

JS
正则表达式全集
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“n”匹配字符“n”。“\n”匹配一个换行符。串行“\\”匹配“\”而“\(”则匹配“(”。 |
| ^ | 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“does”或“does”中的“do”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。 |
| . | 匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“(.|\n)”的模式。 |
| (pattern) | 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)”。 |
| (?:pattern) | 匹配pattern但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分是很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
| (?=pattern) | 正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 |
| (?<=pattern) | 反向肯定预查,与正向肯定预查类拟,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 |
| (?<!pattern) | 反向否定预查,与正向否定预查类拟,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。 |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”则匹配“zood”或“food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“p”。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
| \B | 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
| \d | 匹配一个数字字符。等价于[0-9]。 |
| \D | 匹配一个非数字字符。等价于[^0-9]。 |
| \f | 匹配一个换页符。等价于\x0c和\cL。 |
| \n | 匹配一个换行符。等价于\x0a和\cJ。 |
| \r | 匹配一个回车符。等价于\x0d和\cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于[^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于\x09和\cI。 |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK。 |
| \w | 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。 |
| \W | 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
| \xn | 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。. |
| \num | 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。 |
| \nml | 如果n为八进制数字(0-3),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
| \un | 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。 |
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
手机号:
/^1\d{10}$/
校验身份证
var checkCode = function (val) { var p = /^[1-9]\d{5}(18|19|20)\d{2}((0[1-9])|(1[0-2]))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$/; var factor = [ 7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2 ]; var parity = [ 1, 0, 'X', 9, 8, 7, 6, 5, 4, 3, 2 ]; var code = val.substring(17); if(p.test(val)) { var sum = 0; for(var i=0;i<17;i++) { sum += val[i]*factor[i]; } if(parity[sum % 11] == code.toUpperCase()) { return true; } } return false; } // 输出 true, 校验码相符 console.log(checkCode("11010519491231002X")); // 输出 false, 校验码不符 console.log(checkCode("110105194912310021"));
区分理解call,apply,bind
作用: call,apply,bind 都是改变this指向的
语法:
func.call(thisagr,param1,param1,...)
func.apply(thisagr,[param1,param1,...])
func.bind(thisagr,param1,param1,...)
1.call:
1.1 call第一个参数,就是要变成的this的对象
var obj = { name: 'psg' }; function fn(num1, num2) { console.log(num1 + num2); console.log("this指向:" + this, "num1:" + num1, "num2:" + num2) } fn(100, 200);//this指向window, num1=100, num2=200 fn.call(100, 200);////this指向100, num1=200, num2=undefined fn.call(obj, 100, 200);//this指向obj, num1=100, num2=200
1.2严格模式,非严格模式下的this指向
在非严格模式下:this为null,undefined时,this指向window 在严格模式下:传谁this就是谁,不传this就是undefined
// 严格模式 fn.call(); //this指向undefined fn.call(null); //this指向null fn.call(undefined); //this指向undefined
2.apply:
apply 于call 类似,只是不用于的语法
call传参数是逗号分割,一个一个传入:fn.call(obj,arg1,agr2)
apply传参数是用一个数组传:fn.apply(obj,[agr1,agr2])
var obj1 = { name: 'psg' }; function fn1(num1, num2) { console.log(num1 + num2); console.log("this指向:" + this, "num1:" + num1, "num2:" + num2) } fn1.call(obj1, 100, 200); fn1.apply(obj1, [100, 200]);
3.bind:
bind 于call类似,语法一致,但是bind体现了js的预处理
bind 不会执行函数,会有一个返回值(返回值是函数的拷贝)
预处理:实现把fn的this改变成我们想要的结果,并且把对象的参数也准备了,要用的时候,直接执行就行了
var obj1 = { name: 'psg' }; function fn1(num1, num2) { console.log(num1 + num2); console.log("this指向:" + this, "num1:" + num1, "num2:" + num2) } fn1.call(obj1, 100, 200); fn1.bind(obj1, 100, 200); //bind只是改变了fn中的this为obj,并且给fn传递了两个参数值,但是此时并没有给fn这个函数执行。 // 但是,执行bind会有一个返回值,这个返回值myFn就是我们把fn的this改变后的那个结果!!! var myFn = fn1.bind(obj1, 100, 200); myFn(); //执行函数
4.小结区别:
call于apply区别:
语法不同,传给函数的参数写法不同
call于bind区别:
1.执行:
call,apply改变了this执行,立马执行函数
bind 返回了this指向后的函数,没有执行函数
浏览器下载文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<script src="http://111.229.14.189/file/axios.min.js"></script>
</head>
<body>
<button id="downloadCustom">下载自定义内容</button>
<button id="downloadExcel">下载excel</button>
<button id="downloadPic">下载图片</button>
<script>
//提供一个链接用户下载内容
function download(link, name) {
if (!name) {
//如果没有提供名字,从给的Link中截取最后一坨
name = link.slice(link.lastIndexOf('/') + 1)
}
let eleLink = document.createElement('a')
eleLink.download = name
eleLink.style.display = 'none'
eleLink.href = link
document.body.appendChild(eleLink)
eleLink.click()
document.body.removeChild(eleLink)
}
function downloadFile(name, content) {
if (typeof name == 'undefined') {
throw new Error('The first parameter name is a must')
}
if (typeof content == 'undefined') {
throw new Error('The second parameter content is a must')
}
if (!(content instanceof Blob)) {
content = new Blob([content])
}
const link = URL.createObjectURL(content)
download(link, name)
}
function downloadByLink(link, fileName) {
axios
.request({
url: link,
responseType: 'blob'
})
.then((res) => {
const link = URL.createObjectURL(res.data)
download(link, fileName)
})
}
// 下载自定义的字符串
function downloadCustom() {
// 可以用来下载JSONString html等内容,只要是字符串都可以下载
const json = JSON.stringify({ name: 'xiaoming', age: 11 })
downloadFile('1.json', json)
}
//下载浏览器不会默认预览的文件,例如excel,word,ppt
function downloadExcel() {
download('http://111.229.14.189/file/1.xlsx')
}
// 下载浏览器会默认执行预览的文件,例如
function downloadPic() {
// 需要转发才可以,否则会有同源策略
downloadByLink('http://111.229.14.189/file/1.jpg')
}
;(function () {
document.getElementById(
'downloadCustom'
).onclick = downloadCustom
document.getElementById('downloadExcel').onclick = downloadExcel
document.getElementById('downloadPic').onclick = downloadPic
})()
</script>
</body>
</html>
防抖和节流
防抖(debounce)
所谓防抖,就是当事件触发了,在 n 秒内函数只能执行一次,如果在 n 秒内又触发了该事件,则重新计算函数时间。
// 防抖 function debounce(fn, delay) { let timer; return function (args) { let that = this; if (timer) clearTimeout(timer); timer = setTimeout(() => { fn.call(that, args); }, delay); } } // 这时候你在划 可以看到事件在停止滑动1s后才会输出 你不停滑动不会输出 (效果你的联想) let num = 1; document.body.onmousemove = debounce(function () { document.body.innerHTML = num ++ ; }, 1000);
节流(throttle)
所谓节流,就是随便触发事件,但是在 n 秒中只执行一次。
// 节流 function throttle(fn, delay) { let flag = true; return function (...args) { let that = this; if(!flag) return; flag = false; setTimeout(() => { fn.call(that, args); flag = true; }, delay); } } // 这时候你不停地划 可以看到事件每隔1s输出一次 let num = 1; document.body.onmousemove = throttle(function () { document.body.innerHTML = num ++ ; }, 1000)
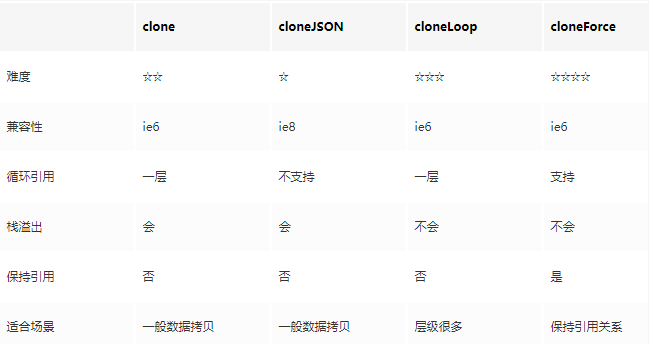
深拷贝
一行代码的深拷贝:
function cloneJSON(source) { return JSON.parse(JSON.stringify(source)); }
举个例子,假设有如下的数据结构
var a = { a1: 1, a2: { b1: 1, b2: { c1: 1 } } }
这不就是一个树吗,其实只要把数据横过来看就非常明显了。
a / \ a1 a2 | / \ 1 b1 b2 | | 1 c1 | 1
用循环遍历一棵树,需要借助一个栈,当栈为空时就遍历完了,栈里面存储下一个需要拷贝的节点
首先我们往栈里放入种子数据,key用来存储放哪一个父元素的那一个子元素拷贝对象
然后遍历当前节点下的子元素,如果是对象就放到栈里,否则直接拷贝
function cloneLoop(x) { const root = {}; // 栈 const loopList = [ { parent: root, key: undefined, data: x, } ]; while(loopList.length) { // 深度优先 const node = loopList.pop(); const parent = node.parent; const key = node.key; const data = node.data; // 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素 let res = parent; if (typeof key !== 'undefined') { res = parent[key] = {}; } for(let k in data) { if (data.hasOwnProperty(k)) { if (typeof data[k] === 'object') { // 下一次循环 loopList.push({ parent: res, key: k, data: data[k], }); } else { res[k] = data[k]; } } } } return root; }
存在的问题:假如一个对象a,a下面的两个键值都引用同一个对象b,经过深拷贝后,a的两个键值会丢失引用关系,从而变成两个不同的对象。
var b = {}; var a = {a1: b, a2: b}; a.a1 === a.a2 // true var c = clone(a); c.a1 === c.a2 // false
如果我们发现个新对象就把这个对象和他的拷贝存下来,每次拷贝对象前,都先看一下这个对象是不是已经拷贝过了,如果拷贝过了,就不需要拷贝了,直接用原来的,这样我们就能够保留引用关系了,✧(≖ ◡ ≖✿)嘿嘿
但是代码怎么写呢,o(╯□╰)o,别急往下看,其实和循环的代码大体一样,不一样的地方我用// ==========标注出来了
引入一个数组uniqueList用来存储已经拷贝的数组,每次循环遍历时,先判断对象是否在uniqueList中了,如果在的话就不执行拷贝逻辑了
find是抽象的一个函数,其实就是遍历uniqueList
// 保持引用关系 function cloneForce(x) { // ============= const uniqueList = []; // 用来去重 // ============= let root = {}; // 循环数组 const loopList = [ { parent: root, key: undefined, data: x, } ]; while(loopList.length) { // 深度优先 const node = loopList.pop(); const parent = node.parent; const key = node.key; const data = node.data; // 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素 let res = parent; if (typeof key !== 'undefined') { res = parent[key] = {}; } // ============= // 数据已经存在 let uniqueData = find(uniqueList, data); if (uniqueData) { parent[key] = uniqueData.target; continue; // 中断本次循环 } // 数据不存在 // 保存源数据,在拷贝数据中对应的引用 uniqueList.push({ source: data, target: res, }); // ============= for(let k in data) { if (data.hasOwnProperty(k)) { if (typeof data[k] === 'object') { // 下一次循环 loopList.push({ parent: res, key: k, data: data[k], }); } else { res[k] = data[k]; } } } } return root; } function find(arr, item) { for(let i = 0; i < arr.length; i++) { if (arr[i].source === item) { return arr[i]; } } return null; }
性能对比:
JS高级
1、基本数据类型和引用类型
var b1 = { // 对象类型 b2: [1, 'abc', console.log], b3: function () { console.log('b3') return function () { return 'xfzhang' } } } console.log(b1 instanceof Object, b1 instanceof Array) // true false console.log(b1.b2 instanceof Array, b1.b2 instanceof Object) // true true console.log(b1.b3 instanceof Function, b1.b3 instanceof Object) // true true console.log(typeof b1.b3 === 'function') // true console.log(typeof b1.b2[2] === 'function') // true b1.b2[2](4) // 4 console.log(b1.b3()()) // xfzhang
1. undefined与null的区别?
undefined代表定义未赋值;null定义并赋值,只是值为null。

2. 什么时候给变量赋值为null呢?
初始赋值,表明将要赋值为对象;结束前,让对象成为垃圾对象(被垃圾回收器回收)。初始化赋值:将要作为引用变量使用, 但对象还没有确定。结束时:将变量指向的对象成为垃圾对象。
var a = null // a将指向一个对象,但对象此时还没有确定
a = null // 让a指向的对象成为垃圾对象
3. 严格区别变量类型与数据类型?
js的变量本身是没有类型的,变量的类型实际上是变量内存中数据的类型(js是弱类型的语言)。var a; 判断变量类型,实际上 是判断值的类型。
数据的类型(数据对象):
* 基本类型
* 对象类型
变量的类型(变量内存值的类型):
* 基本类型:保存基本类型的数据(保存基本类型数据的变量)。
* 引用类型:保存对象地址值(保存对象地址值的变量)。
数据 变量 类型
什么是数据:
存储在内存中代表特定信息,本质上是0101。。。
特点:可传递,可运算(一切皆数据,内存中所有操作的目标:数据)
什么是内存:
内存条通电以后产生的可存储数据的空间(临时的)
内存产生和死亡:内存条(电路板)==》通电==》产生内存==》存储数据==》处理数据==》断电==》内存空间和数据都消失
一块小内存的2个数据(内部存储的数据+地址值)
问题:var a = XXX,a内存中到底保存的是什么? XXX是基本数据,保存的就是这个数据; XXX是对象,保存的是对象的地址值
XXX是变量,保存的是XXX的内存内容(可能是基本数据,也可能是地址值)
内存的分类:
栈:全局变量/局部变量
堆:对象
什么是变量:
可以变化的量,由变量名和变量值组成
每个变量都对应一个小内存,变量名用来查找对应的内存,变量值就是内存中保存的数据
内存,数据和变量的区别:
内存:用来存储数据的空间,变量是内存的标识
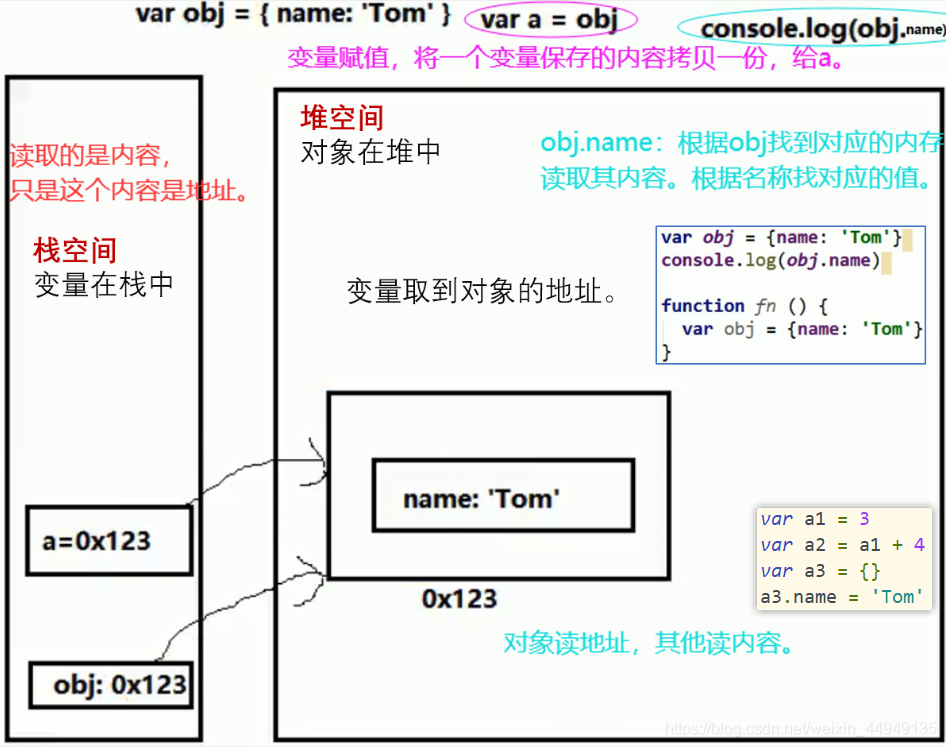
引用变量赋值的问题:
2个引用变量指向同一个对象,通过一个变量修改对象内部数据,另一个变量看到的是修改后的数据
2个引用变量指向同一个对象,让其中一个引用变量指向另一个对象,另一个引用变量依然指向前一个对象
var a = {age:12} var b = a a = {name:'BOB',age:18} console.log(b.age,a.name,a.age) //12, BOB,18 function fn(obj){ obj = {age:19} } fn(a) // 1、将a的内容赋值给obj 2、函数体里面给obj重新赋值,obj指向了新的对象,此时不影响a的内存值 console.log(a.age) //18
js调用函数时,是值传递还是引用传递:
理解1:都是值(基本/地址值)传递
理解2:可能是值传递,也可能是引用传递(地址值)
var a = 1 function fn(a){ a = a+1 } fn(a) //拿到1,赋值给fn里面的参数a console.log(a) //1
JS引擎如何管理内存:
1、内存生命周期
分配小空间,得到他的使用权
存储数据,可以反复进行操作
释放小内存空间
2、释放内存
局部变量:函数执行完自动释放
对象:成为垃圾对象==》垃圾回收器回收
function fn(){ obj = {} } fn() //obj是自动释放,obj所指向的对象是在后面的某个时刻由垃圾回收器回收
对象
什么是对象:多个数据的封装体;用来保存多个数据的容器;一个对象代表现实事件中的一个事物
为什么要用对象:管理多个数据
对象的组成:1、属性:属性名(字符串)和属性值组成;2、方法:一种特殊的属性(属性值是函数)
如何访问对象内部的数据:.属性名 or ["属性名"]
什么时候必须使用["属性名"]:属性名包含了特殊字符:- 空格;属性名不确定
函数
函数的调用:
直接调用 fn()
通过对象调用 obj.fn()
new 调用:new fn()
fn.call/apply(obj):临时让fn成为obj的方法进行调用
var obj = {} function fn(){ this.xxx = "nielifang" } fn.call(obj) // 可以让一个函数成为指定任意对象的方法进行调用 console.log(obj.xxx) // nielifang
回调函数
什么是回调函数:定义了,没有调用,但是最终执行了
函数的this
任何函数本质上都是通过某个对象来调用的(如果没有指定就是window),所有函数内部都有一个变量this,他的值是调用函数的当前对象
补充:js语句的后面加不加分号:
是否加分号是编码风格的问题,没有应不应该,只有喜不喜欢
但是下面2种情况不加分号会有问题:小括号开头的前一条语句;中方括号开头的前一天语句
函数高级:
原型与原型链
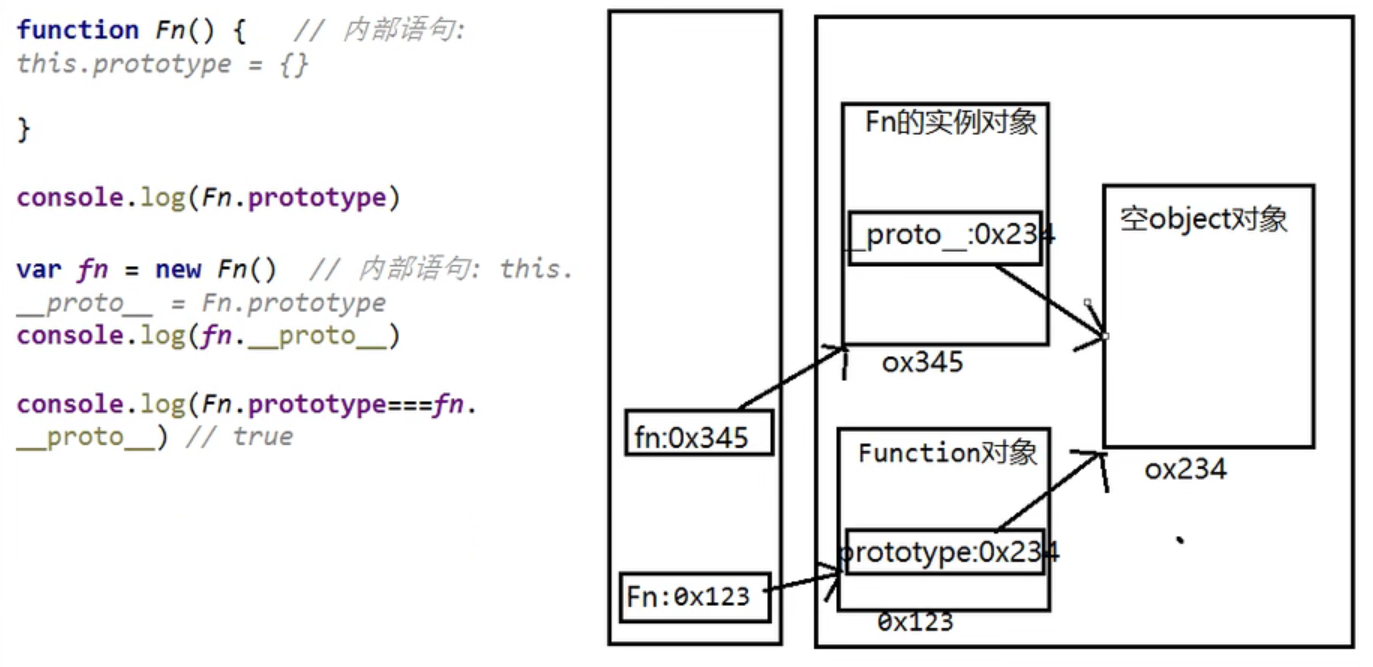
1、函数的prototype属性:
每个函数都有一个prototype属性,他默认指向一个object的空对象
原型对象中有一个属性constructor,他指向函数对象
2、给原型对象添加属性
作用:函数的所有实例对象自动拥有原型中的属性(方法)
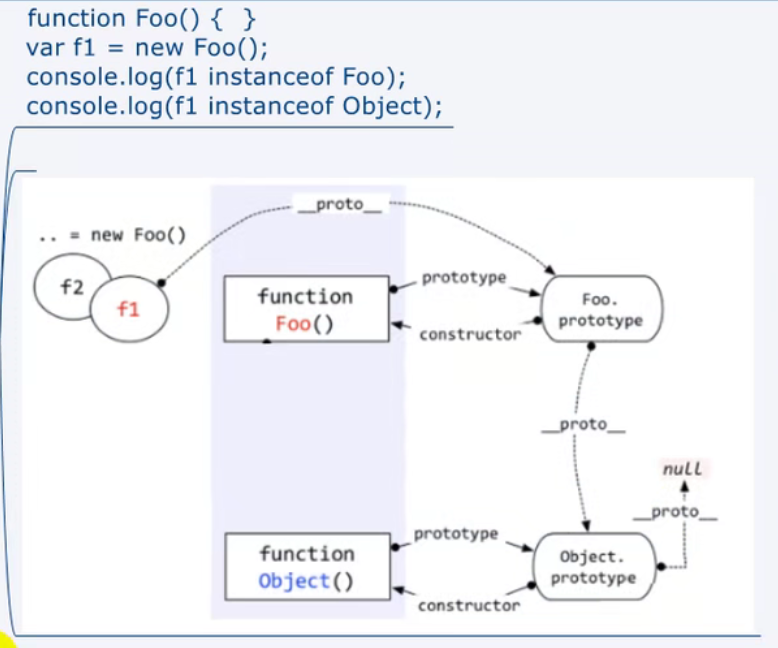
显式原型与隐式原型
1、每个函数function都有一个prototype,即显式原型
2、每个实例对象都有一个__proto__,可称为隐式原型
3、对象的隐式原型的值为其对应构造函数的显式原型的值 (var fn = new Fn() Fn.prototype === fn.__proto__)
总结:
函数的prototype属性:在定义函数时自动添加,默认值是一个空的object对象
对象的__proto__属性:创建对象时自动添加的,默认值是构造函数的prototype属性值
可以直接操作显式原型,但不能直接操作隐式原型(es6之前)
原型链
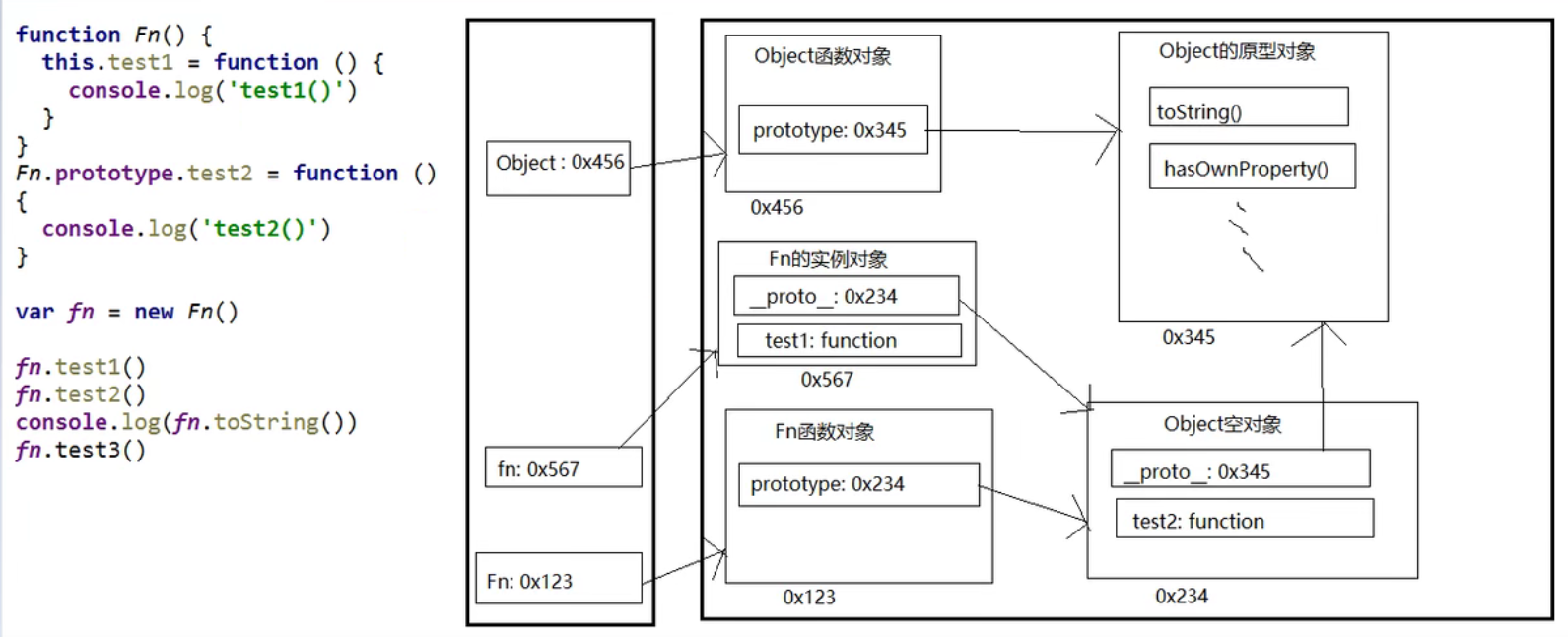
访问一个对象的属性时,先在自身属性中找,找到返回;如果没有,沿着__proto__这条链往上找,找到返回;如果最终没有找到,返回undefined。
别名:隐式原型链
作用:查找对象的属性
补充:
函数的显示原型指向的对象:默认是空的object实例对象()
所有函数都是Function的实例,包括Function本身(Function.__proto__ === Function.prototype)
Object的原型对象是原型链的尽头(Object.prototype.__proto__ === null)
原型链的属性
读取对象的属性值时,会自动到原型链中查找
设置对象的属性值时,不会查找原型链,如果当前对象中没有此属性,直接添加此属性并设置其值
方法一般定义在原型中,属性一般通过构造函数定义在对象本身上
instanceof
A(实例对象) instanceof B(构造函数)
如果B函数的显示原型对象在A对象的原型链上,返回true (A.__proto__ === B.prototype)
Function通过new 自己 来产生的实例
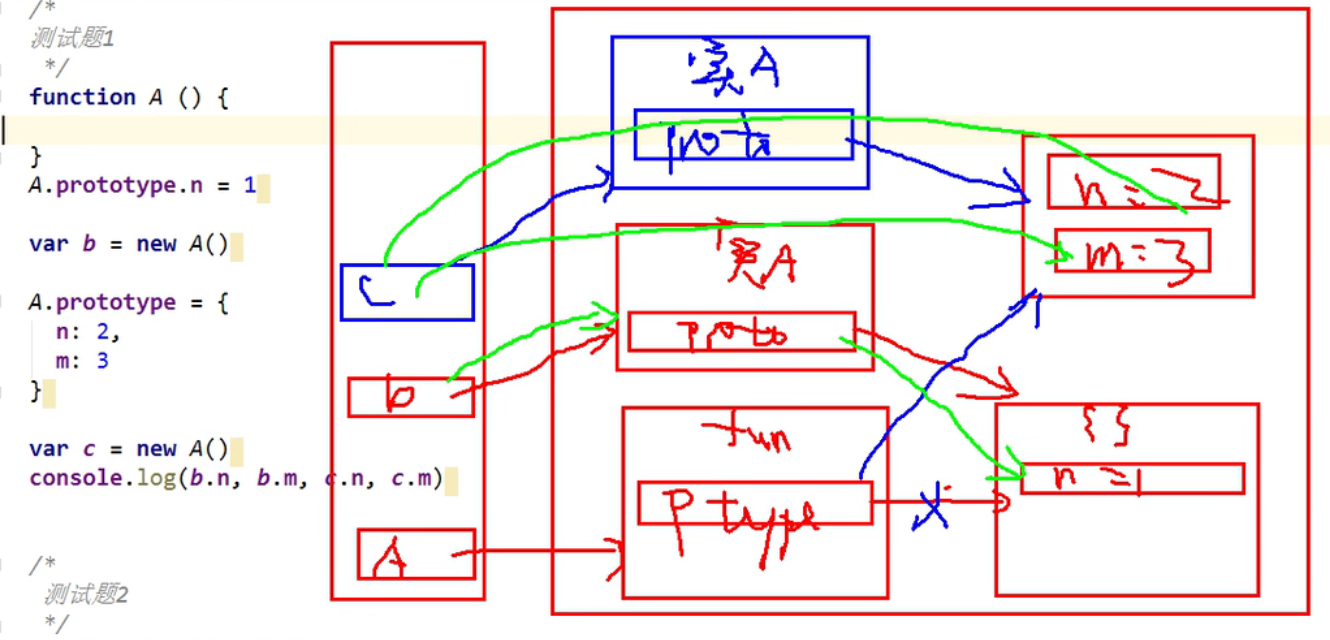
测试题
执行上下文与执行上下文栈
变量提升与函数提升
1、变量声明提升:通过var声明的变量,在定义语句之前就可以调用,返回的值是undefined
2、函数声明提升:通过function声明的函数,在之前就可以调用,值是函数定义(对象)
3、问题:变量提升和函数提升是如何产生的?
执行上下文
代码分类:全局代码和函数代码(位置)
全局执行上下文:
1、在执行全局代码前将window确定为全局执行上下文
2、对全局数据进行预处理:
1、对var声明的全局变量 ==》undefined,添加为window属性
2、function声明的全局函数==》赋值为fun,添加为window的方法
3、this赋值为window
3、开始执行全局代码
函数执行上下文:
1、在调用函数,准备执行函数体之前,创建对应的函数执行上下文对象(虚拟的,存在于栈中);
2、对局部数据进行预处理
形参变量==》赋值(实参)==》添加为执行上下文的属性
arguments==》赋值(实参列表),添加为执行上下文的属性
对var定义的局部变量 ==》undefined,添加为执行上下文的属性
funciton声明的函数==》赋值为fun,添加为执行上下文的方法
this==》赋值(调用函数的对象)
3、开始执行函数体代码
执行上下文栈(后进先出)
1、 在全局代码执行前,JS引擎会创建一个栈来管理所有的执行上下文对象;
2、在全局执行上下文(window)确定后,将其添加到栈中(压栈);
3、在函数执行上下文创建后,将其添加到栈中(压栈);
4、在当前函数执行完后,将栈顶的对象移除(出栈);
5、当所有的代码执行完后,栈中只剩下window
面试题:
执行结果:
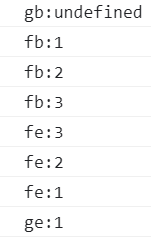
整个过程产生了几个执行上下文:
5个( f(4) \ f(3) \ f(2) \ f(1) \ window)
console.log('gb:'+i)
var i = 1
foo(1)
function foo(i){
if(i === 4){
return
}
console.log('fb:' + i)
foo(i+1)
console.log("fe:" + i)
}
console.log("ge:" + i)
测试1:先执行变量提升,再执行函数提升
function a(){} var a console.log(typeof(a)) // "function"
变形:
function a(){} var a = 10 console.log(typeof(a)) //"number"
测试2:b in window 返回true
if(! (b in window)){ var b = 1 } console.log(b) // undefined
测试3:
var c = 1 function c(c){ console.log(c) }
c(2) // c is not a function
作用域与作用域链
理解:就是一块“地盘”,一个代码段所在的区域;是静态的,在编写代码的时候就确定了,后面不会变
分类:全局作用域、函数作用域、块作用域
作用:隔离变量,不同作用域下同名变量不会有冲突
作用域链:多个上下级关系的作用域形成的链,他的方向是从内到外的;查找变量时就是沿着作用域链来查找的
测试题:
var x = 10; function fn(){ console.log(x) } function show(f){ var x = 20; f() } show(fn) // 10
闭包
产生:当一个嵌套的内部函数引用了嵌套的外部函数的变量时,就产生了闭包
闭包存在与嵌套的内部函数中
闭包产生的条件:
1、函数嵌套
2、内部函数引用了外部函数的数据
function fn1(){ var a = 2 function fn2(){ console.log(a) } } fn1()
常见的闭包:
1、将函数作为另一个函数的返回值
function fn1(){
//此时闭包已经产生(因为函数提升,内部函数对象已经创建了) var a = 2 function fn2(){ a++ console.log(a) } return fn2 } var f = fn1() f() //3 f() //4
//总共产生了一次闭包,调用了2次内部函数;产生几次闭包主要看调用了几次外部函数
f = null //闭包死亡(包含闭包的函数对象成为垃圾对象)
2、将函数作为实参传递给另一个函数调用
function showDelay(msg,time){ setTimeout(function(){ alert(msg) },time) } showDelay("nielifang",2000)
闭包的作用:
1、使用函数内部的变量在函数执行完后,仍然存活在内存中(延长了局部变量的生命周期)
2、让函数外部可以操作(读写)函数内部的数据
问题:函数执行结束之后,函数内部声明的局部变量是否还存在?
答:一般是不存在的,存在与闭包中的变量才可能存在
在函数外部能直接访问函数内部的局部变量吗?
答:不能。但我们可以通过闭包让外部操作他
闭包的生命周期:
产生:在嵌套内部函数定义执行完时就产生了(不是调用时产生)
死亡:当嵌套内部函数成为垃圾对象
闭包的应用:自定义js模块
1、具有特定功能的js模块
2、将所有的数据和功能都封装在一个函数里(私有的)
3、只向外暴露一个包含n个方法的对象或函数
4、模块的使用者,只需要通过模块暴露的对象调用方法来实现对应的功能
myMoudle.js文件
(functio (window){ // 私有属性 var msg = "nielifang" function doSomething(){ console.log("dosomething()",msg.toUpperCase()) }, function doOtherthing(){ console.log("doOtherthing()",msg.toLowerCase()) } window.module = {doSomething:doSomething, doOtherthing:doOtherthing} //return {doSomething:doSomething,doOtherthing:doOtherthing} })(window)
闭包的缺点:
1、函数执行结束后,函数内的局部变量没有释放,占用内存时间会变长
2、容易造成内存泄漏
解决:
能不用闭包就不用;及时释放(f = null,让内部函数成为垃圾对象)
测试题:
function fun(n,o){ console.log(o) return { fun:function(m){ return fun(m,n) } } } var a = fun(0) a.fun(1) //0 a.fun(2) //0 a.fun(3) //0 var b = fun(0).fun(1).fun(2).fun(3) //undefined,0,1,2 var c = fun(0).fun(1) c.fun(2) c.fun(3) //undefined,0,1,1
内存溢出与内存泄漏
内存溢出:
一种程序运行出现的错误;当程序运行需要的内存超过了剩余的内存时,就抛出内存溢出的错误
内存泄漏:
占用的内存没有及时释放;
内存泄漏积累多了就容易导致内存溢出;
常见的内存泄漏:
意外的全局变量
没有及时清理的计时器或回调函数
闭包
测试题:
var name2 = "The Window" var Object2 = { name2:'My Object', getNameFunc:function(){ return function(){ return this.name2 //function中的this指的是window } } } alert(Object2.getNameFunc()()) // The Window
var name1 = "The Window" var Object1 = { name1:'My Object', getNameFunc:function(){ var that = this; //this指的是调用者object1 return function(){ return that.name1 } } } alert(Object1.getNameFunc()()) // My Object
对象创建模式
工厂模式(每次运行都能return出一个新的对象):
套路:通过工厂函数动态创建对象并返回
适用场景:需要创建多个对象
问题:对象没有一个具体的类型,都是object类型
function createPerson(name,age){ var obj = { name:name, age:age, setName:function(){ this.name = name } } return obj
} //创建2个人 var p1 = createPerson("TOM",12) var p2 = createPerson("BOB",13)
自定义构造函数模式
套路:自定义构造函数,通过new创建对象
适用场景:需要创建多个类型确定的对象
问题:每个对象都有相同的数据,浪费内存
function Person(name,age){ this.name = name this.age = age this.setName = function(name){ this.name = name } } var p = new Person("TOM",12) console.log(p instanceof Person) function Student(name,price){ this.name = name this.price = price } var s = new Student("Jack",13000) console.log(s instanceof Student)
构造函数+原型的组合模式
套路:自定义构造函数,属性在函数中初始化,方法添加到原型上
适用场景:需要创建多个类型确定的对象
function Person(name,age){ this.name = name this.age = age } Person.prototype.setName = function(name){ this.name = name } var p1 = new Person("TOM",12) var p2 = new Person("JACK",13)
原型链继承
1、原型链继承
套路:定义父类型构造函数;给父类型的原型添加方法;定义子类型的构造函数;创建父类型的对象赋值给子类型的原型;
将子类型原型的构造属性设置为子类型;给子类型原型添加方法;创建子类型的对象:可以调用父类型的方法
关键:子类型的原型为父类型的一个实例对象
// 父类型 function Supper(){ this.supProp = 'Supper property' } Supper.prototype.showSupperProp = function(){ console.log(this.supProp); } // 子类型 function Sub(){ this.subProp = "Sub property" } //子类型的原型为父类型的一个实例对象 Sub.prototype = new Supper() Sub.prototype.showSubProp = function(){ console.log(this.subProp); } var sub = new Sub() sub.showSupperProp()
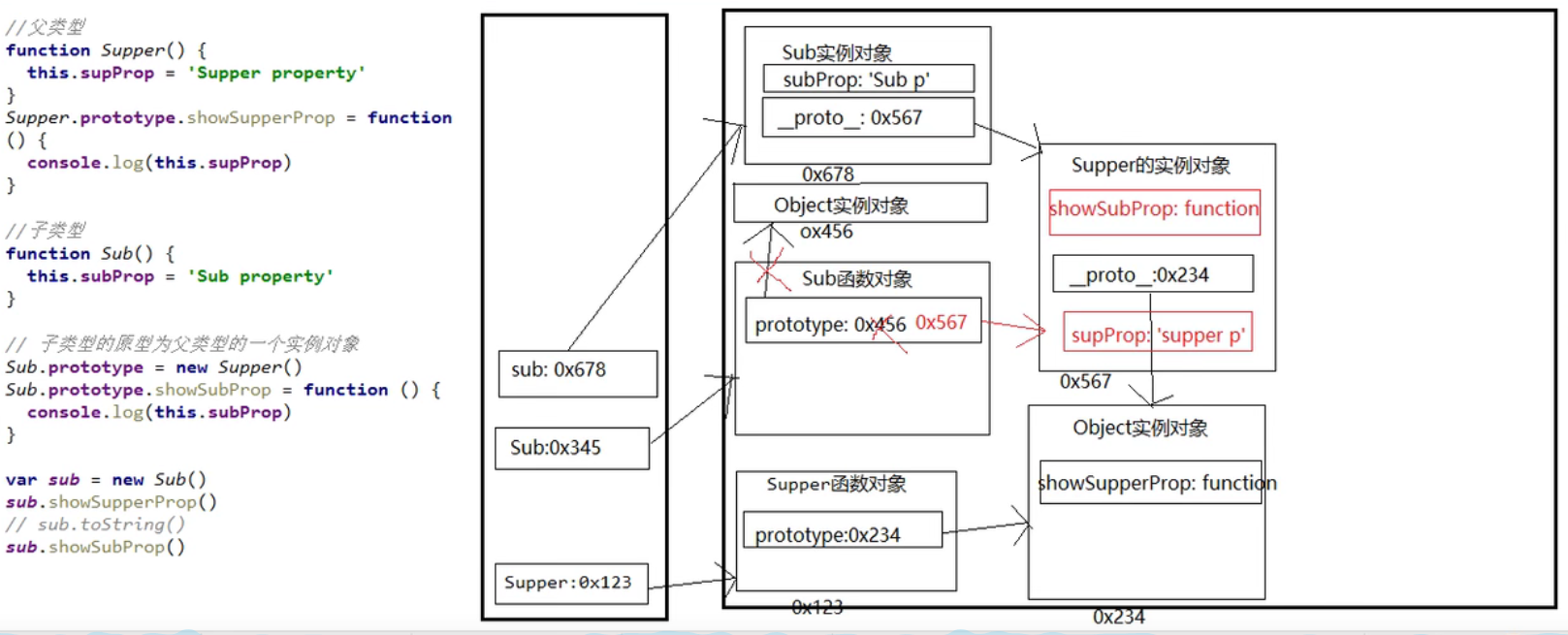
借用构造函数继承
在子类型构造函数中通过call()调用父类型构造函数
function Person(name,age){ this.name = name this.age = age } function Student(name,age,price){ Person.call(this,name,age) this.price = price } var s = new Student("TOM",12,13000)
组合继承
原型链+借用构造函数的组合继承:function Person(name,age){ this.name = name this.age = age } Person.prototype.setName = function(name){ this.name = name } function Student(name,age,price){ Person.call(this,name,age) //为了得到属性 this.price = price } Student.prototype = new Person() //为了能看到父类型的方法 Student.prototype.constructor = Student //修正constructor属性 Student.prototype.setPrice = function(price){ this.price = price } var s = new Student("TOM",12,13000) s.setName("BOB") s.setPrice("99999")
进程与线程
进程:程序的一次执行,它占有一片独立的内存空间
线程:是进程内一个独立的执行单元;是程序执行的一个完整的流程;是CPU最小的调度单元
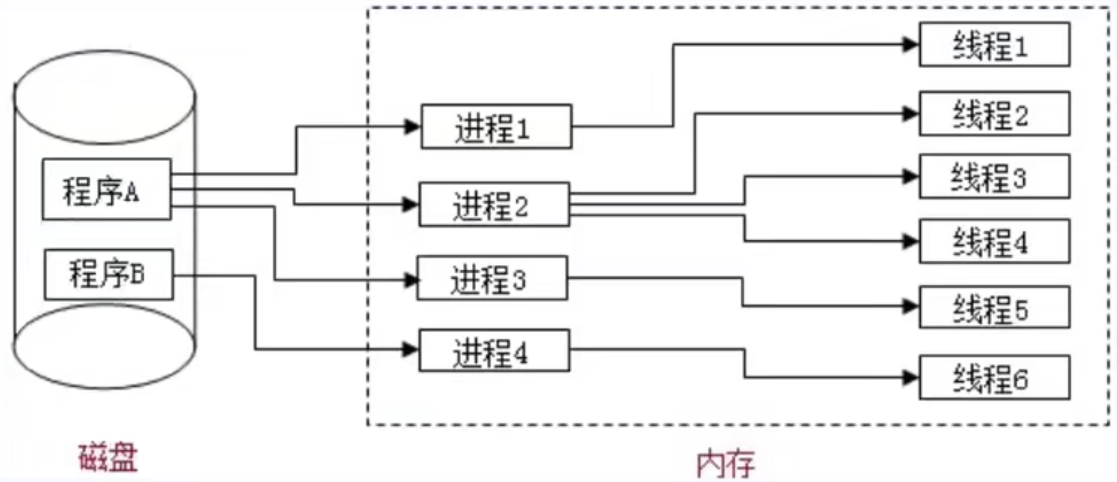
相关知识:
应用程序必须运行在某个进程的某个线程上
一个进程中至少有一个运行的线程:主线程,进程启动后自动创建
一个进程中也可以同时运行多个线程,也就是说程序是多线程运行的
一个进程内的数据可以供其中的多个线程直接共享
多个进程之间的数据是不能直接共享的
线程池:保存多个线程对象的容器,实现线程对象的反复利用
多线程:
优点:提高CPU的利用率
缺点:创建多线程开销
线程间切换开销
死锁与状态同步问题
Js是单线程运行的,但使用H5中的web workers可以多线程运行
浏览器的运行是多线程的(有的是单进程,有的是多进程)
浏览器内核
支撑浏览器运行的最核心的程序
不同浏览器不一样
内核由很多模块组成
重载
同样的函数,不同的参数个数,执行不同的代码
比如:
function fn(name) { console.log(`我是${name}`) } function fn(name, age) { console.log(`我是${name},今年${age}岁`) } function fn(name, age, sport) { console.log(`我是${name},今年${age}岁,喜欢运动是${sport}`) } /* * 理想结果 */ fn('nlf') // 我是nlf fn('nlf', 18) // 我是nlf,今年18岁 fn('nlf', 18, '打篮球') // 我是nlf,今年18岁,喜欢运动是打篮球
//实际结果
我是nlf,今年undefined岁,喜欢运动是undefined
我是nlf,今年18岁,喜欢运动是undefined
我是nlf,今年18岁,喜欢运动是打篮球
最后一个fn的定义,把前面两个都给覆盖了,所以没有实现重载的效果
简单的做法:想要实现理想的重载效果,可以只写一个fn函数,并在这个函数中判断arguments类数组的长度,执行不同的代码,就可以完成重载的效果
function fn() { switch (arguments.length) { case 1: var [name] = arguments console.log(`我是${name}`) break; case 2: var [name, age] = arguments console.log(`我是${name},今年${age}岁`) break; case 3: var [name, age, sport] = arguments console.log(`我是${name},今年${age}岁,喜欢运动是${sport}`) break; } }
发现了一种比较高端的做法,可以利用闭包来实现重载的效果
function addMethod(object, name, fn) { var old = object[name]; //把前一次添加的方法存在一个临时变量old里面 object[name] = function () { // 重写了object[name]的方法 // 如果调用object[name]方法时,传入的参数个数跟预期的一致,则直接调用 if (fn.length === arguments.length) { return fn.apply(this, arguments); // 否则,判断old是否是函数,如果是,就调用old } else if (typeof old === "function") { return old.apply(this, arguments); } } } addMethod(window, 'fn', (name) => console.log(`我是${name}`)) addMethod(window, 'fn', (name, age) => console.log(`我是${name},今年${age}岁`)) addMethod(window, 'fn', (name, age, sport) => console.log(`我是${name},今年${age}岁,喜欢运动是${sport}`)) /* * 实现效果 */ window.fn('nlf') // 我是nlf window.fn('nlf', 18) // 我是nlf,今年18岁 window.fn('nlf', 18, '打篮球') // 我是nlf,今年18岁,喜欢运动是打篮球
按位非 ~
js中按位非运算符是 ~ ,作用是将每位二进制取反
比如:十进制2的二进制表示为:0000,0010
每位都取反:1111,1101 ,这是内存中的保存形式。
我们读取的十进制是根据原码来读取,而在内存中,数值都是以二进制补码形式保存的。
正数的补码和原码一样,负数的原码转补码或者补码转原码的规则:
符号位不变,将剩余位取反,得到反码,在反码的基础上最后一位加一得到负数的补码。
1111,1101输出10进制的过程:
- 符号位不变,剩余位取反
1000,0010 - 最后一位加1
1000,0011 - 得的结果1000,0011就是-3的原码形式
记忆方法是~(A) = -(A+1)
~(1) = -2 ~(0) = -1 ~(-1) = 0
Proxy代理
Proxy代理对象:使用代理对象,对目标对象的属性操作全部改为对代理对象相同属性的操作,代理对象提供了对属性获取 [[get]] 、修改 [[set]] 等操作的拦截,js将这种拦截称为trap(捕捉器)。
通过捕捉器,我们就可以捕获到 代码中对属性的操作时机,让我们能够先执行我们自定义的业务逻辑代码。因为我们对目标对象的属性操作改为了对代理对象相同的属性操作,所以我们在最后需要通过Reflect执行目标对象的原始操作。
比如:
var consume = 0 var obj = {wallet:100} var handlers = { set(target,key,val){ //target:目标对象,key:代理对象要修改的属性 consume++ Reflect.set(target,key,val) } } //代理对象 var pObj = new Proxy(obj,handlers) //将目标对象obj的属性wallet的操作改为代理对象相同属性wallet的操作 pObj.wallet = 97 pObj.wallet = 94 console.log(obj.wallet) //94 console,log(consume) //2
Reflect
Reflect用来触发目标对象执行相应的操作
Reflect.get(target,key,context) //等价于target[key] Reflect.set(target,key,val) //等价于 target[key] = val
async/await原理
用处就是:用同步方式,执行异步操作
async/await是一种语法糖,语法糖,我个人理解就是,语法糖就是一个东西,这个东西你就算不用他,你用其他手段也能达到这个东西同样的效果,但是可能就没有这个东西这么方便了。
1、generator函数:
generator函数跟普通函数在写法上的区别就是:多了一个星号*,并且只有在generator函数中才能使用yield,什么是yield呢,他相当于generator函数执行的中途暂停点,比如下方有3个暂停点。而怎么才能暂停后继续走呢?那就得使用到next方法,next方法执行后会返回一个对象,对象中有value 和 done两个属性function* gen() { yield 1 yield 2 yield 3 return 4 } const g = gen() console.log(g.next()) // { value: 1, done: false } console.log(g.next()) // { value: 2, done: false } console.log(g.next()) // { value: 3, done: false } console.log(g.next()) // { value: 4, done: true }
2、yield后面接Promise,next函数传参
return new Promise(resolve => { setTimeout(() => { resolve(nums * 2) }, 1000) }) } function* gen() { const num1 = yield fn(1) const num2 = yield fn(num1) const num3 = yield fn(num2) return num3 } const g = gen() const next1 = g.next() next1.value.then(res1 => { console.log(next1) // 1秒后同时输出 { value: Promise { 2 }, done: false } console.log(res1) // 1秒后同时输出 2 const next2 = g.next(res1) // 传入上次的res1 next2.value.then(res2 => { console.log(next2) // 2秒后同时输出 { value: Promise { 4 }, done: false } console.log(res2) // 2秒后同时输出 4 const next3 = g.next(res2) // 传入上次的res2 next3.value.then(res3 => { console.log(next3) // 3秒后同时输出 { value: Promise { 8 }, done: false } console.log(res3) // 3秒后同时输出 8 // 传入上次的res3 console.log(g.next(res3)) // 3秒后同时输出 { value: 8, done: true } }) }) })
3、活代码(封装一个高阶函数)
function generatorToAsync(generatorFn) { return function() { const gen = generatorFn.apply(this, arguments) // gen有可能传参 // 返回一个Promise return new Promise((resolve, reject) => { function go(key, arg) { let res try { res = gen[key](arg) // 这里有可能会执行返回reject状态的Promise } catch (error) { return reject(error) // 报错的话会走catch,直接reject } // 解构获得value和done const { value, done } = res if (done) { // 如果done为true,说明走完了,进行resolve(value) return resolve(value) } else { // 如果done为false,说明没走完,还得继续走 // value有可能是:常量,Promise,Promise有可能是成功或者失败 return Promise.resolve(value).then(val => go('next', val), err => go('throw', err)) } } go("next") // 第一次执行 }) } } function* gen() { const num1 = yield fn(1) const num2 = yield fn(num1) const num3 = yield fn(num2) return num3 } const asyncFn = generatorToAsync(gen) asyncFn().then(res => console.log(res))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号