django查询数据和orm优化
聚合查询
'聚合查询通常情况下都是配合分组一起使用的'
# 聚合函数查询关键字
aggregate
# 聚合函数
Max : 最大值
Min : 最小值
Sum : 求合
Count : 计数
Avg : 平均值
# 聚合函数的使用
from app01 import models
from django.db.models import Max,Min,Sum,Count,Avg
1.查询所有书籍的最高价格
res = models.Book.objects.aggregate(Max('price'))
'''{'price__max': Decimal('5646.21')}'''
# 聚合函数的一致使用
res = models.Book.objects.aggregate(Max('price'), Min('price'), Sum('price'), Count('pk'), Avg('price'))
print(res)
'''{'price__max': Decimal('5646.21'), 'price__min': Decimal('222.21'), 'price__sum': Decimal('7209.17'), 'pk__count': 5, 'price__avg': 1441.834}'''
分组查询
# 分组查询
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数,所有使用前要从django.db.models引入Avg,Max,Count,Sum(首字母大写))
# 返回值
分组后,用values取值,则返回值是QuerySet书籍类型里面为一个个字典
分组后,用values_list取值,则返回值是QuerySet数据类型里面为一个个元组
'MySQL中的limit相当于ORM中的QuerySet数据类型的切片'
# 分组查询的特点
values 或者 values_list 放在 annotate 前面:values 或者 values_list 是声明以什么字段分组,annotate 执行分组
values 或者 values_list 放在annotate后面: annotate 表示直接以当前表的pk执行分组,values 或者 values_list 表示查询哪些字段, 并且要将 annotate 里的聚合函数起别名,在 values 或者 values_list 里写其别名
filter放在 annotate 前面:表示where条件
filter放在annotate后面:表示having
'''ORM执行分组操作 如果报错 可能需要去修改sql_mode 移除only_full_group_by'''
分组查询练习
from django.db.models import Max, Min, Sum, Count, Avg
# 统计每本书的作者个数
res = models.Book.objects.annotate(author_num=Count('authors__pk')).values('title', 'author_num')
# 统计每个出版社卖的最便宜的书的价格
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name','min_price')
# 统计不止一个作者的图书
res = models.Book.objects.annotate(author_num=Count('authors__pk')).filter(author_num__gt=1).values('title','author_num')
# 统计每个作者出的书的总价格
res = models.Author.objects.annotate(book_sum_price=Sum('book__price')).values('name','book_sum_price')
'以表中的某个字段分组如何操作'
models.Author.objects.values('age').annotate()
# 统计每个出版社主键值对应的书籍个数
res = models.Book.objects.values('publish_id').annotate(book_num=Count('pk')).values('publish_id','book_num')
迁移数据
# 当表中已经有数据的情况下 添加额外的字段 需要指定默认值或者可以为null
方式1
IntegerField(verbose_name='销量',default=1000)
方式2
IntegerField(verbose_name='销量',null=True)
方式3
在迁移命令提示中直接给默认值
F与Q查询
F查询
# F查询的作用
能够帮助你直接获取到列表中某个字段对应的数据
# 查询库存大于销量的书籍
from django.db.models import F
res = models.Book.objects.filter(kucun__gt=F('maichu'))
# 将所有书的价格提升500
res = models.Book.objects.update(price=F('price') + 500)
'在操作字符串类型的数据的时候, F不能够直接做到字符串的拼接'
# 将所有书的名称后面加上_爆款后缀
from django.db.models.functions import Concat
from django.db.models import Value
res = models.Book.objects.update(name=Concat(F('title'), Value('爆款')))
Q查询
# Q查询的作用
filter括号内多个条件默认是and关系 无法直接修改
使用Q对象 就可以支持逻辑运算符
# 查询价格大于20000或者卖出大于1000的书籍
from django.db.models import Q
',逗号是and关系'
res = models.Book.objects.filter(Q(price__gt=20000), Q(maichu__gt=1000))
'|管道符是or关系'
res = models.Book.objects.filter(Q(price__gt=20000) | Q(maichu__gt=1000))
'~波浪符是not操作'
res = models.Book.objects.filter(~Q(price__gt=20000))
Q查询进阶用法
'能够将查询条件的左边也变成字符串的形式 而 不是变量形式'
'children里面添加的是元组'
q_obj = Q() # 先产生一个空对象 实例化
q_obj.connector = 'or' # 默认是and 可以改为or
'q对象里面有一个children'
q_obj.children.append(('maichu__gt', 100))
# 第一个元素就会被当作查询条件的左边 第二个元素会被当作查询条件右边
q_obj.children.append(('price__lt', 600))
res = models.Book.objects.filter(q_obj) # filter 除了可以放条件 还可以放对象
print(res.query)

ORM查询优化
# ORM语句特点
1.orm查询默认都是惰性查询(能不消耗数据库资源就不消耗)
光编写orm语句并不会直接指向SQL语句 只有后续的代码用到了才会执行
2.orm查询默认自带分页功能(尽量减轻单次查询数据的压力)
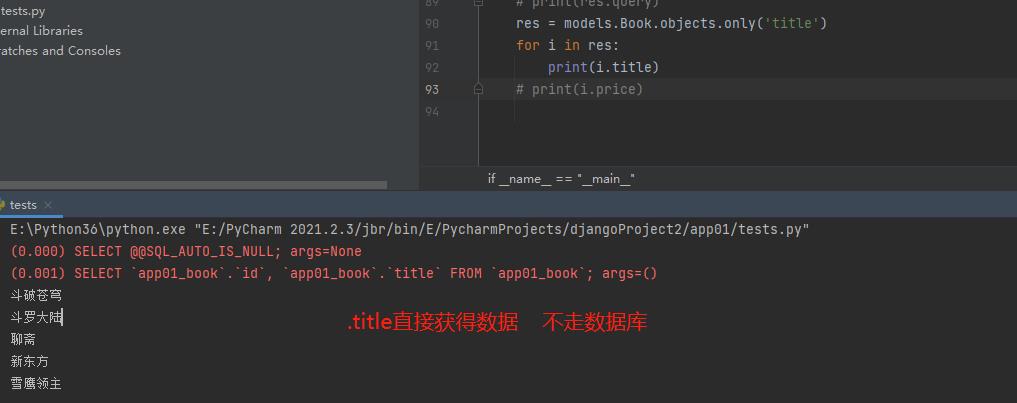
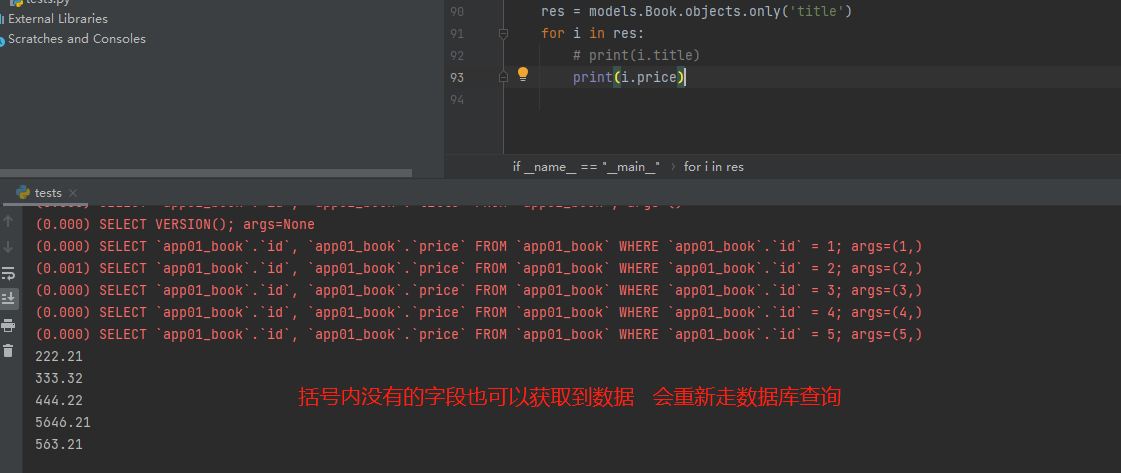
only
# only的用法
会产生对象结果集 对象点括号内出现的字段不会再走数据库查询
但是如果点击了括号内没有的字段也可以获取到数据 但是每次都会走数据库查询
res = models.Book.objects.only('title')
for i in res:
print(i.title) '点only括号内的字段 不会走数据库'
print(i.price) '点only括号内没有的字段 会重新走数据库查询 '
defer
# defer的用法
defer与only刚好相反 对象点括号内出现的字段会走数据库查询
如果点击了括号内没有的字段也可以获取到数据 每次都不会走数据库查询
res = models.Book.objects.defer('title')
for i in res:
print(i.title)
'''对象除了没有title属性之外 其他的都有,除了title走数据库,其他都不需要走数据库'''
# select_related
1.select_related内部直接先将book与publish连接起来
2.然后一次性将大表里面的所有数据全部封装给查询出来的对象
3.这个时候对象无论是点击book表数据还是publish的数据都无需再走数据库查询了
'select_related括号内只能传一对一和一对多字段 不能传多对多字段'
res = models.Book.objects.select_related('publish') # INNER JOIN
for i in res:
print(i.publish.name)
# prefetch_related
prefetch_related该方法内部其实就是子查询
将子查询查询出来的所有结果也给你封装到对象中
给你的感觉好像也是一次性搞定的
res = models.Book.objects.prefetch_related('publish') # 子查询
for i in res:
print(i.publish.name)
'''
# 总结
select_related:
相当于是INNER JOIN 将两张表拼接起来
prefetch_related:
相当于是 子查询 分布查询
'''
ORM常见字段
# AutoField int自增列
int自增列,必须填入参数primary_key=True
当model中如果没有自增列,则自动会创建一个列名为id的列
# CharField varchar
verbose_name 字段的注释
max_length 字符长度
# IntegerField int
BigIntegerField bigint
# DecimalField decimal
max_digits=8 总共位数
decimal_places=2 小数位
#EmailFiled varchar(254)
# DateField date
日期字段,日期格式 YYYY-MM-DD
相当于Python中的datetime.date()
#BooleanField(Field) 布尔值类型
该字段传布尔值(False/True) 数据库里面存0/1
#TextField(Field) 文本类型
存储大段文本 没有字数限制
#FileField() 字符类型
传文件自动保存到指定位置并存文件路径
自定义字段类型
'django除了提供了很多字段类型之外 还支持你自定义字段'
class MyCharField(models.Field): # 字段类内部都继承Field
def __init__(self, max_length, *args, **kwargs):
self.max_length = max_length
super().__init__(max_length=max_length, *args, **kwargs)
def db_type(self, connection):
# 返回真真正的数据类型及各种约束条件
return 'char(%s)' % self.max_length
# 自定义字段使用
myfield = MyCharField(max_length=16,null=True) # 可以为空
ORM重要参数
# unique=True
ForeignKey(unique=True) 等价于 OneToOneField()
# db_index
如果db_index=True 则代表着为此字段设置索引
# to_field
设置要关联的表的字段 默认不写关联的就是另外一张的主键字段
# on_delete
当删除关联表中的数据时,当前表与其关联的行的行为
"""
django2.X及以上版本 需要你自己指定外键字段的级联更新级联删除
"""
# default
为该字段设置默认值。
# auto_now_add
配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库
# auto_now
配置上auto_now=True,每次更新数据记录的时候会更新该字段
# choices
用于可以被列举完全的数据
eg:性别 学历 工作经验 工作状态
class User(models.Model):
username = models.CharField(max_length=32)
password = models.IntegerField()
gender_choice = (
(1,'男性'),
(2,'女性'),
)
gender = models.IntegerField(choices=gender_choice)
user_obj.get_gender_display()
# 有对应关系就拿 没有还是本身
"""
1.字段存什么,根据gender_choices内元组的第一个元素,
2.元素如果是数字就放一个数字类型的字段
3.元素如果是字符串就放一个字符串类型的字段
"""
# 验证 choices取值对应关系
user_obj = models.User.objects.filter(pk=1).first()
print(user_obj.get_gender_display())
'如果没有对应关系 那么字段是什么就展示什么 不会报错'

事务操作
# 事务的四大特征(ACID)
A: 原子性
每个事务都是不可分割的最小单位(同一个事物内的多个操作要么同时成功要么同时失败)
C: 一致性
事物必须是使数据库从一个一致性状态编导另一个一致性状态,一致性与原子性使密切相关的
I: 独立性
事物与事物之间彼此不干扰
D: 持久性
一个事物一旦开启,它对数据库中书籍的改变就应该使永久性的
# 开启事务
1.transaction 开启事务
2.rollback 回滚
3.commit 确认
from django.db import transaction
try:
with transaction.atomic():
pass
except Exception:
pass
ORM执行原生SQL
# 方式1
from django.db import connection, connections
cursor = connection.cursor()
cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
cursor.fetchone()
# 方式2
models.UserInfo.objects.extra(
select={'newid':'select count(1) from app01_usertype where id>%s'},
select_params=[1,],
where = ['age>%s'],
params=[18,],
order_by=['-age'],
tables=['app01_usertype']
)
多对多三种创建方式
全自动创建
'利用orm自动帮我们创建第三张关系表'
class Book(models.Model):
name = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author')
# 全自动创建优缺点
优点: 代码不需要自己写 非常方便 还支持orm提供操作第三张关系表的方法
缺点: 第三张关系表的扩展性极差(没办法额外添加字段)
纯手动创建
class Book(models.Model):
name = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Model):
book_id = models.ForeignKey(to='Book')
author_id = models.ForeignKey(to='Author')
# 纯手动创建优缺点
优点: 第三张表完全取决你自己进行额外的扩展
缺点: 需要写的代码较多,不能再使用orm提供的简单的方法
半自动创建
'可以使用orm的正反向查询 但是没法使用add,set,remove,clear这四个方法'
class Book(models.Model):
title = models.CharField(max_length=32)
authors = models.ManyToManyField(
to='Author',
through='Book2Author', # 指定表
through_fields=('book','author') # 指定字段
)
class Author(models.Model):
name = models.CharField(max_length=32)
'''多对多建在任意一方都可以 如果建在作者表 字段顺序互换即可'''
books = models.ManyToManyField(
to='Author',
through='Book2Author', # 指定表
through_fields=('author','book') # 指定字段
)
class Book2Author(models.Model):
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
#through
告诉orm我跟作者是多对多的关系 我是通过我自己写的表创建关系的 该表Book2Author 创建关系
#through_fields
告诉orm书籍跟作者是通过book,author字段来绑定关系的


 浙公网安备 33010602011771号
浙公网安备 33010602011771号