
DAY19:信息收集
一、网站信息收集
收集网站信息的目的是为了对网站进行一个全面的了解,找到网站存在的漏洞。利用关键字来确认网站信息。
1. 网站信息收集的大致内容

2. 如何判断网站cms版本

在线工具
wappalyzer插件
whatweb工具(kali whatweb www.discuz.com)
①确定了网站cms版本后如何利用:

3. 判断中间件(不是非常重要)
①中间件的报错信息
②response返回包

4. 判断脚本类型(第二种方法最常用)

5. 网站敏感目录(不用死记,遇到了再查)

6. 网站个人信息

二、服务器信息收集
1. 端口信息(端口信息很重要,tcp协议规定端口号长度为2的16次方,一共65536个(0-65535),所以扫描端口一般指定1-65535)
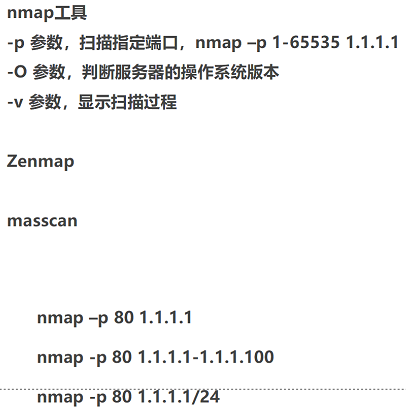
*扫描到的端口状态,若是filtered,有可能是被防火墙拦截,有可能是关闭状态
*每个端口都尽量在浏览器访问一下(避免强行更改端口的情况)
2. 判断服务器操作系统(基本上使用②③就能判断)
①通过操作系统常见端口(开放的端口和端口服务)来判断

②通过大小写敏感来判断

③通过ping来探测

3. 服务器真实IP
①CDN

②如何测试服务器是否有CDN

③如何绕过CDN(了解一下)

(1)查询DNS历史解析记录

(2)查询子域名

(3)网络空间搜索引擎

(4)phpinfo

(5)邮件

(6)扫描全网
(7)ping方法

④如何判断是否找到了真实IP

三、弱口令与暴力破解
1. 实际中对目标的社工

2. 针对web端,利用burpsuit进行暴力破解,有4种爆破模式,爆破结果看长度

3. Hydra工具

常用参数

实例

4. zip压缩包/word文档密码破解

总结
1. 什么是信息收集?
信息收集是指黑客为了更加有效地实施渗透攻击而在攻击前或攻击过程中对目标的所有探测活动。
2. 为什么要信息收集?
了解组织安全架构、缩小攻击范围、描绘网络拓扑、建立脆弱点数据库
做到比管理员更了解它的网站或服务器
3. 如何信息收集?

4. 收集哪些基本信息?
域名信息、网站信息、服务器信息、信息泄露

 浙公网安备 33010602011771号
浙公网安备 33010602011771号