第一个爬虫与测试
一、测试球赛程序函数
GameOver函数



1 def GameOver(scoreA,scoreB): #比赛结束 2 if scoreA >= 11 and scoreA - scoreB >= 2: 3 return scoreA 4 if scoreB >= 11 and scoreB - scoreA >= 2: 5 return scoreB 6 7 try: 8 c=GameOver(7,11) 9 print(c) 10 except: 11 print("error")
结果测试函数正确
二、使用request库的get()函数访问百度网页20次并且打印返回状态,text内容,计算text()属性和content()属性所返回网页内容的长度
在上一个随笔中已经介绍了requests库,这里再简要回顾一下相关函数
| status_code | HTTP请求的返回状态,整数200表示连接成功,404表示失败。在处理数据之前要先判断状态情况,如果请求未被响应,需要终止内容处理。 |
| text | HTTP响应内容的字符串形式,即是url对应的页面内容。 |
| encoding | HTTP响应内容的编码形式,可以通过对encoding 属性赋值更改编码方式,以便于处理中文字符。 |
| content | HTTP响应内容的二进制形式。 |
访问百度页面一次
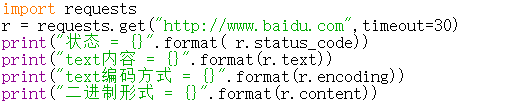
1 import requests 2 r = requests.get("http://www.baidu.com",timeout=30) 3 print("状态 = {}".format( r.status_code)) 4 print("text内容 = {}".format(r.text)) 5 print("text编码方式 = {}".format(r.encoding)) 6 print("二进制形式 = {}".format(r.content))
由于text内容及二进制形式过长,在结果中注释掉,仅展示状态和编码方式
![]() 访问百度页面二十次
访问百度页面二十次
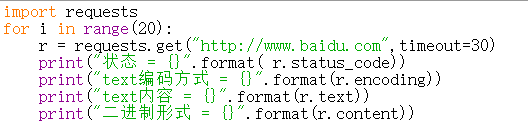
1 import requests 2 for i in range(20): 3 r = requests.get("http://www.baidu.com",timeout=30) 4 print("状态 = {}".format( r.status_code)) 5 print("text编码方式 = {}".format(r.encoding)) 6 print("text内容 = {}".format(r.text)) 7 print("二进制形式 = {}".format(r.content))

三、HTML页面的简单操作
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="utf-8"> 5 <title>菜鸟教程(runboo.com) 26 </title> 6 </head> 7 <body> 8 <h1>我的第一个标题</h1> 9 <p id="first">我的第一个段落。</p> 10 </body> 11 <table border="1"> 12 <tr> 13 <td>row 1,cell 1</td> 14 <td>row 1,cell 2</td> 15 </tr> 16 <tr> 17 <td>row 2,cell 1</td> 18 <td>row 2,cell 2</td> 19 </tr> 20 </table> 21 </html>

1 import requests 2 from bs4 import BeautifulSoup 3 soup = BeautifulSoup("<!DOCTYPE html><html><head><meta charset=‘utf-8‘>\ 4 <title菜鸟教程(rounoob.com)</title></head><body>\ 5 <h1>我的第一标题</h1>\ 6 <p id='first'>我的第一个段落。</p></body>\ 7 <table border=‘1‘><tr><td>row 1,cell 1\ 8 </td><td>row 1,cell 2</td></tr><tr><td>row 2,cell 1\ 9 </td><td>row 2,cell 2</td></tr</table></html>") 10 11 print(soup.head,"12") #打印head标签的内容和我的学号后两位 12 print(soup.body) #打印body的内容 13 print(soup.find_all(id="first")) #打印id为first的文本 14 print(soup.h1.string,soup.p.string) #打印html页面中的中文字符 15 16 17
结果如图:

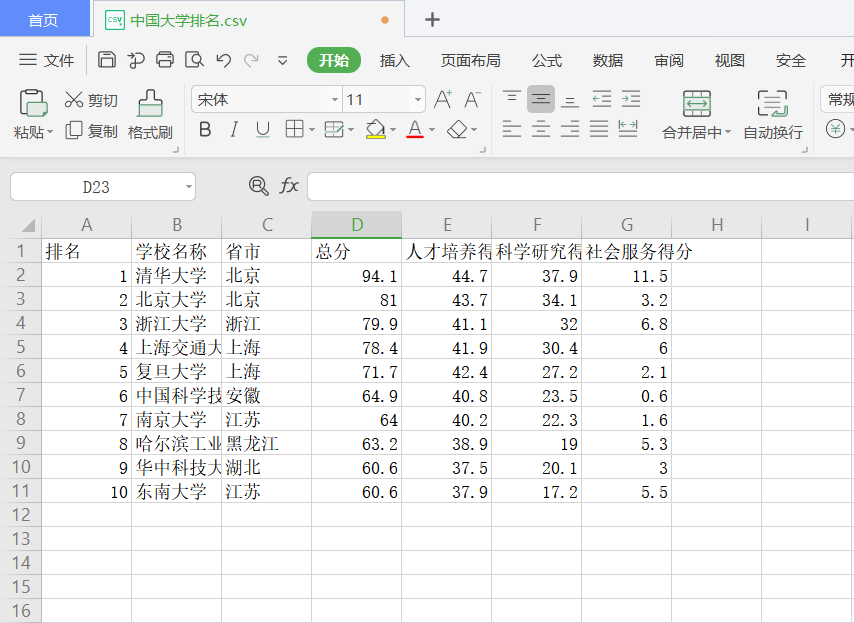
四、爬取大学排名(最后将爬取数据存为csv文件)

1 import requests 2 from bs4 import BeautifulSoup 3 import csv 4 allUniv = [] 5 def getHTMLText(url): 6 try: 7 r = requests.get(url, timeout=10) 8 r.raise_for_status() 9 r.encoding = 'utf-8' 10 return r.text 11 except: 12 return "" 13 14 def filUnivList(soup): 15 data = soup.find_all('tr') 16 for tr in data: 17 ltd = tr.find_all('td') 18 if len(ltd) == 0: 19 continue 20 singleUniv = [] 21 for td in ltd: 22 singleUniv.append(td.string) 23 allUniv.append(singleUniv) 24 25 def main(): 26 url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2015_0.html' 27 html = getHTMLText(url) 28 soup = BeautifulSoup(html, "html.parser") 29 filUnivList(soup) 30 with open("D:\\ZNsmueven\\Python\\中国大学排名.csv", "a", newline="") as cf: 31 w = csv.writer(cf) 32 list=['排名', '学校名称', '省份', '总分', 33 '人才培养得分','科学研究得分','社会服务得分'] 34 w.writerow(list) 35 for i in range(10): #爬取前十名 36 w.writerow(allUniv[i]) 37 cf.close() 38 main()
结果如图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号