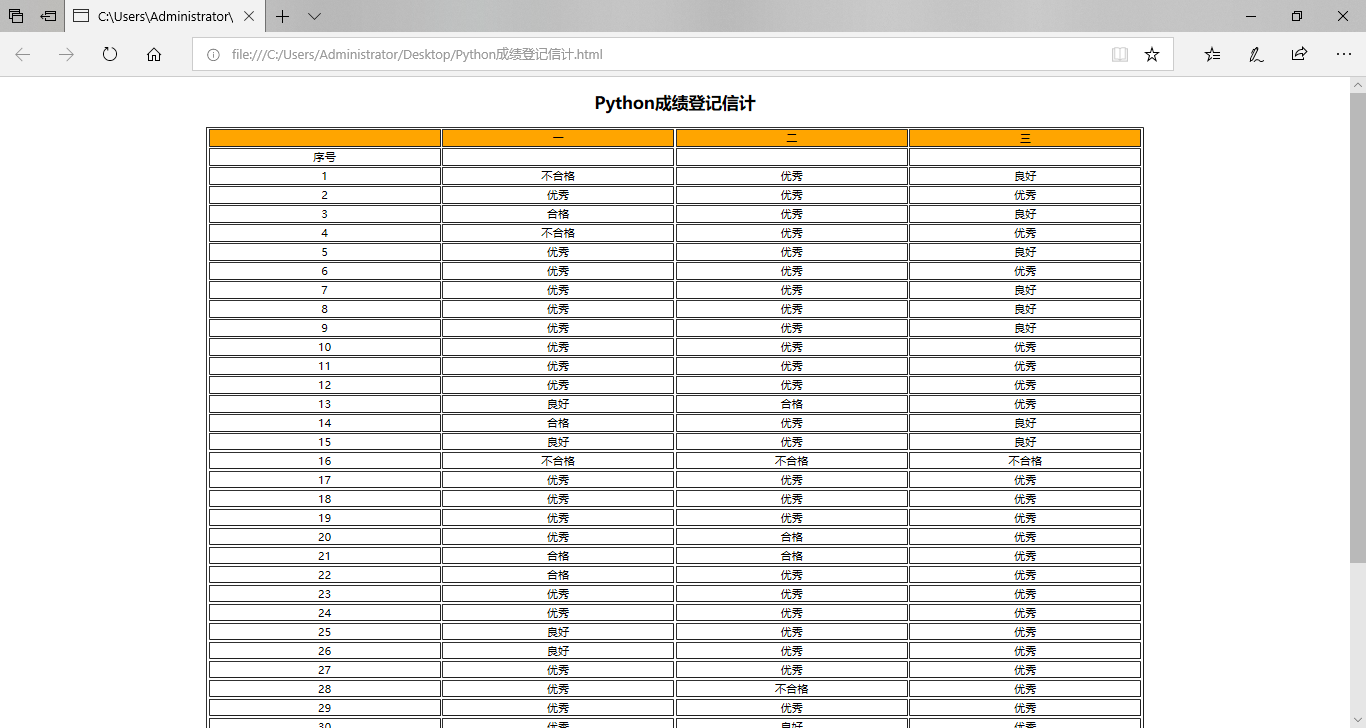
效果如图:


三、将 csv 文件转换为 html 文件:
seg1 = ''' <!DOCTYPE HTML>\n<html>\n<body>\n<meta charset=gb2312> <h2 align=center>Python成绩登记信计</h2> <table border='1' align="center" width=70%> <tr bgcolor='orange'>\n''' seg2 = "</tr>\n" seg3 = "</table>\n</body>\n</html>" def fill_data(locls): seg = '<tr><td align="center">{}</td><td align="center">{}</td><td align="center">{}</td><td align="center">{}</td></tr>\n'.format(*locls) return seg fr = open("2.csv", "r",encoding='utf-8') ls = [] for line in fr: line = line.replace("\n","") ls.append(line.split(",")) fr.close() fw = open("Python成绩登记信计.html", "w") fw.write(seg1) fw.write('<th width="25%">{}</th>\n<th width="25%">{}</th>\n<th width="25%">{}</th>\n<th width="25%">{}</th>\n'.format(*ls[0])) fw.write(seg2) for i in range(len(ls)-1): fw.write(fill_data(ls[i+1])) fw.write(seg3) fw.close()
运行程序后:
四、将 csv 文件用网页表示
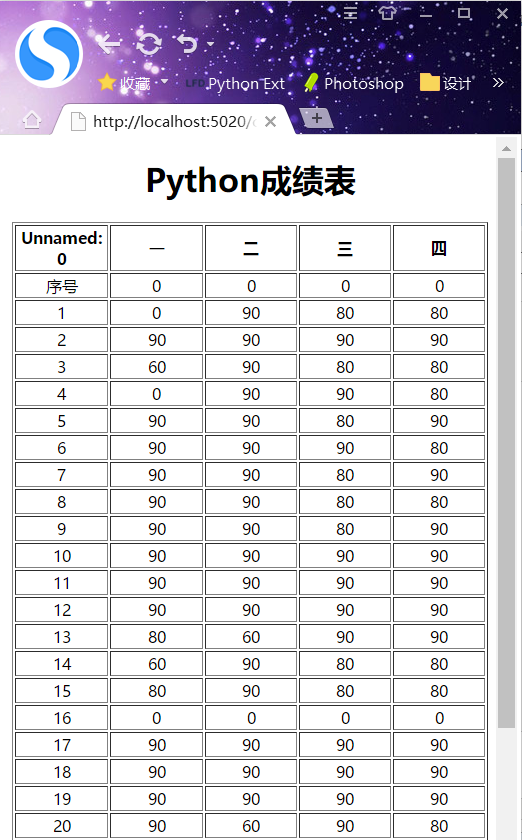
def fill_data(excel, length=4): text = '<tr>' for i in range(length): tmp = '<td align="center">{}</td>'.format(excel[i+1]) text += tmp text += "</tr>\n" return text def GetCsv(csvFile): ls = [] csv = open(csvFile, 'r', encoding="utf-8") for line in csv: line = line.replace('\n', '') ls.append(line.split(',')) return ls def CsvToHtml(csvFile, thNum): csv_list = GetCsv(csvFile) # 获得csv文件数据 print("Content-type:text/html\r\n\r\n") print(''' <!DOCTYPE HTML>\n<html>\n<body>\n<meta charset=gbk2313> <h1 align=center>Python成绩表</h2> <table border='blue'>\n''') # 写html文件首部 for i in range(1, thNum+1): # 写表格的表头(即第1行) print('<th width="20%">{}</th>'.format(csv_list[0][i])) print("</tr>\n") for i in range(1, len(csv_list)): # 写表格的数据,从第2行开始为数据 print(fill_data(csv_list[i], 5)) print("</table>\n</body>\n</html>") # 写html文件尾部 CsvToHtml("1.csv", 5)
结果为:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号