Python学习笔记DAY11(常用模块_time、random、os、sys)
这是我个人的学习笔记,都赖于(egon老师)的分享,以下是老师博客的原地址:
https://www.cnblogs.com/xiaoyuanqujing/articles/11640888.html
python常用模块
一、time与datetime模块
time
-
时间分为三种格式:
- 时间戳:从1970年到现在经过的秒数 主要用于时间间隔的计算
- 格式化时间:比如 2020-05-07 10:59:59 (按照某种格式显示时间)主要用于展示时间
- 结构化时间:当前(年,月,日,时,分,秒,周,夏令时)主要用于单独获取时间的某一部分
import time # 1. 时间戳 time.time() # 结果:1620356530.3794103 # 2. 格式化时间 time.strftime("%Y-%m-%d %H:%M:%S %p") # 结果:2021-05-07 11:06:31 AM # 3. 结构化时间 print(time.localtime()) # 结果:time.struct_time(tm_year=2021, tm_mon=5, tm_mday=7, tm_hour=11, # tm_min=7, tm_sec=27, tm_wday=4, tm_yday=127, tm_isdst=0) # 4.补充:time.localtime() 是本地时区 / time.gmtime() 是utc国际时区 (中国标准时区与国际标准时区差8小时) print(time.gmtime()) # 结果:只有小时不同 ----> tm_hour=3# 日期格式字典 %a Locale’s abbreviated weekday name. %A Locale’s full weekday name. %b Locale’s abbreviated month name. %B Locale’s full month name. %c Locale’s appropriate date and time representation. %d Day of the month as a decimal number [01,31]. %H Hour (24-hour clock) as a decimal number [00,23]. %I Hour (12-hour clock) as a decimal number [01,12]. %j Day of the year as a decimal number [001,366]. %m Month as a decimal number [01,12]. %M Minute as a decimal number [00,59]. %p Locale’s equivalent of either AM or PM. (1) %S Second as a decimal number [00,61]. (2) %U Week number of the year (Sunday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Sunday are considered to be in week 0. (3) %w Weekday as a decimal number [0(Sunday),6]. %W Week number of the year (Monday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Monday are considered to be in week 0. (3) %x Locale’s appropriate date representation. %X Locale’s appropriate time representation. %y Year without century as a decimal number [00,99]. %Y Year with century as a decimal number. %z Time zone offset indicating a positive or negative time difference from UTC/GMT of the form +HHMM or -HHMM, where H represents decimal hour digits and M represents decimal minute digits [-23:59, +23:59]. %Z Time zone name (no characters if no time zone exists). %% A literal '%' character.
datetime
-
得到有样式的当前时间:datetime.datetime.now()
datetime.datetime.now() # 不用像time中格式化时间,写那么麻烦,就可以得到一个有样式的时间 # 结果:2021-05-07 11:25:31.401726 但是,这个样式是固定的,如果要其他样式,还需要time来实现 -
对当前时间进行加减运算:datetime.timedelta
datetime.datetime.now()+datetime.timedelta(days=3) # 当前时间的三天后 datetime.datetime.now()+datetime.timedelta(weeks=1) # 当前时间一周后(可以填写小时,分钟,秒等等)
时间格式转换
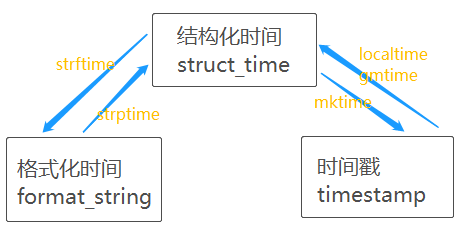
- 结构化时间与格式化时间可以互相转换
- 结构化时间与时间戳可以互相转换
- 但是,格式化时间与时间戳无法转换。如果必须转换需要通过struct_time作为中介
# 结构化<===>时间戳
s_time = time.localtime() # 得到结构化时间
time.mktime(s_time) # 把结构化时间转为时间戳
t_time = time.time() # 得到时间戳
time.localtime(t_time) # 时间戳转为中国结构化时间
time.gmtime(t_time) # 时间戳转为国际结构化时间
# 结构化<===>格式化
time.strftime("%Y-%m-%d %H:%M:%S",s_time) # 把结构化时间转为格式化字符串时间
time.strptime("2021-05-07 11:06:31","%Y-%m-%d %H:%M:%S") # 把格式化字符串时间,转换为结构化时间
# 时间戳<===>格式化
# (有一个时间"2021-05-07 11:06:31"需要进行时间运算往后加三天)
# 注意:虽然我们学过 datetime.timedelta(days=3) 可以进行时间运算,但是只局限于获取到的当前时间
st = time.strptime("2021-05-07 11:06:31","%Y-%m-%d %H:%M:%S") # 把拿到的时间结构化
tt = time.mktime(st) + 86400*3 # 把结构化的时间,转成时间戳进行加减,得出最终结果
sst = time.localtime(tt) # 把换算后的结果再结构化
ft = time.strftime("%Y-%m-%d %H:%M:%S",sst) # 把换算后的结果格式化
print(ft) # 结果: 2021-05-10 11:06:31
了解知识:
# 得到另一种格式化时间
gt = time.asctime(st) # 把结构化的时间转换为 另一种格式化(linux常用)
# Fri May 7 11:06:31 2021(2021年5月7日 周五 11点06分31秒)
ggt = time.ctime(tt) # 把时间戳转换为 另一种格式化(linux常用)
# Mon May 10 11:06:31 2021
## 获取现在的国际时间
datetime.datetime.utcnow() # 2021-05-07 08:57:17.380972
## 格式化的时间戳
datetime.datetime.fromtimestamp(1620356530.3794103)
# 不用填写样式,直接格式化时间戳,但是格式就固定一个
二、random模块
这是一个产生各种类型的随机数模块
常用功能
import random
random.randint(1,3) # 随机从数字列表取一个值,范围(1,2,3)开区间
random.randrange(1,3) # 随机从数字列表取一个值,范围(1,2)顾头不顾尾
random.choice([1,"z",["nida","yaoyao"]]) # 随机从任意列表中取一个值 ,范围是整个列表
random.sample([1,"z",["nida","yaoyao"]],2) # 随机从任意列表中取”指定数量“的值 ,范围是整个列表
random.uniform(1,3) # 随机从列表中取出一个浮点数,范围是1-3区间内
random.shuffle([1,3,6,8,9]) # 打乱列表原来的顺序
随机生成验证码
# 随机生成验证码
def ran(size):
res = "" # 先定义一个空的字符串,为以后放入随机字符做准备
for i in range(size): # 循环指定验证码长度
n = str(random.randint(0,9)) # 从0-9(开区间)随机取出一个数字
y = chr(random.randint(65,90)) # 按asc码表位置,从26个大写字母,随机取出一个字母
res += random.choice([n,y]) # 把每次取出的一个数字和一个字母,组成列表放入choice
return res
print(ran(6)) # 1U9Y4R
三、os模块
这是一个与操作系统交互的接口集合的模块(关于文件的各种操作)
import os
os.listdir(r"G:\NIDA\pythonstudent0.0\db") # 必须查询的是文件夹
# 结果:['db_handle.py', 'username.txt', '__init__.py', '__pycache__']
# 以列表形式,返回 指定文件夹下的所有文件夹和文件名称
os.path.getsize(r"G:\NIDA\pythonstudent0.0\db\username.txt") # 39
# 以int类型返回,查询的文件大小(单位是字节)
os.remove(r"G:\NIDA\pythonstudent0.0\00")
# os.remove(r"G:\NIDA\pythonstudent0.0\db\test01") # 根据文件路径,删除指定文件(只能删除文件,不能删除包)
os.path.normcase('G://NIDA//Pythonstudent0.0\\db\\username.txt')
# 结果:g:\\nida\\pythonstudent0.0\db\username.txt
# 在linux和mac平台上,该函数会原样返回path,在Windows平台上会将路径中所有字符转换为小写,
# 并将所有斜杠转为反斜杠
os.path.abspath("test.py") # 获取指定文件的绝对路径
os.path.abspath(__file__) # 获取当前运行文件的绝对路径
os.path.dirname("test.py") # 获取指定文件夹的上一级目录
os.path.normpath('G://NIDA//Pythonstudent0.0\\..\\username.txt')
# 在Windows平台上将所有斜杠转为反斜杠。
# 规范化路径,.. 代表上一级,并去除错误斜杠
os.path.normpath('G://NIDA//Pythonstudent0.0\\\\db\\username.txt\..\..')
# 结果: G:\NIDA\Pythonstudent0.0
# 具体应用(在任何环境下,获取想要的路径).
# 第一种方案(不建议使用)
a= os.path.normpath( # 去除错误字符
os.path.join( # 拼接地址
os.path.abspath(__file__), # 获取当前运行文件的绝对路径
os.pardir, # 当前路径的上一级
os.pardir # 当前路径的上一级
))
# 第二种方案(建议使用)
# 添加指定路径到环境变量(不受平台影响)
import sys
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
四、sys模块
“sys”即“system”,系统的意思。该模块提供了一些接口:用户访问python解释器自身使用和维护的变量。同时模块中还提供了一些函数,可以与解释器进行相对深度的交互。
import sys
sys.argv # 命令行参数List,第一个元素是程序本身路径
sys.exit(6) # 退出程序,正常退出时exit(0)
sys.version # 获取Python解释程序的版本信息
sys.maxsize # 获取最大的值
sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform # 返回操作系统平台名称
import sys
import time
# 具体应用
# =====知识储备=====
# [# ]
# [## ]
# [### ]
# 进度条并不是真的一个条目的进度变化,实际上是后一个进度样式,覆盖前一个
# 指定宽度
# print('[%-15s]' %'#') # 结果:[# ]
# # 第一个百分号代表引用,-15代表宽度,s代表被引用的值
# print('[%-15s]' %'##') # 结果:[## ]
#
# # 对引用的值加上% 的正确写法
# print('%s%%'%(100)) # 结果:100%
#
# # 可传参控制进度条的宽度
# print(('[%%-%ds]' %20) %'#') # 把打印宽度也作为引用值
# 实现打印进度条函数
# percent 变化中的百分比
def progerss(percent,width = 50):
print_str = ('[%%-%ds]' % width) %(int(width*percent)*"#")
print('\r%s %d%%' %(print_str,int(100*percent)),file=sys.stdout,flush=True,end='')
# \r 每次打印都从最开始位置。加上 end= "" 不换行 就造成了进度快速覆盖
# file=sys.stdout
# sys.stdout的形式就是print的一种默认输出格式,等于print "%VALUE%"
# print函数是对sys.stdout的高级封装
# print 也可通过file参数将输出打印到其他文件中
# f = open('test.txt','a')
# print('this is a test',file=f)
# 二、sys.stdout.write()输出不会自动换行,没有end,可用转义字符自行控制
# /n 换行
# /r 回车到本行首,可刷新输出
# 如用sys.stdout.write() 和\r实现自定义进度条
# flush=True 刷新缓存区(缓存区满时,自动刷新)
# 当我们需要打印一些字符时,并不是立刻就打印,
# 而是先将需要打印的字符放入缓冲区,在缓冲区刷新时打印,
# 当缓冲区未满,或者程序运行未结束时,可使用sys.stdout.flush()强制刷新缓冲区,立刻进行打印;
data_size = 10214 # 下载或读取数据字节长度
recv_size = 0 # 已下载或读取的数据长度
while recv_size < data_size:
time.sleep(0.1) # 模拟数据延迟
recv_size += 1024 # 每次读取1024字节的数据
percent = recv_size/data_size # 读取数据的进度变化百分比
progerss(percent) # 循环调用打印进度条的函数,每多下载1024就更新一次进度条

 浙公网安备 33010602011771号
浙公网安备 33010602011771号