

【Java虚拟机】浅谈Java虚拟机
跨平台
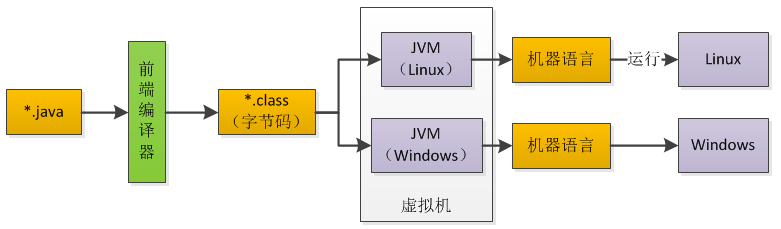
Java的一大特性是跨平台,而Java是如何做到跨平台的呢?
主要依赖Java虚拟机,具体来说,是Java虚拟机在各平台上的实现。
Java虚拟机在不同的平台有不同的实现。同一份字节码,通过运行在不同平台上的Java虚拟机,可以完成相同的处理逻辑。
这样,由不同平台的Java虚拟机屏蔽了不同平台的差异,开发者无需针对不同的平台编写不同的代码。
而字节码,即class文件,由Java代码编译而来。
前端编译、解释、后端运行时编译
字节码,即class文件,由Java代码编译而来。这里的编译,是前端编译。即在代码运行前就完成了编译。
前端编译主要包括:
- 词法分析
- 语法分析
- 填充符号表
- 注解处理
- 语义分析
- 糖语法分解
- 字节码生成
由于这部分开发人员干涉得不多,不作过多讨论。
解释型语言、编译型语言
将代码翻译成机器码的时机的不同,可分为解释型语言和编译型语言:
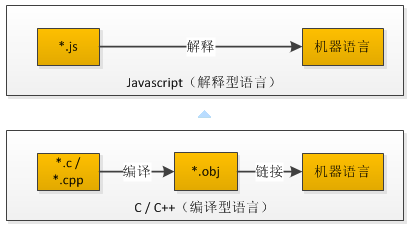
而Java翻译成机器码的过程,既有解释器,又有即时编译器,所以Java属于哪一种语言,有些讨论。


类加载机制
JVM的类加载机制为双亲委派机制,即除了启动类加载器外,其它加载器在加载一个类前都委托父加载器进行加载,当父加载器反馈不在它加载范围内,才尝试自行加载,以保证加载类的唯一性。

public class GetClassLoader {
public static void main(String[] args) {
/* 启动类加载器,按指定文件加载$JAVA_HOME/lib下的文件 */
ClassLoader bootstrapClassLoader = String.class.getClassLoader();
System.out.println("bootstrapClassLoader : " + bootstrapClassLoader);
/* TODO 扩展类加载器,加载$JAVA_HOME/lib/ext下的文件 */
/* 应用程序类加载器,加载CLASSPATH下的文件 */
ClassLoader applicationClassLoader = GetClassLoader.class.getClassLoader();
System.out.println("applicationClassLoader : " + applicationClassLoader);
}
}
结果:
bootstrapClassLoader : null
applicationClassLoader : sun.misc.Launcher$AppClassLoader@73d16e93
双亲委派机制
首先介绍双亲委派机制,除了启动类加载器,其它类加载器都有父类加载器,当一个类加载器接收到一个加载请求时,其首先委托其父类加载器去尝试加载,只有其父类加载器反映无法加载时,才由其自身加载。(当然,父类加载器也有其父类加载器,会级联向上委托)。
而类加载器向上委托,并未通过继承机制实现,而是通过组合方式实现。(为什么呢?)
细节可查看ClassLoader.loadClass(String name, boolean resolve):
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
ClassLoader.loadClass(String name, boolean resolve)通过父ClassLoad加载不成功后,调用自己的findClass(name)去加载类,此方法无具体实现,用的是模板方法模式。
自定义ClasdLoad
上面说到ClassLoad的findClass(name),我们自定义的ClassLoad就可重写此方法去加载类,比如:
package com.nicchagil.jvmexercise.classloader;
import java.io.ByteArrayOutputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
public class MyClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] bytes = null;
/* 从指定路径读取Class */
try (FileInputStream fis = new FileInputStream(
"D:/my_classload_classpath/" + name + ".class")) {
/* 读取字节 */
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int ch = 0;
while (-1 != (ch = fis.read())) {
baos.write(ch);
}
bytes = baos.toByteArray();
} catch (FileNotFoundException e) {
throw new ClassNotFoundException(e.getMessage());
} catch (Exception e) {
throw new RuntimeException(e);
}
/* 读取不到Class */
if (bytes == null) {
throw new ClassNotFoundException();
}
return this.defineClass(name, bytes, 0, bytes.length);
}
/**
* 打印ClassLoad层级
* @param classLoader 类加载器
*/
public static void printClassLoadHierarchy(ClassLoader classLoader) {
int depth = 0;
System.out.println("depth " + ++depth + " : " + classLoader);
ClassLoader parentClassLoader = null;
do {
parentClassLoader = classLoader.getParent();
System.out.println("depth " + ++depth + " : " + parentClassLoader);
classLoader = parentClassLoader;
} while (classLoader != null);
}
public static void main(String[] args) throws Exception {
MyClassLoader myClassLoader = new MyClassLoader();
Class<?> clazz = myClassLoader.loadClass("User");
System.out.println("clazz.newInstance() : " + clazz.newInstance());
System.out.println("clazz.getClassLoader() : " + clazz.getClassLoader());
System.out.println("打印ClassLoad层级:");
printClassLoadHierarchy(myClassLoader);
}
}
上次用自定义的ClassLoad加载的类,记得不要放在类路径下,不然会被AppClassLoader加载,双亲委派机制嘛!
结果:
clazz.newInstance() : User [name=Nick Huang]
clazz.getClassLoader() : com.nicchagil.jvmexercise.classloader.MyClassLoader@15db9742
打印ClassLoad层级:
depth 1 : com.nicchagil.jvmexercise.classloader.MyClassLoader@15db9742
depth 2 : sun.misc.Launcher$AppClassLoader@73d16e93
depth 3 : sun.misc.Launcher$ExtClassLoader@7852e922
depth 4 : null
引申:ClassNotFoundException与NoClassDefFoundError的区别
最重要的区别,ClassNotFoundException是异常,并且为检查异常,即预料有可能发生的异常。
而NoClassDefFoundError是错误,是一件严重的事情。而它什么时候发生,最好去看下NoClassDefFoundError的类描述,那儿说得很清楚。这里简述:在代码中方法调用,或通过new关键字去实例化一个类,JVM或类加载器去加载类定义时无法找到类定义,就会抛出。此类定义在编译时存在,但运行时找不到。
下面,写一个ClassNotFoundException的例子:
public class ClassNotFoundExceptionExercise {
public static void main(String[] args) {
try {
Class.forName("java.lang.StringX");
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
结果:
java.lang.ClassNotFoundException: java.lang.StringX
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at com.nicchagil.jvmexercise.classnotfound.ClassNotFoundExceptionExercise.main(ClassNotFoundExceptionExercise.java:7)
为什么要双亲委派机制
如果没有双亲委派机制,试想一下,java.lang.String这个类由启动类加载器加载了,然而你在ClassPath上自定义一个java.lang.String,并由应用程序类加载器去加载,这样就存在两个java.lang.String。这样,通过包路径+类名定义的类唯一性原则不就被破坏了吗?
对于,我们对类加载有其它个性化需求,比如从网络中加载某些类,可以自定义类加载器。
比如Tomcat的实现,有自定义类加载器(绿色部分):
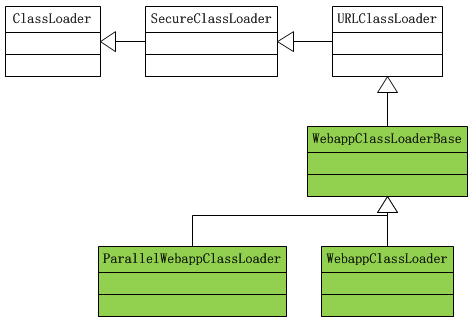
而为什么Tomcat需要自定义类加载器,其中一个原因是各个Web应用之间的隔离问题。
关于Tomcat与ClassLoader,有篇文章写得不错:浅议tomcat与classloader
运行时内存
运行时内存,可粗分为两大块看:线程私有的内存区和线程共享的内存区:

而线程共享区域为堆,堆是JVM内存分配和垃圾回收机制的作用区域,是非常受关注的一部分:可分为新生代区、老年代区、永久代区。这里后续细作讨论。
如何确定对象是否有引用
通常确认对象能否有引用,主要有两种做法:引用计数法、可达性分析法。
引用计数法,就是用计数器计算一个对象被引用的次数,此方法简单,但不好解决依赖的问题。
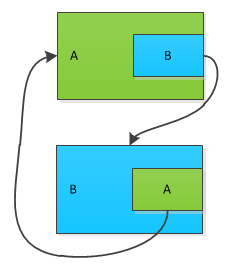
可达性分析法,是JVM的运用方案,从指定的根节点往下寻找,能被根节点直接或间接连接的对象则有引用,否则无引用。
如何确定对象能否被GC
当对象没有引用,并不是立即被GC,而需要通过某些逻辑,也就是仍有挽救机会。

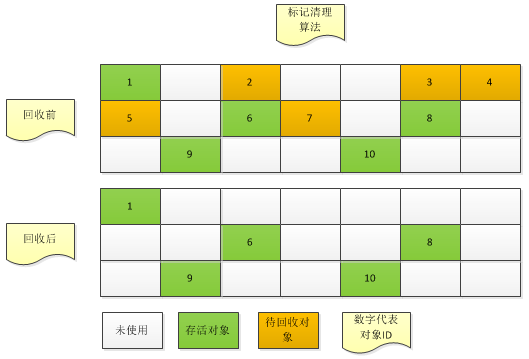
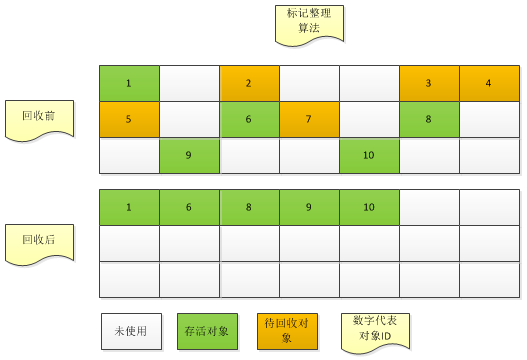
回收空间的基础算法
确定哪些对象需要GC,根据不同区域的特点,可运用不同的空间回收算法。比如新生代区,因其特点为存活的对象总数不多,复制代码不高,常用复制算法,而老年代区,常用标记-清除算法或其升级版标记-整理算法。

即时编译哪些代码
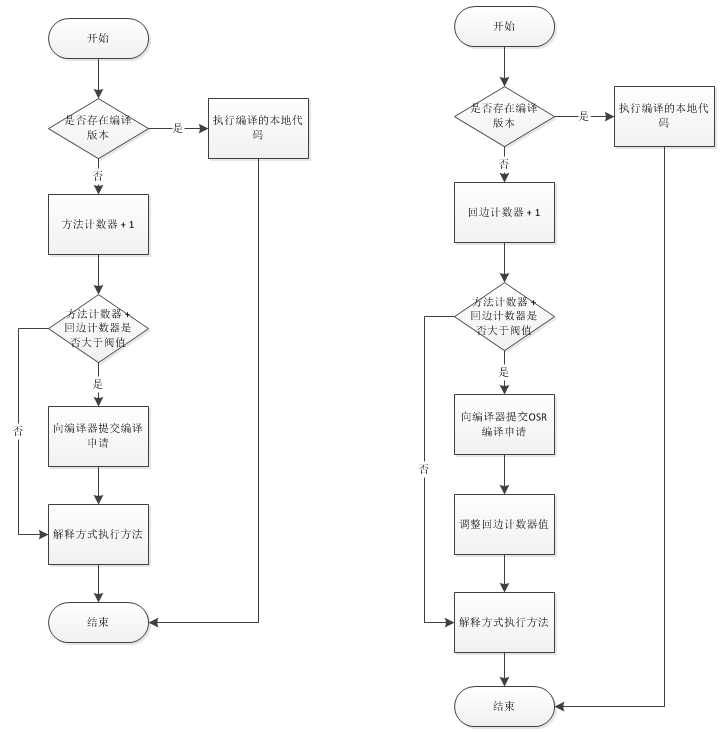
HotSpot虚拟机的HotSpot,为热点的意思。之前介绍将翻译成机器码有解释和即时编译两种手段。
解释,是直译。
而即时编译,则经过优化的编译。当然,翻译时间比较长,但运行效率比较高。即时编译按照程度不同,有C1和C2两个级别,C2级别优化程度更高,常用于服务器模式运行JVM。
既然即时编译相对耗时,当然优先对较频繁执行的代码进行翻译,以下流程图简单描述识别热点代码:
垃圾收集器
JVM有很多种垃圾收集器,它们各具特点,用户根据场景选择合适的收集器。对于响应时间有一定要求的应用,多用CMS收集器和G1收集器,这里主要讨论它们。
CMS收集器
CMS,Concurrent Mark Sweep,即并发标记清除,从名字可知,使用的是标记清除算法,并且是并发的。
那么是如何并发的呢?是全程并发执行,还是部分步骤并发的呢?下面是CMS收集的几个步骤:
- 初始标记。仅标记
GC Roots直接引用的对象。(串行,耗时短) - 并发标记。对于
GC Roots引用的对象进行深层次的可达性分析。(并发,耗时长) - 重新标记。因
并发标记是并发执行的,在标记过程中难免对象的引用有所变动,重新标记用于修正并发标记期间的变动。(串行,耗时短) - 并发清除。清除标记的对象。(并发,耗时长)
了解了CMS收集的运作,可以发现它的缺点:
- 它有
标记清除算法的缺点,就是容易形成不连续的可用内存块 - 有浮动垃圾。在
并发清除阶段,由于是并发执行的,执行过程中其它代码的运行有可能产生新的可回收对象。
G1收集器
G1,Garbage First,即垃圾优先,意为回收价值高的垃圾优先回收。适用于响应时间高、大内存、多CPU的环境。
它有几个特点:
- 利用多CPU缩短
Stop The World的时间 - 运用
标记整理算法和复制算法 - 可预测停顿时间
一些改变:
- 之前的收集器专用于
新生代区或老年代区的收集,而这两个区域G1都能收集。内存布局也有所改变,虽还有新生代区或老年代区的概念,但不再从物理区域上划分,而是由可能非连续的内存区域组成新生代区或老年代区。 - 在每个Region维护
Remember Set,在写入引用类型时,如果引用的对象处于其它Region,即将引用对象信息写入Remember Set,这样,在做可达性分析时,对Remember Set也作可达性分析,则可避免全堆扫描。
收集步骤与CMS收集器差不多,比较大的差别在于最后一个步骤筛选回收,根据用户期待的回收时间收集对象,全部步骤如下:
- 初始标记。仅标记
GC Roots直接引用的对象。(串行,耗时短) - 并发标记。对于
GC Roots引用的对象进行深层次的可达性分析。(并发,耗时长) - 重新标记。因
并发标记是并发执行的,在标记过程中难免对象的引用有所变动,重新标记用于修正并发标记期间的变动。(串行,耗时短) - 筛选回收。(并发,耗时长)
JVM参数
打印gc日志
当前文件路径下生成名为gc.log的gc日志:
-Xloggc:gc.log # 输出指定路径、名称的日志
-XX:+PrintGCDetails # 打印详细日志
-XX:+PrintGCDateStamps # 打印日志时打印系统时间
运行模式(Server模式、Client模式)
JVM运行模式分Server模式和Client模式,可通过修改的jvm.cfg文件中-server KNOWN和-client KNOWN的先后顺序切换模式,此文件在我的电脑上位于D:\green\jdk1.8.0_25\jre\lib\amd64\jvm.cfg。
注:我的JDK版本是1.8,默认是使用Server模式:
-server KNOWN
-client IGNORE
而查询当前JDK使用哪个模式:
C:\>java -version
java version "1.8.0_25"
Java(TM) SE Runtime Environment (build 1.8.0_25-b18)
Java HotSpot(TM) 64-Bit Server VM (build 25.25-b02, mixed mode)
使用指定收集器
-XX:+UseG1GC # 使用G1收集器
-XX:+UseConcMarkSweepGC # 使用CMS收集器
内存大小设置
-Xms512m # 最小堆512M
-Xmx512m # 最大堆512M
-Xss512k # 每个线程的栈(Stack Space)大小
生成堆转储文件
当内存溢出时,需导出堆转储快照分析异常,记得提前建好目录d:/dump/:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=d:/dump/
会导出java_pid进程号.hprof的文件,我一般用Memory Analyzer(MAT)进行分析。如果快照太大,可能会不够内存打开,可在MemoryAnalyzer.ini调整最大堆大小。
运行时,也可以通过jmap工具导出堆转储快照:
# 查询Java的进程列表
jps
# 导出堆转储快照
jmap -dump:format=b,file=D:\dump_workspace\mydump_20170715-5 进程ID
日志格式
G1日志
用JVM参数-Xloggc:gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps,得到详细的gc日志。
日志头部,包含JVM环境、版本、内存、参数等信息:
Java HotSpot(TM) 64-Bit Server VM (25.131-b11) for windows-amd64 JRE (1.8.0_131-b11), built on Mar 15 2017 01:23:53 by "java_re" with MS VC++ 10.0 (VS2010) # JVM的环境,如JVM版本
Memory: 4k page, physical 8268588k(4642384k free), swap 16535316k(12403048k free) # 内存信息,如物理内存的总量、可用量,交换区内存的总量、可用量
CommandLine flags: -XX:InitialHeapSize=268435456 -XX:MaxHeapSize=1073741824 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseG1GC -XX:-UseLargePagesIndividualAllocation -XX:+UseStringDeduplication # 运行的JVM参数
新生代GC:
2017-07-04T23:31:13.837+0800: 0.388: [GC pause (G1 Evacuation Pause) (young), 0.0114754 secs] # 在显示时间(JVM启动0.388秒后),发生新生代GC
[Parallel Time: 2.8 ms, GC Workers: 4]
[GC Worker Start (ms): Min: 387.7, Avg: 387.7, Max: 387.8, Diff: 0.1]
[Ext Root Scanning (ms): Min: 0.2, Avg: 1.0, Max: 2.7, Diff: 2.5, Sum: 3.9]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.1]
[Object Copy (ms): Min: 0.0, Avg: 1.7, Max: 2.4, Diff: 2.4, Sum: 6.7]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.2]
[Termination Attempts: Min: 1, Avg: 3.5, Max: 7, Diff: 6, Sum: 14]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 2.7, Avg: 2.8, Max: 2.8, Diff: 0.1, Sum: 11.0]
[GC Worker End (ms): Min: 390.4, Avg: 390.4, Max: 390.5, Diff: 0.0]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[String Dedup Fixup: 0.2 ms, GC Workers: 4]
[Queue Fixup (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Table Fixup (ms): Min: 0.0, Avg: 0.0, Max: 0.2, Diff: 0.2, Sum: 0.2]
[Clear CT: 0.0 ms]
[Other: 8.4 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.5 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.0 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]
[Eden: 12.0M(12.0M)->0.0B(15.0M) Survivors: 0.0B->2048.0K Heap: 12.0M(256.0M)->2826.0K(256.0M)] # 伊甸区的使用量和总量在GC前后的变化、存活区的内存变化、堆的使用量和总量在GC前后的变化
[Times: user=0.01 sys=0.00, real=0.02 secs] # 实际花费了0.02秒
老年代GC:
2017-07-05T14:13:49.219+0800: 26.825: [GC pause (G1 Humongous Allocation) (young) (initial-mark), 0.0170832 secs] # 初始标记
...etc...
[Eden: 30.0M(92.0M)->0.0B(86.0M) Survivors: 12.0M->5120.0K Heap: 153.4M(256.0M)->127.1M(256.0M)]
[Times: user=0.06 sys=0.00, real=0.02 secs]
2017-07-05T14:13:49.237+0800: 26.842: [GC concurrent-root-region-scan-start] # 并发扫描开始
2017-07-05T14:13:49.244+0800: 26.850: [GC concurrent-string-deduplication, 1633.0K->271.8K(1361.2K), avg 62.3%, 0.0077193 secs]
2017-07-05T14:13:49.247+0800: 26.852: [GC concurrent-root-region-scan-end, 0.0101110 secs] # 并发扫描结束
2017-07-05T14:13:49.247+0800: 26.852: [GC concurrent-mark-start] # 并发标记开始
2017-07-05T14:13:49.425+0800: 27.030: [GC concurrent-mark-end, 0.1781354 secs] # 并发标记结束
2017-07-05T14:13:49.432+0800: 27.038: [GC remark 27.038: [GC ref-proc, 0.0026288 secs], 0.0112982 secs] # 二次标记
[Times: user=0.06 sys=0.00, real=0.01 secs]
2017-07-05T14:13:49.444+0800: 27.050: [GC cleanup 157M->151M(256M), 0.0004895 secs] # 清除
[Times: user=0.00 sys=0.00, real=0.00 secs]
2017-07-05T14:13:49.444+0800: 27.050: [GC concurrent-cleanup-start] # 并发清除开始
2017-07-05T14:13:49.444+0800: 27.050: [GC concurrent-cleanup-end, 0.0000132 secs] # 并发清除结束
JVM工具
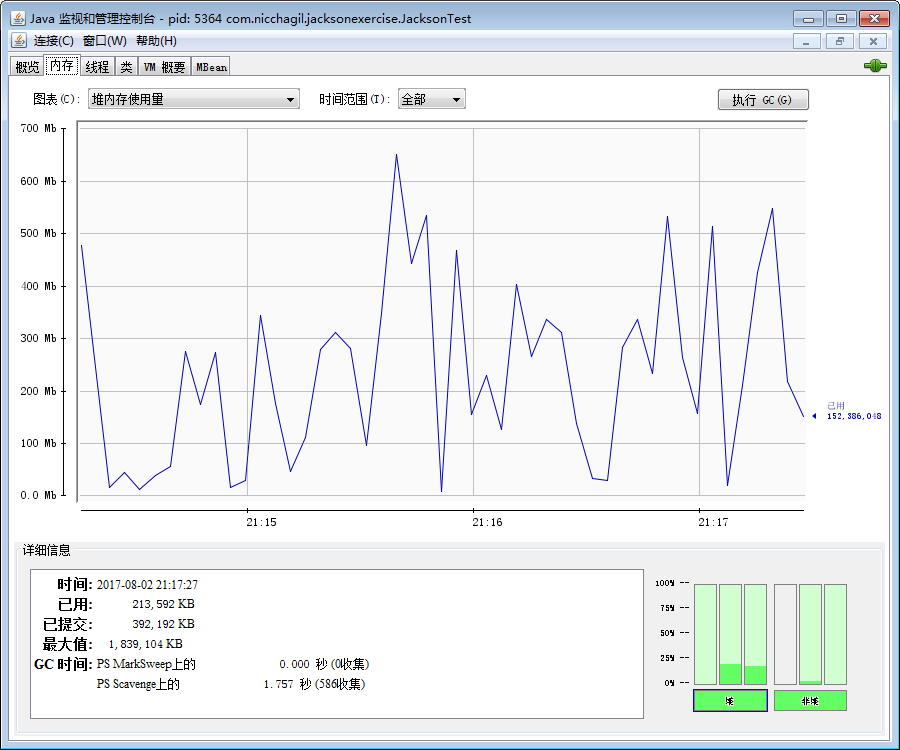
jconsole
运行$JAVA_HOME/bin/jconsole.exe即可:
概览页签:

内存页签:
可选择:堆内存使用量、非堆内存使用量、内存池“PS Old Gen”、内存池“PS Eden Space”、内存池“PS Surviver Space”、内存池“Metaspace”、内存池“Code Cache”、内存池“Compressed Class Space”
线程页签:

类页签:
VM概要页签:
MBean页签:
jvisualvm
运行$JAVA_HOME/bin/jvisualvm.exe即可:
概述:
监视:
线程:
抽样器:

Profiler:

MAT
手动导出快照:
jmap -dump:format=b,file=D:\dump_workspace\mydump_20170715-5 进程ID
或者设置OOM并发生了然后导出了快照,可以用MAT查看、分析快照:


内存泄漏
如下图,每个谷底(即Full GC)的值没有递增,说明没有内存泄漏,如果谷底有递增,即说明有可能内存泄漏:
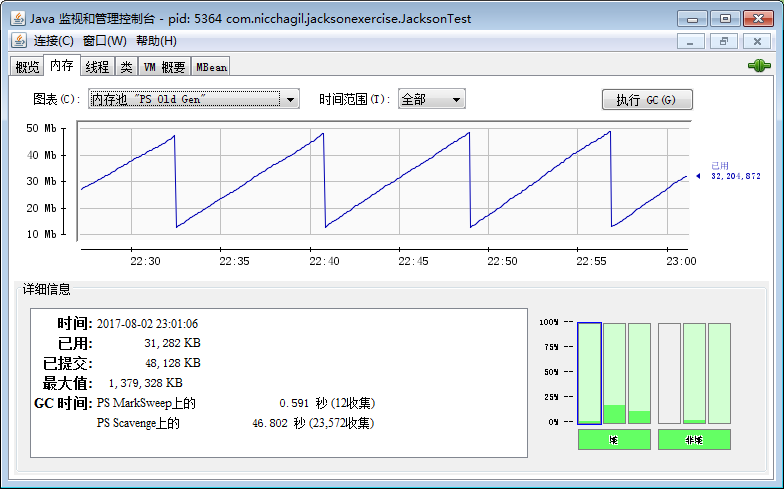
如果怀疑有内存泄漏,用MAT分析快照,对比快照,找出并分析可疑代码。
本博客为学习、笔记之用,以笔记形式记录学习的知识与感悟。学习过程中可能参考各种资料,如觉文中表述过分引用,请务必告知,以便迅速处理。如有错漏,不吝赐教。
如果本文对您有用,点赞或评论哦;如果您喜欢我的文章,请点击关注我哦~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号