python for循环和数据类型的内置方法
while与else连用
#while与else连用
for/else
仅当for循环执行完毕(没有被break中断)时运行else块。
while/else
仅当while因条件为假而退出(即没有被break中断)时运行else块
"""
while 条件:
循环体代码
else:
循环体代码正常运行结束 则会执行该子代码块
"""
#代码示例:
count = 1
while count < 10:
print(count)
count += 1
else:
print('while循环结束输出')
死循环和while嵌套循环
#死循环:在编程中,一个无法靠自身的控制终止的循环被称为死循环。
'''死循环有些时候会极度的影响电脑的性能 甚至会造成硬件的损坏'''
#代码示例:
count = 10
while True:
count *= 10
注:break语句是一种很方便的设计,但是,任何算法都可以使用不包含break语句的其他语句来实现
在程序中是否使用break语句,跟个人编程风格有关。
应避免在一个循环体内使用过多的break语句。因为当循环有多个出口的时候,程序逻辑就显得不够清晰了。
#while嵌套循环
利用while循环制作九九乘法表
#代码示例:
i=1
j=1
while i<10:
while j<=i:
print(j, '*', i, '=', i * j, end='') # end默认不换行
j+=1
j=1
i+=1
print()
'''在循环体内嵌入其他的循环体,如在while循环中可以嵌入for循环, 反之,你可以在for循环中嵌入while循环'''
for循环
for循环可以做到的事情while循环都可以做到!!!
但是for循环语法更加简单 使用频率更高
一般情况下涉及到循环取值的时候 都会考虑使用for循环而不是while循环
'''语法结构
for 变量名 in for循环对象: # 字符串、列表、字典、元组、集合
for循环的循环体代码
每次执行都会将循环对象中的一个元素赋值给变量名'''
#代码示例:
一个简单的for循环
for i in ['you', 'are', 'hello']:
print(i)
'''输出结果是依次取出hello world 各个元素'''
# 循环字符串:依次取出每一个字符
for i in 'hello world':
print(i)
# 循环字典(特殊):循环字典只能获取到字典的key value无法直接获取
userinfo_dict = {'username': "jason", 'age': 18, 'gender': 'male'}
for i in userinfo_dict:
print(i)
'''输出结果:'''
username
age
gender
'循环字典只能获取到字典的key value无法直接获取'
# 循环元组
for i in (11, 22, 33, 44, 55):
print(i)
# 循环集合:字典与集合内部的元素都是无序的
for i in {11, 22, 33, 44, 55, 66}:
print(i)
# for+break
break结束本层for循环
# for+continue
continue结束本次for循环 直接开始下一次
# for+else
for循环正常结束之后运行else子代码
"""与while一致"""
# for循环的嵌套

range关键字
range方法在python2和python3中有所区分
python2中range是直接产生一个列表 元素很多的情况下比较占用空间
python2中有一个xrange 其实就是python3里面的range
python3中range 不占空间但是可以取出很多数据
python3中就只有一个range了
#range()用法
>>> range(1,5) #代表从1到5(不包含5) 顾头不顾尾
[1, 2, 3, 4]
>>> range(1,5,2) #代表从1到5,间隔2(不包含5) 顾头不顾尾
[1, 3]
>>> range(5) #代表从0到5(不包含5) 第三个数字表示的是等差数列的差值 默认情况下是1
[0, 1, 2, 3, 4]
#例
list的操作:
array = [1, 2, 5, 3, 6, 8, 4]
#这里的顺序标识
[1, 2, 5, 3, 6, 8, 4]
(0,1,2,3,4,5,6)
(-7,-6,-5,-4,-3,-2,-1)
>>> array[0:] #列出0以后的
[1, 2, 5, 3, 6, 8, 4]
>>> array[1:] #列出1以后的
[2, 5, 3, 6, 8, 4]
>>> array[:-1] #列出-1之前的
[1, 2, 5, 3, 6, 8]
>>> array[3:-3] #列出3到-3之间的
[3]
'''什么是爬虫???
通过编写代码去网络上爬取我们需要的数据'''
自己找一个具有多页数据的网址 研究url是否有规律
有一些网址分页是用的url
有一个使用的是内部js脚本(暂且忽略)
#代码示例:
url_demo = 'https://www.qidian.com/finish/page%s/'
for i in range(0,10):
real_url = url_demo % i
print(real_url)
通过代码请求页面获取页面数据
然后根据业务需求筛选出特定的内容

数据类型的内置方法
1.整型int
int整型
1.类型转换
2.进制数转换
# 类型转换
# res = '123'
# print(type(res))
# res = int(res)
# print(type(res))
'''int在做类型转换的时候 只能转换纯数字'''
# int('123.123') # 报错 不识别小数点
# int('dasda123') # 报错 不识别除数字以外的数据
'''int其实还可以做进制数转换'''
print(bin(100)) # 将十进制的100转换成二进制 0b1100100
print(oct(100)) # 将十进制的100转换成八进制 0o144
print(hex(100)) # 将十进制的100转换成十六进制 0x64
# 0b开头为二进制数 0o开头为八进制数 0x开头为十六进制数
print(int('0b1100100', 2)) # 100
print(int('0o144', 8)) # 100
print(int('0x64', 16)) # 100
2.浮点型float
float浮点型
1.类型转换
res = float('11.11')
print(res, type(res)) # 11.11
res = float('11')
print(res, type(res)) # 11.0
float('abc') #报错
3.字符串str
1.类型转换
str可以转换所有基本数据类型
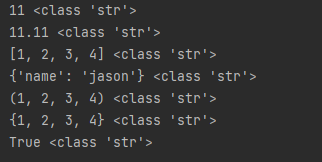
print(str(11), type(str(11)))
print(str(11.11), type(str(11.11)))
print(str([1, 2, 3, 4]), type(str([1, 2, 3, 4])))
print(str({'name': 'jason'}), type(str({'name': 'jason'})))
print(str((1, 2, 3, 4)), type(str((1, 2, 3, 4))))
print(str({1, 2, 3, 4}), type(str({1, 2, 3, 4})))
print(str(True), type(str(True)))
s1 = 'hello world'
# 1.索引取值
print(s1[0])
# 2.切片操作
print(s1[2:4]) # 顾头不顾尾
# 3.步长
print(s1[2:9:1]) # 第三个参数是步长 默认是1 依次获取
print(s1[2:9:2]) # 间隔一个取一个
# 索引取切片扩展
print(s1[-1]) # 获取最后一个字符
print(s1[-1:-5:-1]) # dlro 第三个参数还可以控制索引的方向
print(s1[-5:-1]) # worl
# 4.统计字符串中字符的个数
print(len(s1)) # 11
# 5.成员运算
print('ll' in s1)
# 7.按照指定的字符切割字符串
data = 'jason|123|DBJ'
# print(data.split('|')) # ['jason', '123', 'DBJ']
# name, pwd, hobby = data.split('|') # 解压赋值
print(data.split('|', maxsplit=1)) # ['jason', '123|DBJ']
print(data.rsplit('|', maxsplit=1)) # ['jason|123', 'DBJ']
"""split方法切割完字符串之后是一个列表"""
python strip()方法
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格)或字符序列
#代码示例:
username = ' dlrb '
print(len(username)) #输出字符串长度
res = username.strip() # 默认移除字符串首尾的空格
print(res)
#指定字符
username1 = '^^^^dlrb^^^'
print(username1.strip('^'))
Python split()方法
ython split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串
#代码示例
data = 'andi$dnana$diwm$wemqem'
print(data.split('$'))
#输出结果:
['andi', 'dnana', 'diwm', 'wemqem']
data = 'jason|123|DBJ'
print(data.split('|')) # ['jason', '123', 'DBJ']
name, pwd, hobby = data.split('|') # 解压赋值
print(data.split('|', maxsplit=1)) # ['jason', '123|DBJ']
print(data.rsplit('|', maxsplit=1)) # ['jason|123', 'DBJ']
"""split方法切割完字符串之后是一个列表"""


 浙公网安备 33010602011771号
浙公网安备 33010602011771号