
LeNet-5实现MNIST分类
LeNet-5实现MNIST分类
本人水平有限,如有错误,欢迎指出!
1. LeNet-5
1.1 简介
LeNet-5是由“深度学习三巨头”之一、图灵奖得主Yann LeCun在一篇名为"Gradient-Based Learning Applied to Document Recognition"的paper(paper下载地址:https://www.researchgate.net/publication/2985446_Gradient-Based_Learning_Applied_to_Document_Recognition )中提出的神经网络结构,在手写数字和机器打印字符上十分高效。
1.2 网络结构
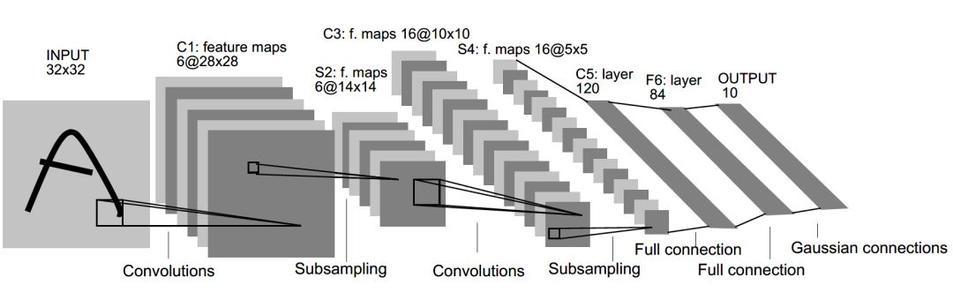
上图为原文的网络结构,但是由于MNIST数据集的图像为28 * 28(单通道),所以需要对网络结构进行轻微的调整
本题采用的网络结构:
图片输入:28 * 28 * 1
卷积层:使用6个3 * 3 * 1的过滤器,步长为1,padding为same,输出的图像为28 * 28 * 6
最大池化层:使用2 * 2的过滤器,步长为2,输出的图像为14 * 14 * 6
卷积层:使用16个3 * 3 * 6的过滤器,步长为1,padding为valid,输出的图像为12 * 12 * 16
最大池化层:使用2 * 2的过滤器,步长为2,输出的图像为6 * 6 * 16
全连接层:120个节点
全连接层:84个节点
输出层:10个节点
2. Tensorflow2实现LeNet-5
2.1 数据预处理
首先读取数据集(建议直接从网上找资源下载然后保存好,不用反复在线读取),并将灰度值缩小到0到1,便于训练。同时,要注意将train_data格式从[60000, 28, 28]变为[60000, 28, 28, 1],为后面的卷积运算作准备。
(train_data, train_label), (test_data, test_label) = tf.keras.datasets.mnist.load_data()
train_data = np.expand_dims(train_data.astype(np.float32) / 255.0, axis=-1)
train_label = train_label.astype(np.int32)
test_data = np.expand_dims(test_data.astype(np.float32) / 255.0, axis=-1)
test_label = test_label.astype(np.int32)
2.2 网络搭建
根据修改后的LeNet-5网络结构搭建神经网络,通过继承tf.keras.Model这个类来定义模型 ,并添加了BN层。
class LeNet5(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(filters=6, kernel_size=[3, 3], strides=1, padding='same')
self.pool1 = tf.keras.layers.MaxPooling2D(pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(filters=16, kernel_size=[3, 3], strides=1, padding='valid')
self.pool2 = tf.keras.layers.MaxPooling2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(units=120, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=84, activation=tf.nn.relu)
self.dense3 = tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
self.bn1 = tf.keras.layers.BatchNormalization()
self.bn2 = tf.keras.layers.BatchNormalization()
def call(self, inputs):
x = self.conv1(inputs)
x = self.bn1(x)
x = self.pool1(x)
x = tf.nn.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.pool2(x)
x = tf.nn.relu(x)
x = self.flatten(x)
x = self.dense1(x)
x = self.dense2(x)
x = self.dense3(x)
return x
2.3 模型装配
在本模型中采用Adam优化算法,初始的学习率为1e-3,由于label采用的是数字编码,所以使用sparse_categorical_crossentropy。
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
2.4 模型训练
在模型训练的过程中,每128组数据为1个batch,训练20次,并选出6000组数据作为验证集,剩下的数据作为训练集。
在本模型中采取了学习率衰减机制,如果连续3次训练验证集分类的准确率没有提高,学习率就变为原先的0.2倍。同时,为了防止过拟合,模型中还采用了EarlyStopping机制,在连续6次训练时,如果验证集分类的准确率没有提高,就终止训练。
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_sparse_categorical_accuracy', factor=0.2, patience=3)
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_sparse_categorical_accuracy', patience=6)
history = model.fit(train_data, train_label, epochs=20, batch_size=128, verbose=2, validation_split=0.1, callbacks=[reduce_lr, early_stopping])
2.5 测试效果
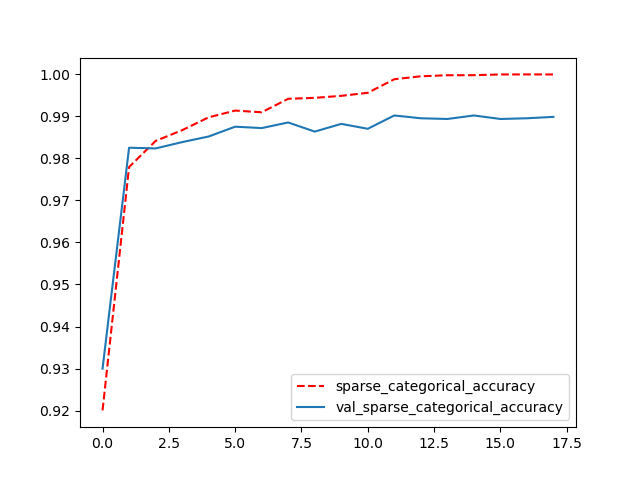
经过训练,MNIST测试集的分类准确率可达到99%以上,训练集与验证集的分类准确率变化过程和代码运行信息如下所示,完整代码可见https://github.com/NickHan-cs/Tensorflow2.x。
Epoch 1/20
422/422 - 2s - loss: 0.2597 - sparse_categorical_accuracy: 0.9201 - val_loss: 0.2141 - val_sparse_categorical_accuracy: 0.9300 - lr: 0.0010
Epoch 2/20
422/422 - 2s - loss: 0.0704 - sparse_categorical_accuracy: 0.9779 - val_loss: 0.0550 - val_sparse_categorical_accuracy: 0.9825 - lr: 0.0010
Epoch 3/20
422/422 - 2s - loss: 0.0507 - sparse_categorical_accuracy: 0.9841 - val_loss: 0.0576 - val_sparse_categorical_accuracy: 0.9823 - lr: 0.0010
Epoch 4/20
422/422 - 2s - loss: 0.0410 - sparse_categorical_accuracy: 0.9867 - val_loss: 0.0505 - val_sparse_categorical_accuracy: 0.9838 - lr: 0.0010
Epoch 5/20
422/422 - 2s - loss: 0.0314 - sparse_categorical_accuracy: 0.9897 - val_loss: 0.0513 - val_sparse_categorical_accuracy: 0.9852 - lr: 0.0010
Epoch 6/20
422/422 - 2s - loss: 0.0273 - sparse_categorical_accuracy: 0.9913 - val_loss: 0.0472 - val_sparse_categorical_accuracy: 0.9875 - lr: 0.0010
Epoch 7/20
422/422 - 2s - loss: 0.0269 - sparse_categorical_accuracy: 0.9909 - val_loss: 0.0453 - val_sparse_categorical_accuracy: 0.9872 - lr: 0.0010
Epoch 8/20
422/422 - 2s - loss: 0.0191 - sparse_categorical_accuracy: 0.9941 - val_loss: 0.0465 - val_sparse_categorical_accuracy: 0.9885 - lr: 0.0010
Epoch 9/20
422/422 - 2s - loss: 0.0172 - sparse_categorical_accuracy: 0.9944 - val_loss: 0.0549 - val_sparse_categorical_accuracy: 0.9863 - lr: 0.0010
Epoch 10/20
422/422 - 2s - loss: 0.0157 - sparse_categorical_accuracy: 0.9948 - val_loss: 0.0466 - val_sparse_categorical_accuracy: 0.9882 - lr: 0.0010
Epoch 11/20
422/422 - 2s - loss: 0.0126 - sparse_categorical_accuracy: 0.9956 - val_loss: 0.0616 - val_sparse_categorical_accuracy: 0.9870 - lr: 0.0010
Epoch 12/20
422/422 - 2s - loss: 0.0044 - sparse_categorical_accuracy: 0.9988 - val_loss: 0.0412 - val_sparse_categorical_accuracy: 0.9902 - lr: 2.0000e-04
Epoch 13/20
422/422 - 2s - loss: 0.0027 - sparse_categorical_accuracy: 0.9995 - val_loss: 0.0438 - val_sparse_categorical_accuracy: 0.9895 - lr: 2.0000e-04
Epoch 14/20
422/422 - 2s - loss: 0.0021 - sparse_categorical_accuracy: 0.9997 - val_loss: 0.0441 - val_sparse_categorical_accuracy: 0.9893 - lr: 2.0000e-04
Epoch 15/20
422/422 - 2s - loss: 0.0019 - sparse_categorical_accuracy: 0.9997 - val_loss: 0.0451 - val_sparse_categorical_accuracy: 0.9902 - lr: 2.0000e-04
Epoch 16/20
422/422 - 2s - loss: 0.0013 - sparse_categorical_accuracy: 0.9999 - val_loss: 0.0447 - val_sparse_categorical_accuracy: 0.9893 - lr: 4.0000e-05
Epoch 17/20
422/422 - 2s - loss: 0.0013 - sparse_categorical_accuracy: 0.9999 - val_loss: 0.0445 - val_sparse_categorical_accuracy: 0.9895 - lr: 4.0000e-05
Epoch 18/20
422/422 - 2s - loss: 0.0012 - sparse_categorical_accuracy: 0.9999 - val_loss: 0.0444 - val_sparse_categorical_accuracy: 0.9898 - lr: 4.0000e-05
313/313 - 1s - loss: 0.0363 - sparse_categorical_accuracy: 0.9902

