
OO第一单元总结
OO第一单元总结
第一次作业
程序结构分析
1. 度量类的属性个数、方法个数、每个方法规模、每个方法的控制分支数目、类总代码规模
| 类名 | 属性个数 | 方法个数 | 类总代码规模 |
|---|---|---|---|
| MainClass | 0 | 2 | 20 |
| Expr | 13 | 6 | 132 |
| Expr类 | MainClass类 | ||||
|---|---|---|---|---|---|
| 方法名 | 方法规模 | 方法控制分支数目 | 方法名 | 方法规模 | 方法控制分支数目 |
| mySubstr | 5 | 0 | main | 9 | 0 |
| putInMap | 7 | 1 | head | 8 | 1 |
| Expr | 3 | 0 | |||
| deal | 47 | 10 | |||
| calc | 11 | 2 | |||
| myPrint | 38 | 8 |
2. 分析类的内聚和相互间的耦合情况
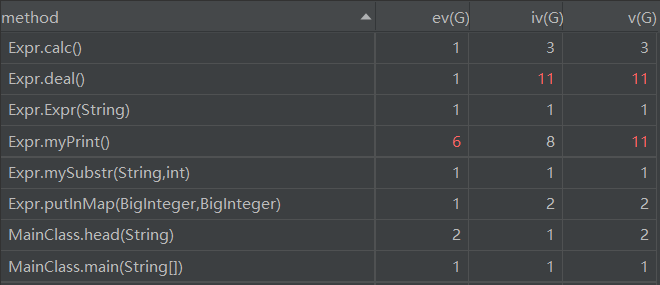
Expr类中用于解析字符串的deal方法,由于需要用输入匹配正则表达式和调用了mySubstr和putInMap等方法,导致模块设计复杂度和圈复杂度较高。Expr类中用于输出的myPrint方法,由于在优化输出时需要根据具体的数据来判断输出方式,所以用了大量的控制分支,导致基本复杂度和圈复杂度较高。
相关术语解释 摘自https://www.cnblogs.com/yjy2019/p/10579810.html
ev(G)基本复杂度是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
Iv(G)模块设计复杂度是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
v(G)是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。
3. DIT分析
此次作业由于多项式种类单一,没有使用类继承或接口实现,当然因此导致程序缺少可拓展性。
4. 类图
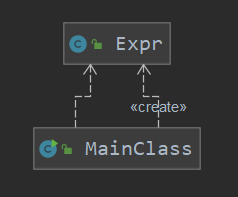
本次作业面向对象的程序设计思维并没有体现出来,基本上采用的面向过程的程序设计思维。
bug分析
1. 未通过公测用例和被互测发现的bug分析
-
常数项为0的情况
对于常数项大于0时,在输出时加上了+号;常数项小于0时,因为数字本身带有符号,所以不作处理。但是没有考虑到0的输出,程序直接输出了0,导致WA。
-
输入为常数的情况
测试数据鲁棒性设计不好,没有考虑到常数的边缘情况,导致字符串访问越界。
2. bug位置与设计结构之间的相关性分析及程序在设计上的问题分析
此次bug问题出现在Expr类的myPrint方法中,由复杂度分析也可知,该方法的圈复杂度较高,独立路径较多,合理预防错误需要测试的种类较多。这次的bug不仅是细节处理上的问题,也是面向过程的程序设计思维可能导致的问题,而反观面向对象的程序设计,可以在生成对象时进行预处理,除去常数项或系数为0或指数为0的情况,就不会导致该类bug
3. hack分析
此次互测hack结果3/10。hack成功的有两类数据:
- 针对于易错点的测试样例。本次作业连续的空格和符号是可能导致的bug的原因,因此针对连续符号中加入空格的情况测试了同组同学的程序。
- 边界情况的测试。类似于-x ** 2+ x ** 2前后相抵消的情况进行了测试,起因是在自己测试时也出现了此类问题。
第二次作业
程序结构分析
1. 度量类的属性个数、方法个数、每个方法规模、每个方法的控制分支数目、类总代码规模
| 类名 | 属性个数 | 方法个数 | 类总代码规模 |
|---|---|---|---|
| MainClass | 0 | 2 | 26 |
| Expr | 14 | 7 | 165 |
| Item | 6 | 7 | 43 |
| Poly | 5 | 14 | 83 |
| Mono | 2 | 8 | 53 |
| Sin | 2 | 8 | 50 |
| Cos | 2 | 8 | 50 |
| MainClass类 | ||
|---|---|---|
| 方法名 | 方法规模 | 方法控制分支数目 |
| main | 13 | 1 |
| head | 8 | 1 |
| Expr类 | Item类 | ||||
|---|---|---|---|---|---|
| 方法名 | 方法规模 | 方法控制分支数目 | 方法名 | 方法规模 | 方法控制分支数目 |
| MySubstr | 5 | 0 | Item | 8 | 0 |
| PutInList | 18 | 4 | getFh | 3 | 0 |
| Expr | 3 | 0 | getCoe | 3 | 0 |
| CoeDeal | 10 | 1 | getDeg | 3 | 0 |
| Update | 14 | 2 | getEnd | 3 | 0 |
| FindItem | 47 | 8 | getType | 3 | 0 |
| toString | 37 | 7 | getVar | 3 | 0 |
| Poly类 | Mono类 | ||||
|---|---|---|---|---|---|
| 方法名 | 方法规模 | 方法控制分支数目 | 方法名 | 方法规模 | 方法控制分支数目 |
| Poly() | 2 | 0 | Mono | 4 | 0 |
| Poly(Sin,Cos) | 4 | 0 | getCoe | 3 | 0 |
| Poly(Mono,Sin,Cos) | 5 | 0 | getDeg | 3 | 0 |
| getMono | 3 | 0 | copy | 3 | 0 |
| getSin | 3 | 0 | equal | 7 | 1 |
| getCos | 3 | 0 | add | 3 | 0 |
| setMono | 3 | 0 | multi | 3 | 0 |
| setSin | 3 | 0 | diff | 11 | 1 |
| setCos | 3 | 0 | |||
| copy | 3 | 0 | |||
| equals | 7 | 1 | |||
| CoeMulti | 3 | 0 | |||
| add | 4 | 0 | |||
| diff | 12 | 0 |
| Sin类 | Cos类 | ||||
|---|---|---|---|---|---|
| 方法名 | 方法规模 | 方法控制分支数目 | 方法名 | 方法规模 | 方法控制分支数目 |
| Sin | 4 | 0 | Cos | 4 | 0 |
| getCoe | 3 | 0 | getCoe | 3 | 0 |
| getDeg | 3 | 0 | getDeg | 3 | 0 |
| copy | 3 | 0 | copy | 3 | 0 |
| equal | 7 | 1 | equal | 7 | 1 |
| add | 3 | 0 | add | 3 | 0 |
| multi | 3 | 0 | multi | 3 | 0 |
| triDiff | 8 | 0 | triDiff | 8 | 0 |
2. 分析类的内聚和相互间的耦合情况
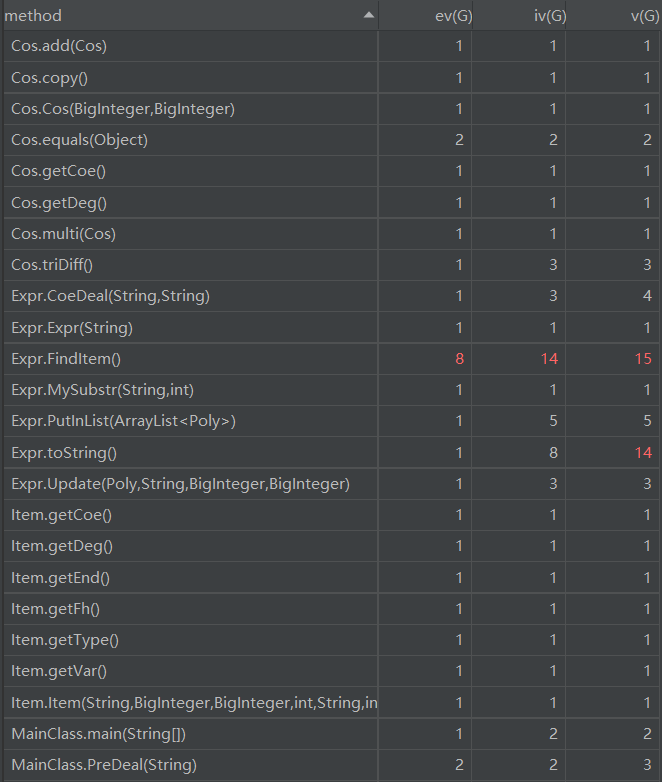
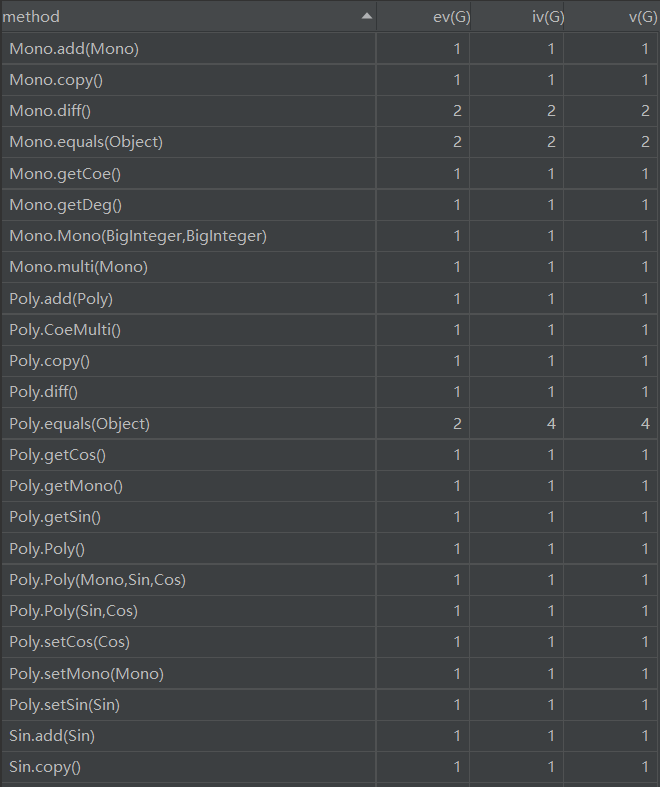
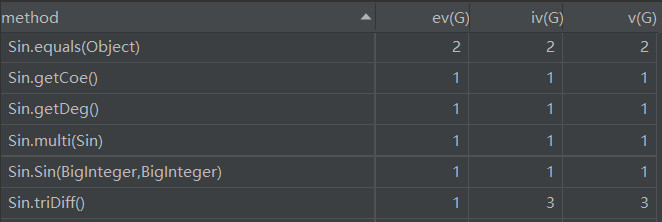
Expr类中用于解析字符串获取项的FindItem方法,由于需要用输入匹配正则表达式、项种类较多和多次调用了MySubstr和Update等方法,导致基本复杂度、模块设计复杂度和圈复杂度较高。Expr类中用于输出的toString方法,由于需要根据具体的数据来判断输出方式(应该在各个类中实现toString方法,提高类内聚),所以用了大量的控制分支,导致圈复杂度较高。
3. DIT分析
本次作业没有使用类继承或接口实现,但是根据程序结构分析可知,Mono类、Sin类和Cos类要实现的方法高度相似,可以创建接口,使以上类Mono类、Sin类和Cos类来实现该接口,这样的设计思路更加符合面向对象的程序设计思维和规范。
4. 类图
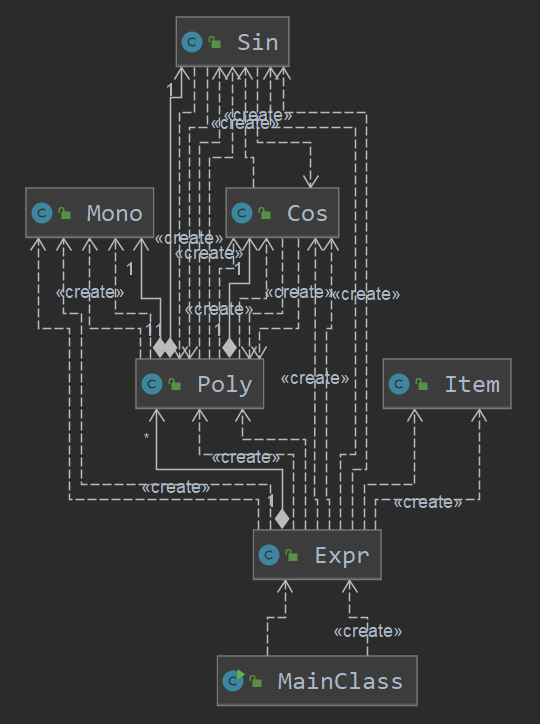
虽然此次作业根据项的性质创建了相应的类,有了面向对象的程序设计的雏形,但是由类图分析可知,类之间的关系较为紊乱,而且可拓展性较差,难于维护,应该如DIT分析中所说的方式来实现,或者采用在之后的应用对象创建模式中提高的工厂模式来实现,更加合理。
bug分析
此次作业在公测和互测阶段没有出现任何错误,同时也没有hack到他人错误。
第三次作业
程序结构分析
1. 度量类的属性个数、方法个数、每个方法规模、每个方法的控制分支数目、类总代码规模
| 类名 | 属性个数 | 方法个数 | 类总代码规模 |
|---|---|---|---|
| AddSub | 3 | 9 | 81 |
| Const | 3 | 7 | 42 |
| Cos | 8 | 8 | 80 |
| Exp | 14 | 11 | 206 |
| MainClass | 0 | 2 | 66 |
| Multi | 5 | 11 | 115 |
| Nest | 8 | 7 | 60 |
| Pow | 8 | 8 | 81 |
| Sin | 8 | 8 | 79 |
| Multi类 | Exp类 | ||||
|---|---|---|---|---|---|
| 方法名 | 方法规模 | 方法控制分支数目 | 方法名 | 方法规模 | 方法控制分支数目 |
| Multi | 4 | 0 | BrDeal | 34 | 5 |
| getRight | 3 | 0 | PreDeal | 9 | 1 |
| getLeft | 3 | 0 | MySubstr | 5 | 0 |
| setLeft | 3 | 0 | ToTree | 13 | 2 |
| setRight | 3 | 0 | PopStack | 10 | 2 |
| ConstCal | 5 | 0 | FactorCheck | 26 | 5 |
| SinCal | 10 | 2 | BrCheck | 3 | 0 |
| CosCal | 10 | 2 | Exit | 4 | 0 |
| PowCal | 12 | 3 | Exp | 6 | 0 |
| getStr | 21 | 7 | getItem | 60 | 11 |
| getDiff | 18 | 4 | 4 | 0 |
| AddSub类 | Pow类 | ||||
|---|---|---|---|---|---|
| 方法名 | 方法规模 | 方法控制分支数目 | 方法名 | 方法规模 | 方法控制分支数目 |
| AddSub | 3 | 0 | Pow | 22 | 5 |
| getRight | 3 | 0 | getRight | 3 | 0 |
| getLeft | 3 | 0 | getLeft | 3 | 0 |
| setLeft | 3 | 0 | setLeft | 3 | 0 |
| setRight | 3 | 0 | setRight | 3 | 0 |
| ConstCal | 9 | 1 | getStr | 3 | 0 |
| EqualDeal | 7 | 1 | getDiff | 13 | 3 |
| getStr | 15 | 4 | getDeg | 3 | 0 |
| getDiff | 13 | 3 |
| Cos类 | Sin类 | ||||
|---|---|---|---|---|---|
| 方法名 | 方法规模 | 方法控制分支数目 | 方法名 | 方法规模 | 方法控制分支数目 |
| Cos | 20 | 4 | Sin | 20 | 4 |
| getRight | 3 | 0 | getRight | 3 | 0 |
| getLeft | 3 | 0 | getLeft | 3 | 0 |
| setLeft | 3 | 0 | setLeft | 3 | 0 |
| setRight | 3 | 0 | setRight | 3 | 0 |
| getStr | 3 | 0 | getStr | 3 | 0 |
| getDiff | 14 | 3 | getDiff | 13 | 3 |
| getDeg | 3 | 0 | getDeg | 3 | 0 |
| Nest类 | Const类 | ||||
|---|---|---|---|---|---|
| 方法名 | 方法规模 | 方法控制分支数目 | 方法名 | 方法规模 | 方法控制分支数目 |
| Nest | 4 | 0 | Const | 4 | 0 |
| getRight | 3 | 0 | getRight | 3 | 0 |
| getLeft | 3 | 0 | getLeft | 3 | 0 |
| setLeft | 3 | 0 | setLeft | 3 | 0 |
| setRight | 3 | 0 | setRight | 3 | 0 |
| getStr | 10 | 1 | getStr | 3 | 0 |
| getDiff | 10 | 1 | getDiff | 3 | 0 |
| MainClass类 | ||
|---|---|---|
| 方法名 | 方法规模 | 方法控制分支数目 |
| ValidCheck | 48 | 3 |
| main | 11 | 1 |
2. 分析类的内聚和相互间的耦合情况
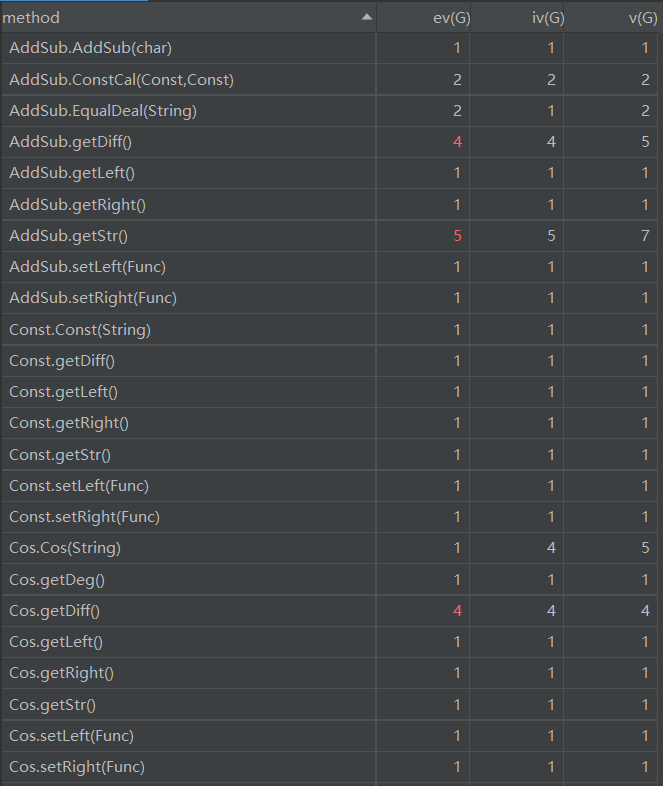
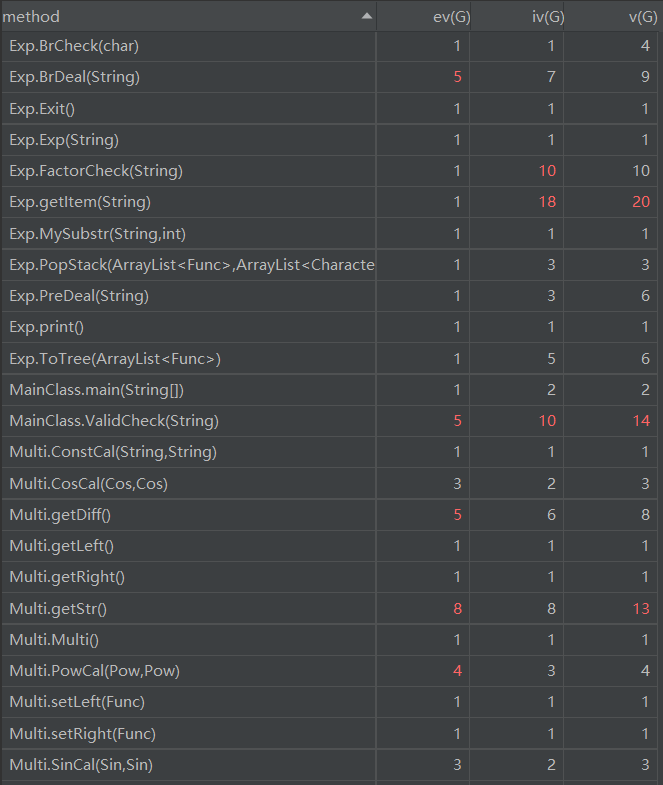
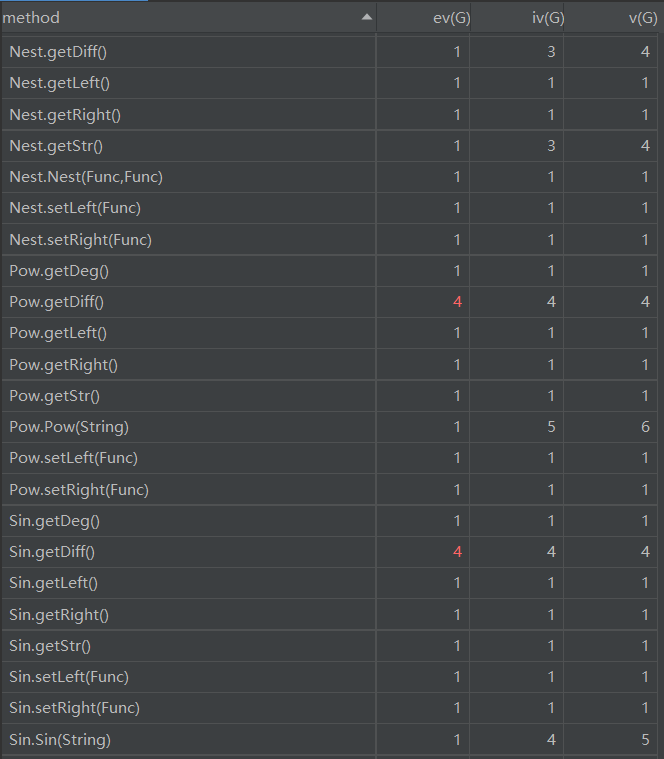
AddSub类的getDiff方法和getStr方法、Cos类的getDiff方法、Sin类的getDiff方法、Pow类的getDiff方法、Multi类的Multi方法、PowCal方法和getDiff方法为优化输出判断了多种特殊形式,用了较多的控制分支语句,导致基本复杂度高,非结构化程度高。Exp类的BrDeal方法,用于替换括号,方便提取括号中的表达式,但是在设计方法上不够好,导致基本复杂度高,程序较难理解。Exp类的FactorCheck方法和getItem方法耦合度较高,难于复用。Multi类的getStr方法为优化输出讨论的情况较多,导致圈复杂度高,给测试造成了一定难度。MainClass类的ValidCheck方法是用于检测WF的格式,所以用了较多的控制分支,导致基本复杂度、模块设计复杂度和圈复杂度较高。Exp类的用于解析字符串的getItem方法,由于本次作业的输入数据较为复杂,还出现了嵌套,所以只能使用递归的方法来解析输入的字符串,导致模块设计复杂度和圈复杂度较高。
3. DIT分析
本次作业由于设计的类都具有读写左右子结点、求导和获取本身的方法,所以使这些类都实现了Func接口,可以构建结点都为Func的表达式二叉树,大大方便了运算工程。但还是有一定的不足,应该将项类和运算符类分开,可取的方法是使他们都实现双接口,共同的接口可以实现原先的方法,另一个接口可以实现项类和运算符类各自特有的方法,应该这样的设计更加符合面向对象的程序设计与构造,更加严谨,减少了模块间的耦合。
4. 类图
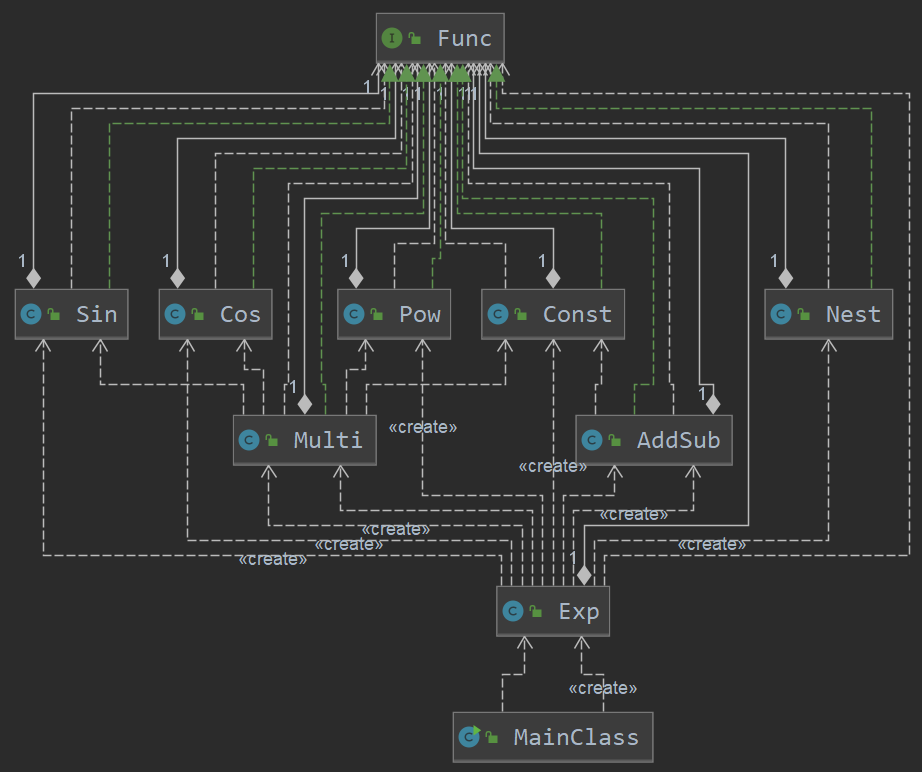
由类图可知,此次作业在程序结构的设计上较为清晰,但是正如DIT分析所说的,在接口实现上,不够严谨,在“高内聚,低耦合”的设计理念上做得还不够好,应该让类之间有效协同,类内部行为解耦,因此本次作业的程序结构还有很大的改进空间。
bug分析
1. 未通过公测用例和被互测发现的bug分析
-
相同对象相加时的情况。
在进行输出优化时,尝试用2*()或0来表示相同对象相加或相减的情况,但是把'+'误打成为'-'。
2. bug位置与设计结构之间的相关性分析及程序在设计上的问题分析
此次作业的bug出现在AddSub类的EqualDeal方法中,和设计结构相关性不大,但也暴露了输入处理的鲁棒性问题。
3. hack别人程序分析
此次互测hack结果2/28。hack成功的数据为:
- sin(0)的边界情况。本次hack用的是自己在测试时构造的一系列数据。
应用对象创建模式
工厂模式作为创建类模式,适用于需要生成复杂对象的场景,尤其适用于本单元对象类型较多的情况。使用工厂模式,可以很好地降低对象之间的耦合度,而且工厂模式依赖于接口,把对象的实例化工作交由实现类来完成,扩展性比较好,更加利于维护。
以下描述摘自实验二参考资料
简单工厂模式
简单工厂模式是由一个工厂对象根据收到的消息决定要创建的类的对象实例。在一个简单工厂中一般包
含下面几个部分:
工厂类:当我们想要获得由此工厂生产的产品时,只要调用工厂类里的生产产品的方法,传入我们想要生产的产品名即可。
产品接口:一个接口,工厂所生产的产品需要实现这个接口。可以理解为该工厂所生产的产品的一个共同的模具。
产品类:具体生产的产品,产品需要实现产品接口所要求的方法。工厂方法模式
相比于简单工厂模式,工厂方法模式增加定义了一个创建工厂的工厂接口,提高了工厂实现的扩展性。因此,我们引入了工厂方法模式,将上面一个工厂生产多个型号的产品改为一个工厂生产一个型号的产品,然后有多个工厂,这多个工厂共同实现一个工厂接口。
抽象工厂模式
我们引入一个产品族的概念:所谓的产品族,是指位于不同产品等级结构中功能相关联的产品组成的家族。抽象工厂模式所提供的一系列产品就组成一个产品族;而工厂方法提供的一系列产品称为一个等级结构。总体而言与工厂方法模式相同,仍然包括工厂接口、工厂类、产品接口、产品类。不同之处在于,在工厂类中,我们需要实现一个等级结构下的不同产品的创建方法。
针对本次作业,最基本的可以使用简单工厂模式,我们可以将分解的字符串作为参数传入用于创建对象的工厂,在工厂内部,根据字符串的格式,来判断需要生成对象的类型,并进行解析和生成对应的对象。采用这种应用对象创建模式,有一个工厂类专门用于生成对象,可以使类行为层次更加清晰,减少了对象之间的耦合度,更加符合“高内聚 低耦合”设计理念,更加容易测试、维护和扩展。
心得体会
这是OO的第一单元,我开始熟悉了面向对象程序的设计,从面向过程的程序设计思维逐渐转到了面向对象的程序设计思维,逐渐熟悉用类来管理数据、用容器来管理对象,也慢慢建立了程序鲁棒性的概念,有很大的收获。
一点较大的感受是,在进行新作业时,不是在迭代情况下的设计调整,而是每一次都进行完全的重构,花费了较多的时间和精力,这是在程序设计时没有考虑到可拓展性的结果,所以在之后的单元中,每一次设计都要考虑到可拓展性。
还有本单元的层次化设计也做的不够好,只在最后一次作业中用到了接口实现,层次化设计是面向对象程序设计与构造的重点之一,按照数据或行为建立抽象层次,对多层次对象进行归一化管理,将大大有利于程序的编写,更加符合“高内聚 低耦合”的设计理念。在之后开始每次作业前,都需要考虑好不同类型项之间的层次关系,这样可以事半功倍。

