
Week1.2_监督学习_线性回归算法_矩阵运算
感谢博临天下,笔记太好,我就直接搬过来再添加了。http://www.cnblogs.com/fanyabo/p/4060498.html
一、引言
本材料参考Andrew Ng大神的机器学习课程 http://cs229.stanford.edu,以及斯坦福无监督学习UFLDL tutorial http://ufldl.stanford.edu/wiki/index.php/UFLDL_Tutorial
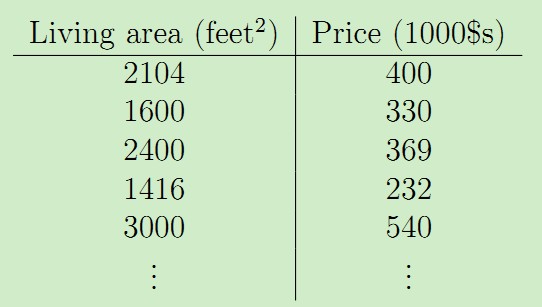
机器学习中的回归问题属于有监督学习的范畴。回归问题的目标是给定D维输入变量x,并且每一个输入矢量x都有对应的值y,要求对于新来的数据预测它对应的连续的目标值t。比如下面这个例子:假设我们有一个包含47个房子的面积和价格的数据集如下:
training set 训练集,所有“确定的答案”,即是data set
m:训练集的数目=47
x:输入变量(特征向量)
y:输出变量(目标变量)
(x,y):一个训练样本;(x(i),y(i)):第i个特征样本; 训练集→函数(hypothesis)
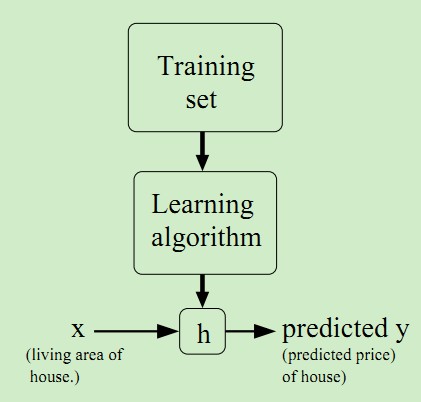
我们可以在Matlab中画出来这组数据集,如下:

我么就可以将拟合的曲线上返回对应的点从而达到预测的目的。如果要预测的值是连续的比如上述的房价,那么就属于回归问题;如果要预测的值是离散的即一个个标签,0/1问题,那么就属于分类问题。这个学习处理过程如下图所示:
二、线性回归模型
线性回归模型假设输入特征和对应的结果满足线性关系。在上述的数据集中加上一维--房间数量,于是数据集变为:
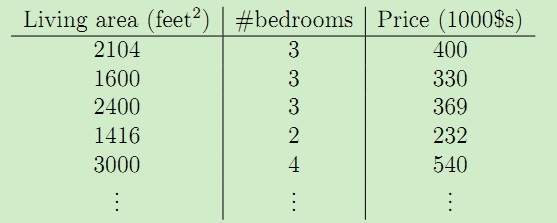
于是,输入特征x是二维的矢量,比如x1(i)表示数据集中第i个房子的面积,x2(i)表示数据集中第i个房子的房间数量。于是可以假设输入特征x与房价y满足线性函数,比如:

在所有问题中,最终要的是找到θi
这里θi称为假设模型即映射输入特征x与结果y的线性函数h的参数parameters,为了简化表示,我们在输入特征中加入x0 = 1,于是得到:
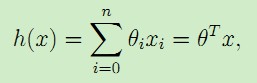
现在,给定一个训练集,我们应该怎么学习参数θ,怎么样能够看出线性函数拟合的好不好呢?一个直观的想法是使得预测值h(x)尽可能接近y,为了达到这个目的,我们对于每一个参数θ,定义一个代价函数cost function用来描述h(x(i))'与对应的y(i)'的接近程度:

又叫做平方误差函数
前面乘上的1/2是为了求导的时候,使常数系数消失。于是我们的目标就变为了调整θ使得代价函数J(θ)取得最小值,方法有梯度下降法,最小二乘法等。

2.1 梯度下降法(→取到极小值)

 ;;
;; 不断变换),直到J=0,说明已经达到局部最优解
不断变换),直到J=0,说明已经达到局部最优解
 常常用contour plot 等值线画出代价函数,中心点事局部最优解初始值就在local minimum的位置,则会如何变化?已经在local minimum位置,所以derivative 肯定是0,因此不会变化;
常常用contour plot 等值线画出代价函数,中心点事局部最优解初始值就在local minimum的位置,则会如何变化?已经在local minimum位置,所以derivative 肯定是0,因此不会变化;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号