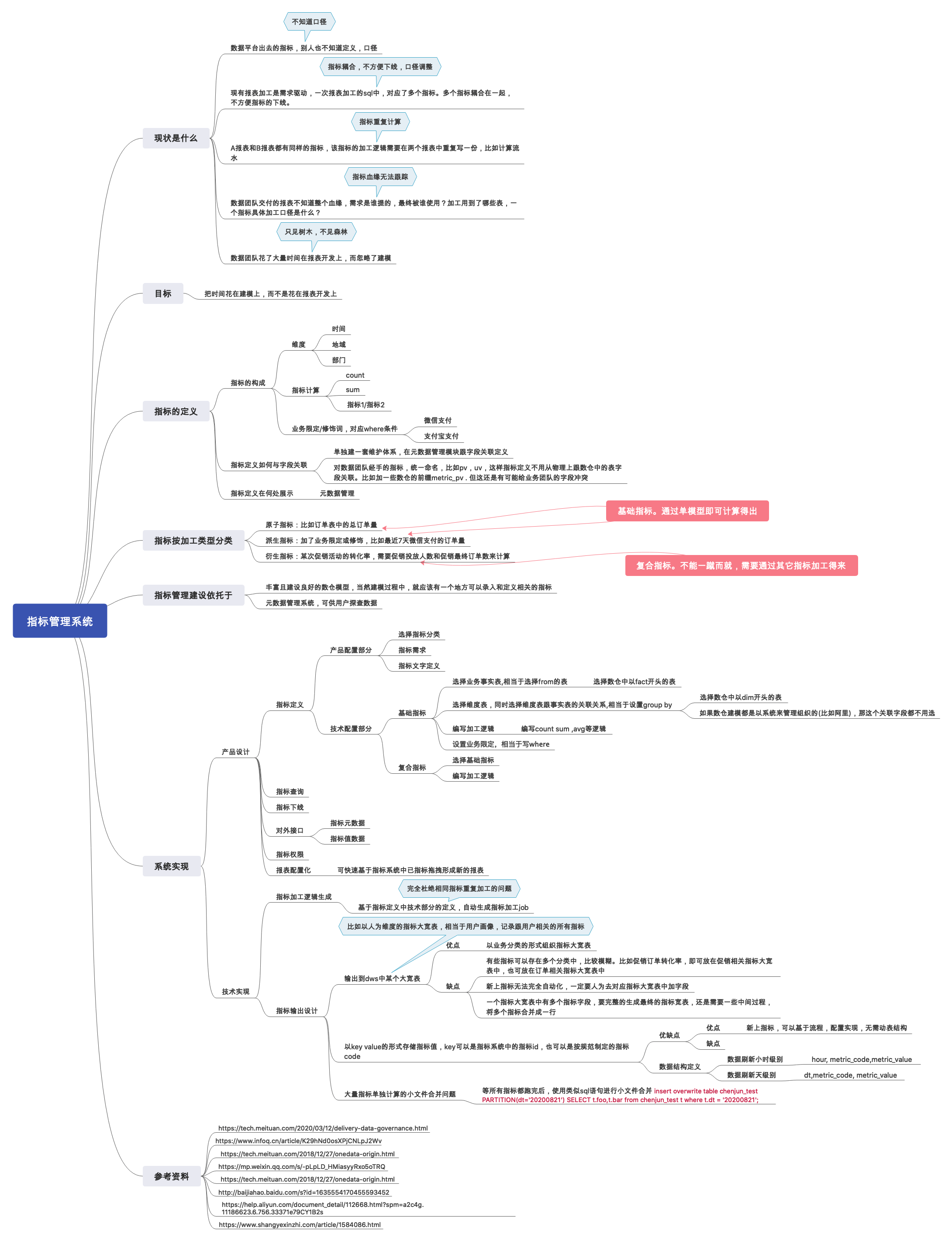
指标管理系统设计
什么是指标
数据团队出具的一个统计报表字段即为指标。比如最近七天的订单量,一个促销活动的购买转化率等等。
一个指标具体到计算实施,主要有以下几部分组成
- 指标加工逻辑,比如count ,sum, avg
- 维度 比如按部门、地域进行指标统计,对应sql中的group by
- 业务限定/修饰词 比如以不同的支付渠道来算对应的指标,微信支付的订单退款率,支付宝支付的订单退款率 。对应sql中的where
除此之外,指标本身还可以衍生、派生出更多的指标,基于这些特点,可以将指标进行分类
- 原子指标 基本业务事实,没有业务限定、没有维度。比如订单表中的订单量、订单总金额都算原子指标
- 派生指标 比如过去5天的订单总金额,就是加了业务时间限定
- 衍生指标 比如某一个促销活动的转化率,就需要
促销投放人数指标同促销订单数指标进行计算得出
指标系统建设前的状况
- 不知道口径,数据平台出去的指标,用户甚至数据研发自己都不知道具体的口径,需要翻代码
- 指标耦合,不方便下线和口径调整,现有报表都是需求驱动,一个sql中可能对应了多个指标的计算,导致指标下线,逻辑调整都要相互影响
- 指标重复计算,不同报表用到同一个指标,需要重复的写同样的逻辑,加重集群的计算压力,且指标口径一调整,需要多处调整
- 指标血缘无法跟踪,数据团队交付的报表时间久了不知道谁提的,不知道用到了哪些表,不知道最终被用到了哪些团队
- 只见树木,不见森林。数据团队花了大量时间在报表开发上,而忽略了底层模型的打磨
指标建设的宏观步骤
基于业务目的梳理指标体系
基于公司不同的业务模块,业务场景,不同的管理层级来梳理指标体系,敲定指标口径。
- 总经办关注的流水相关指标,对应高层管理
- 订单小组关注的订单履约相关的指标,对应业务模块
- 广告投放关注的转化相关的指标,对应业务场景
基于系统支撑录入和管理
通过系统建设,支撑上述梳理的指标体系,实现指标定义录入,指标调用链查询跟踪,指标下线管理等功能
指标管理所在的数仓位置
指标的计算一般是在数仓星型模型之上

指标管理系统产品模块设计
指标定义
分为产品配置部分和技术人员配置部分
产品配配置
- 选择指标分类,属于哪个业务模块
- 指标需求描述,填写指标发起的部门原由
- 指标文字定义,填写指标口径的文字描述
技术配置
将原子指标和派生指标都定义为基础指标,因为他们通过单一数仓模型即可计算出
将衍生指标定义为复合指标,因为这类指标需要依据上述基础指标做加工计算
基础指标
- 需要选择业务事实表,维度表,以及业务事实同维度的关联关系,相当于选定from的表和对应的group by逻辑
- 编写指标加工逻辑,比如count、sum、avg等
- 编写限定条件,相当于写where条件
复合指标
- 选择基础指标,比如选择
促销投放人群数、成单用户数 - 编写加工逻辑,
成单用户数/促销投放人数
指标查询
基于指标中文名,搜索对应的指标定义和血缘
指标下线
基于血缘统计,发现未被使用的指标,将其下线
对外接口
提供给外部系统,比如BI,用于查询指标定义,这指标的详细数据
指标权限
控制不同用户,不同应用能够获取到的不同指标范围
报表配置化
基于指标系统中的指标池,以拖拽的方式,快速生产报表
指标管理系统技术实现
指标加工逻辑
基于指标定义中技术部分的定义,自动生成指标加工sql,并将其自动部署到调度系统中。自动生成的逻辑,无非是将指标定义中的字表加工逻辑、维度信息、业务限定等组装起来
指标输出设计
sql加工好的指标,有如下两种存放方式
在dws中以大宽表的形式存放
比如以用户维度,组织大宽表,其中存放用户相关的所有指标,比如用户最近5天购买的订单数,用户最近30天的订单金额等
缺点是:
- 报表组合不够灵活,某些报表需要的指标跨多个大宽表,还得从多个dws大宽表中取数据
- 新增指标不够灵活,新增一个指标需要在大宽表中加字段
- 由于每个指标都是独立的job,其计算完成的先后顺序不一,需要做一些中间存储,最后合并成大宽表
以统一的指标表存放所有的指标数据
对于T+1的指标,统一存放到一个指标表中,统一指标表的定义如下
| 指标id | 指标code | 指标value | 日期分区 |
|---|
所有的指标job计算完后,都以上述格式将指标数据插入到对应的表中,一个job一次插入,会造成该表的小文件问题。解决办法是,可以在所有的指标计算完成后,统一对当天的指标分区做一次小文件合并,合并sql类似
insert overwrite table chenjun_test PARTITION(dt='20200821') SELECT t.foo,t.bar from chenjun_test t where t.dt = '20200821';
整体脑图
参考资料
https://tech.meituan.com/2020/03/12/delivery-data-governance.html
https://www.infoq.cn/article/K29hNd0osXPjCNLpJ2Wv
https://tech.meituan.com/2018/12/27/onedata-origin.html
https://mp.weixin.qq.com/s/-pLpLD_HMiasyyRxo5oTRQ
https://tech.meituan.com/2018/12/27/onedata-origin.html
http://baijiahao.baidu.com/s?id=1635554170455593452
https://help.aliyun.com/document_detail/112668.html?spm=a2c4g.11186623.6.756.33371e79CY1B2s
https://www.shangyexinzhi.com/article/1584086.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号