指标系统计算架构设计
前言
前一篇《指标管理系统设计》,我讲了指标体系要解决的问题,以及指标系统宏观搭建和模型上的设计。其中对具体实施时的计算存储架构说的不是特别清楚。这一篇,我将着重介绍指标计算架构的设计。
过往的一些实现问题
指标体系跟标签体系其实有些类似,都有很多的字段,甚至在某种程度上,他们还可以成为依托关系。比如标签系统可以使用指标体系作为数据基础,当然这是题外话。这里列举下我之前参与的标签系统和一些报表开发所存在的问题。
下图是一个标签系统的的标签加工逻辑片段,这个脚本一次性的将标签体系中的所有标签挨个计算出来

下图是一个报表sql的脚本片段,它也一次性计算出了该表报的多个字段,有很复杂的加工逻辑
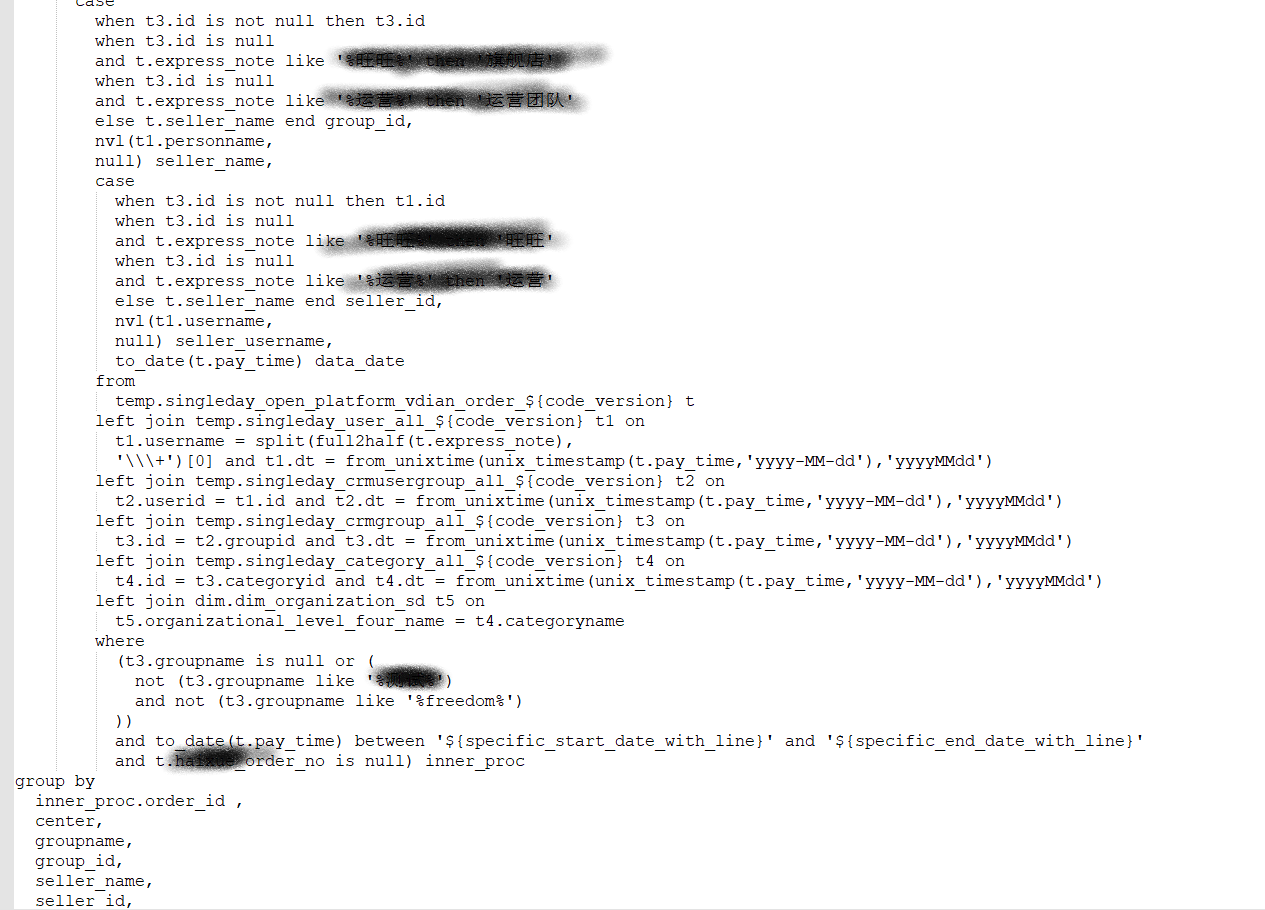
从软件设计的角度来看,上述的开发方式耦合度很高,这会带来一些列的问题
- 所有逻辑耦合在一起,后续阅读理解很困难
- 要下线、新增、更新一个指标/标签需要更改原来的脚本,代价较高,出现bug时还会影响之前的指标/标签
- 多个报表拥有相同口径的指标时,该指标的加工逻辑需要在多个报表中重复编写,修改时也需要多处修改,难免挂一漏万
计算架构设计
对于上述问题,解决的主要思想是,低耦合高内聚。将报表拆散到指标粒度,计算存储的单元不是报表,而是指标。从而让指标的复用性增强,也是的对单个指标增删改的效率更高,提升整个系统的稳健性。
整个计算架构分为如下图的四层
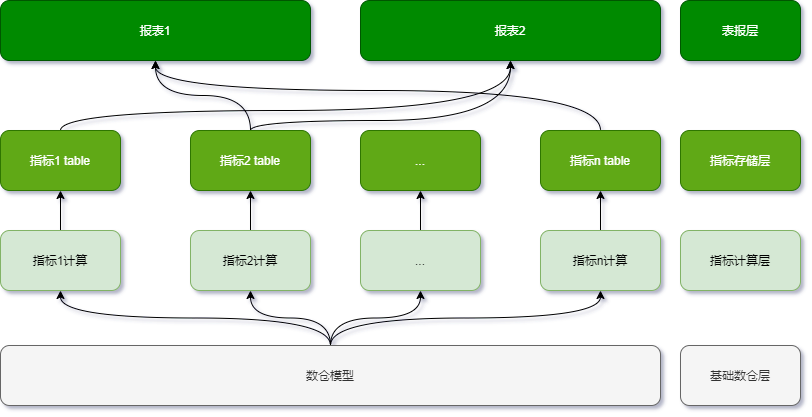
- 基础数仓层,这一层主要是数仓模型
- 指标计算层,一个指标一个计算任务(任务可以是sql或其他加工脚本代码),它基于底层的基础数仓层进行加工
- 指标存储层,每一个加工好的指标,都有一个对应的表来存储
- 报表层,业务报表的输出,通过灵活的join组合各指标表,即可得出最终的报表
为什么要一个指标一个表
不同指标其使用的维度个数不同,这使得指标结果数据的字段都是不同的,无法统一用一个表来存放所有指标值。比如最近30天各大区的销售额指标,使用了一个维度,大区
| 大区 | 销售额 |
|---|---|
| 华中 | 500000 |
| 华北 | 600000 |
| 华东 | 700000 |
| ... | ... |
而最近30天,各大区,各产品线的销售额度,就使用了两个维度,大区,产品线
| 大区 | 产品线 | 销售额 |
|---|---|---|
| 华中 | 女装 | 10000 |
| 华中 | 男装 | 20000 |
| 华北 | 男装 | 30000 |
| 华北 | 童装 | 40000 |
| ... | ... | ... |
一个表一个指标是否过多
指标只要不重复建设,上万个差不多能覆盖一般公司的所有报表需求。上万个表对于一般的大数据处理系统比如hive来说,没什么大问题。何况这些指标表只是多,并不一定数据量大。
参考资料
https://mp.weixin.qq.com/s/uavKimWskRE8Ea83fv_tpA
https://www.cnblogs.com/niceshot/p/13640630.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号