
你的博客会写代码了!DeepBlog一键把技术博客变成可执行项目

我曾以为技术博客的终点是传播零碎化的知识和代码片——直到遇到 DeepBlog 它让博客自己写起了代码。
上篇发布的《快速上手:利用音频大模型与Java提取视频文案》不再只是文字和代码片段:
通过 DeepBlog,这篇博客被自动重构为带界面的可执行项目,且成功部署运行;
无需克隆环境、调试依赖,点击按钮即可提取文案;
快速体验:https://deepblog.net/p/f2f7a9d64c2a4b7ea14b53464884e57a
不得不感叹,技术又进化了:
你写的每一行代码,都值得被一键运行。
1、博客生成可运行项目
打开DeepBlog,输入博客链接,剩下的就交给DeepBlog了。
开始生成项目

生成项目中

生成项目完成
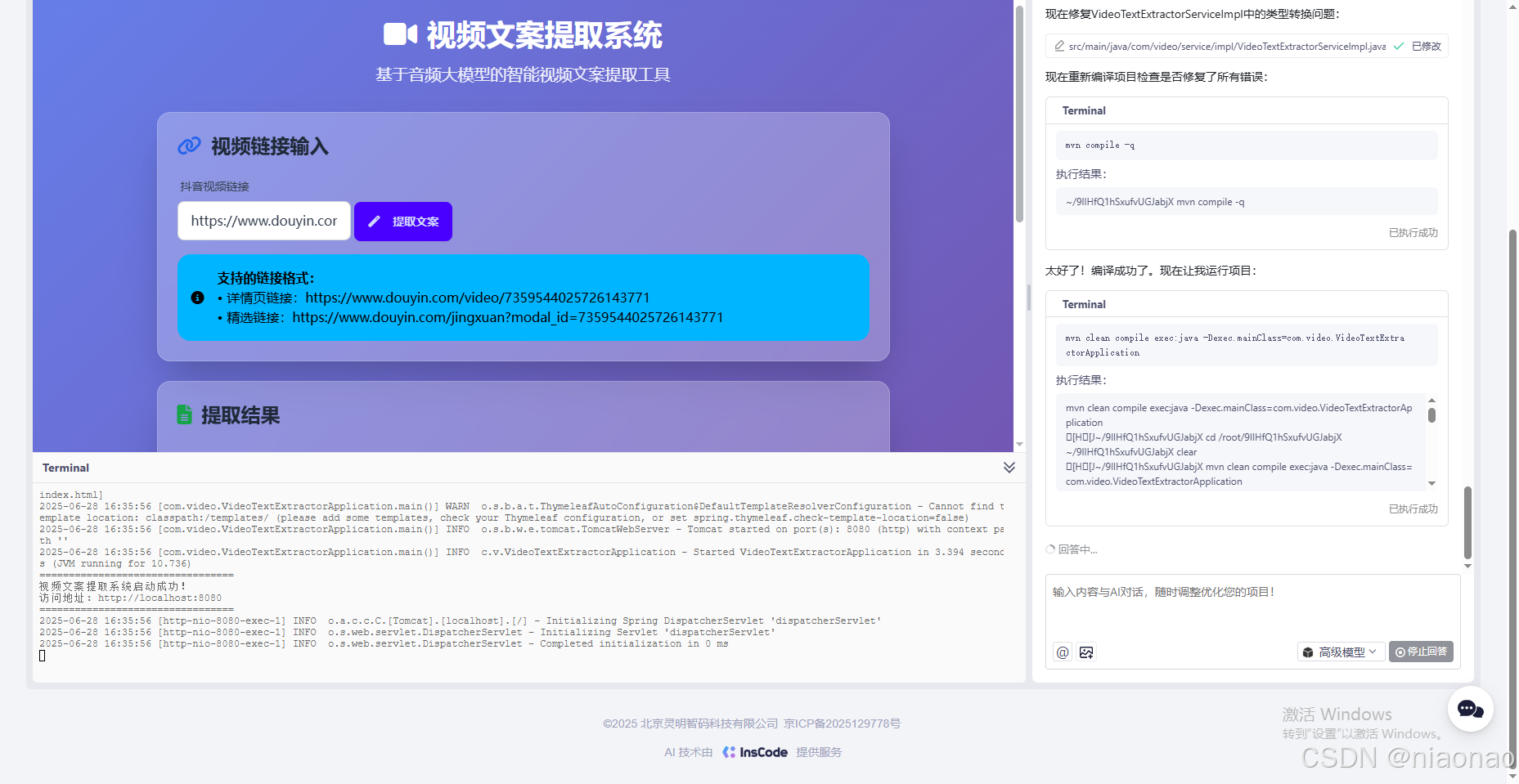
自动部署运行项目
我把项目配置文件中的大模型API-Key换成可用的API-Key
输入抖音视频链接,提取文案成功!!!
真的很奈斯!!!

2、原博客内容《快速上手:利用音频大模型与Java提取视频文案》
📝 基本信息
- 原文链接: CSDN博客文章
- 分类标签: 人工智能, Java开发, 视频处理
- 作者: niaonao
- 技术栈: 通义千问大模型, Java, 抖音开放平台API
🎯 快速了解
本文详细介绍了如何通过音频大模型技术结合Java实现视频文案提取的完整解决方案。核心解决以下问题:
- 主流文本大模型无法直接解析视频链接内容
- 视频理解大模型对平台链接存在访问限制
- 通过音频识别技术实现高质量文案提取的替代方案
🔑 关键价值点:
- 完整解析抖音视频详情接口调用方法
- 提供音频大模型API的Java实现示例
- 对比视频理解与音频识别两种技术路线的优劣
🗺️ 知识图谱
📚 内容解读
需求背景
电商运营需要智能文案工具实现:
- AI创作 ✍️
- 风格改写 🎨
- 文案续写 ➕
- 文案提取 🎬
发现文本大模型无法直接解析视频链接,需要技术解决方案。
技术方案对比
视频理解大模型
限制因素:
- 平台安全策略阻断直接解析
- 内网链接无法访问
- 需要转存本地/OSS
音频识别方案
优势:
- 直接获取原始语音内容
- 支持30秒以上长音频
- 多语言识别能力
关键实现步骤
-
抖音API调用
- 接口:
/aweme/v1/web/aweme/detail - 关键参数:
aweme_id,aid - 请求头需配置
Origin和Referer
- 接口:
-
音频链接提取
// 从响应中提取音频URL String musicUrl = dyDetailVO.getAweme_detail() .getMusic() .getPlay_url() .getUri(); -
大模型API调用
// 构建音频识别请求 ChatInput<List<Map<String, String>>> chatInput = new ChatInput<>(); chatInput.setModel("qwen-audio-turbo-latest"); chatInput.setParameters(new ChatParameters(true));
完整Java实现
包含以下核心组件:
-
HTTP客户端封装
- 使用OkHttp实现
- 自定义重试机制
public Response execute(OkHttpClient client, Request request) { try { return client.newCall(request).execute(); } catch(IOException e) { throw new RuntimeException("调用失败"); } } -
线程池配置
@Bean public ExecutorService chatRequestExecutor() { return new ThreadPoolExecutor(25, 50, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1000)); } -
SSE流式响应处理
while ((line = bufferedReader.readLine()) != null) { if(line.contains("data:")) { String json = line.substring(5); // 解析响应内容 } }
💡 技术亮点
-
混合架构设计:
- 前端: SSE流式输出
- 后端: 线程池+重试机制
- 模型: 阿里云百炼平台
-
安全策略破解:
- 模拟浏览器请求头
- 使用官方iframe接口域名
-
性能优化:
- 异步流式处理
- 连接池管理
🚀 实践建议
- 对于短视频平台,优先采用音频识别方案
- 长视频可考虑视频转存+分片识别
- 重要接口建议添加熔断机制
- 音频识别结果可结合NLP进行后处理
本文提供了从理论到实践的完整指南,特别适合需要实现视频内容分析功能的开发者参考。

DeepBlog 是指利用大模型(如 DeepSeek-R1)快速生成、搭建或辅助运营的博客平台,尤其指在腾讯云 HAI(高性能应用服务)中通过自然语言指令一键生成博客代码并部署的技术方案。
Powered By niaonao

 浙公网安备 33010602011771号
浙公网安备 33010602011771号