实时数据同步方案
一.Flume收集各数据库日志,准实时抽取到HDFS
安装HDP,包含Flume
方案优点:
1.配置简单,不用编程:只要在flume.conf文件中配置source、channel及sink的相关属性
2.采用普通SQL轮询的方式实现,具有通用性,适用于所有关系库数据源
方案缺点:
1.在源库上执行了查询,具有入侵性
2.通过轮询的方式实现增量,只能做到准实时,而且轮询间隔越短,对源库的影响越大
3.只能识别新增数据,检测不到删除与更新
4.要求源库必须有用于表示增量的字段
二.canal
原理:
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送(slave拉取,不是master主动push给slaves)binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
mysql中需要配置一个用户,专门提供给canal用
canal开源代码中发送端仅仅支持mysql,不支持oracle,接收端由于采用jdbc,mysql、oracle等可以通吃。
三.maxwell
优点:
- 支持bootstrap启动,同步历史数据
- 集成kafka,直接将数据落地到kafka
- 已将binlog中的DML和DDL进行了模式匹配,将其解码为有schema的json(有利于后期将其重组为nosql支持的语言)
{“database”:”test”,”table”:”e”,”type”:”update”,”ts”:1488857869,”xid”:8924,”commit”:true,”data”:{“id”:1,”m”:5.556666,”torvalds”:null},”old”:{“m”:5.55}}
缺点:
- 一个MySQL实例需要对应一个maxwell进程
- bootstrap的方案使用的是
select *
maxwell的配置文件只有一个config.properties,在home目录。其中除了需要配置mysql master的地址、kafka地址还需要配置一个用于存放maxwell相关信息的mysql地址,maxwell会把读取binlog关系的信息,如binlog name、position。
工具对比
方案对比
- 方案1使用阿里开源的Canal进行Mysql binlog数据的抽取,另需开发一个数据转换工具将从binlog中解析出的数据转换成自带schema的json数据并写入kafka中。而方案2使用maxwell可直接完成对mysql binlog数据的抽取和转换成自带schema的json数据写入到kafka中。
- 方案1中不支持表中已存在的历史数据进行同步,此功能需要开发(如果使用sqoop进行历史数据同步,不够灵活,会使结果表与原始表结构相同,有区别于数据交换平台所需的schema)。方案2提供同步历史数据的解决方案。
- 方案1支持HA部署,而方案2不支持HA
方案1和方案2的区别只在于kafka之前,当数据缓存到kafka之后,需要一个定制的数据路由组件来将自带schema的数据解析到目标存储中。
数据路由组件主要负责将kafka中的数据实时读出,写入到目标存储中。(如将所有日志数据保存到HDFS中,也可以将数据落地到所有支持jdbc的数据库,落地到HBase,Elasticsearch等。)
maxwell:
MySQL->Maxwell->Kafka->Flume->HDFS
写入HDFS的数据时json的,可能还需要提取只需要的数据,另外,对于update或delete操作目前还不知道要怎么处理。生产使用难度很大。
把增量的Log作为一切系统的基础。后续的数据使用方,通过订阅kafka来消费log。
比如:
- 大数据的使用方可以将数据保存到Hive表或者Parquet文件给Hive或Spark查询;
- 提供搜索服务的使用方可以保存到Elasticsearch或HBase 中;
- 提供缓存服务的使用方可以将日志缓存到Redis或alluxio中;
- 数据同步的使用方可以将数据保存到自己的数据库中;
- 由于kafka的日志是可以重复消费的,并且缓存一段时间,各个使用方可以通过消费kafka的日志来达到既能保持与数据库的一致性,也能保证实时性;
为什么使用log和kafka作为基础,而不使用Sqoop进行抽取呢? 因为:
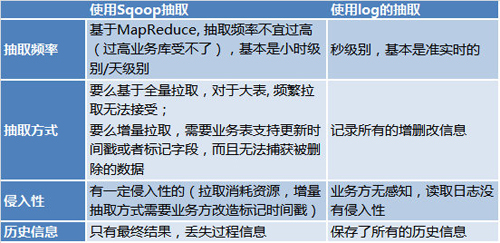
DWS平台, DWS平台是有3个子项目组成:
- Dbus(数据总线):负责实时将数据从源端实时抽出,并转换为约定的自带schema的json格式数据(UMS 数据),放入kafka中;
- Wormhole(数据交换平台):负责从kafka读出数据 将数据写入到目标中;
- Swifts(实时计算平台):负责从kafka中读出数据,实时计算,并将数据写回kafka中。
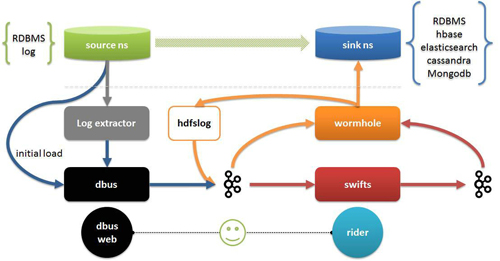
图中:
- Log extractor和dbus共同完成数据抽取和数据转换,抽取包括全量和增量抽取。
- Wormhole可以将所有日志数据保存到HDFS中; 还可以将数据落地到所有支持jdbc的数据库,落地到HBash,Elasticsearch,Cassandra等;
- Swifts支持以配置和SQL的方式实现对进行流式计算,包括支持流式join,look up,filter,window aggregation等功能;
- Dbus web是dbus的配置管理端,rider除了配置管理以外,还包括对Wormhole和Swifts运行时管理,数据质量校验等。
对于增量的log,通过订阅Canal Server的方式,我们得到了MySQL的增量日志:
- 按照Canal的输出,日志是protobuf格式,开发增量Storm程序,将数据实时转换为我们定义的UMS格式(json格式,稍后我会介绍),并保存到kafka中;
- 增量Storm程序还负责捕获schema变化,以控制版本号;
- 增量Storm的配置信息保存在Zookeeper中,以满足高可用需求。
- Kafka既作为输出结果也作为处理过程中的缓冲器和消息解构区。
- 在考虑使用Storm作为解决方案的时候,我们主要是认为Storm有以下优点:
- 技术相对成熟,比较稳定,与kafka搭配也算标准组合;
- 实时性比较高,能够满足实时性需求;
- 满足高可用需求;
- 通过配置Storm并发度,可以活动性能扩展的能力;
全量抽取
对于流水表,有增量部分就够了,但是许多表需要知道最初(已存在)的信息。这时候我们需要initial load(第一次加载)。
对于initial load(第一次加载),同样开发了全量抽取Storm程序通过jdbc连接的方式,从源端数据库的备库进行拉取。initial load是拉全部数据,所以我们推荐在业务低峰期进行。好在只做一次,不需要每天都做。
全量抽取,我们借鉴了Sqoop的思想。将全量抽取Storm分为了2 个部分:
- 数据分片
- 实际抽取
数据分片需要考虑分片列,按照配置和自动选择列将数据按照范围来分片,并将分片信息保存到kafka中。
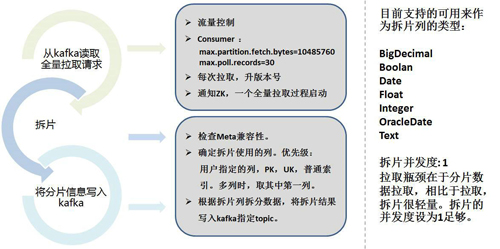
下面是具体的分片策略:
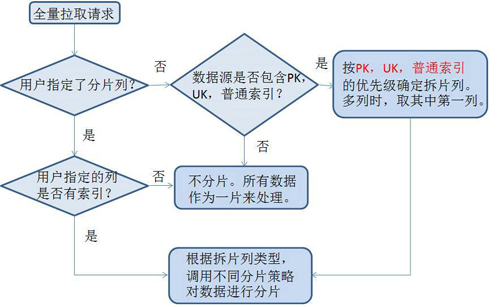
全量抽取的Storm程序是读取kafka的分片信息,采用多个并发度并行连接数据库备库进行拉取。因为抽取的时间可能很长。抽取过程中将实时状态写到Zookeeper中,便于心跳程序监控。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号