【大数据】Hadoop的高可用集群(HA)部署
这里基于之前的博文,即在全分布式安装的基础上增量部署高可用集群。
集群部署表如下:
| NameNode1 | NameNode2 | DataNode | ZooKeeper | ZKFC | JournalNode | |
| node1 | √ | √ | √ | √ | ||
| node2 | √ | √ | √ | √ | √ | |
| node3 | √ | √ | √ | |||
| node4 | √ | √ |
一、备份
1、首先检查之前的全分布式Hadoop集群是否启动成功,确保无误后进行下面操作
2、将node1节点的Hadoop配置文件拷贝一份,命名为hadoop-backup,做一个备份,防止之前工作丢失。

二、部署
1、进入hadoop配置文件目录,修改hadoop-env.sh文件

在其中编辑以下内容:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64/ # java路径
export HDFS_ZKFC_USER=hadoop #ZKFC进程由系统hadoop用户管理
export HDFS_JOURNALNODE_USER=hadoop #JournalNode进程由系统Hadoop用户管理
export HDFS_NAMENODE_USER=hadoop #namenode进程由系统Hadoop用户管理
export HDFS_DATANODE_USER=hadoop #datanode进程由系统Hadoop用户管理
2、覆盖core-site.xml文件
vim core-site.xml
覆盖内容如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/ha</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoopnode2:2181,hadoopnode3:2181,hadoopnode4:2181</value>
</property>
</configuration>
然后保存
3、覆盖hdfs-site.xml文件
vim hdfs-site.xml
覆盖内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoopmaster:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoopnode2:8020</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoopmaster:8485;hadoopnode2:8485;hadoopnode3:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/ha/journalnode</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
4、分发配置到各节点
scp hdfs-site.xml core-site.xml hadoop-env.sh hadoopnode2:`pwd` scp hdfs-site.xml core-site.xml hadoop-env.sh hadoopnode3:`pwd` scp hdfs-site.xml core-site.xml hadoop-env.sh hadoopnode4:`pwd`
5、安装ZooKeeper
在节点2上传到/data目录后,输入以下命令解压
tar xf apache-zookeeper-3.6.2-bin.tar.gz -C /data/zookeeper
配置zookeeper环境变量
vim /etc/profile # 输入 export ZOOKEEPER_HOME=/data/zookeeper/apache-zookeeper-3.6.2-bin/ PATH=........:$ZOOKEEPER_HOME/bin
根据部署表,分发给3和4节点
scp /etc/profile hadoopnode3:/etc scp /etc/profile hadoopnode4:/etc
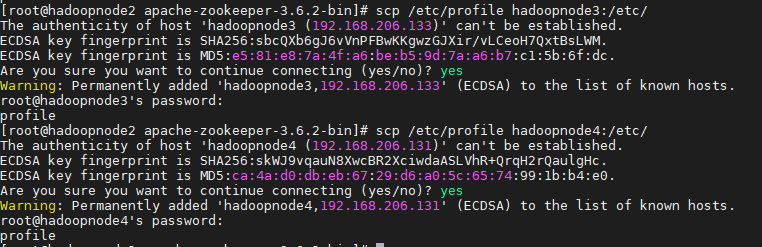
记得source一下
source /etc/profile
6、修改ZooKeeper配置项
进入zookeeper根目录,找到并进入conf目录,修改zoo_sample.cfg文件
mv zoo_sample.cfg zoo.cfg
修改zoo.cfg文件
vim zoo.cfg # 修改如下行 dataDir=/data/zookeeper/zk #末尾添加 server.1=hadoopnode2:2888:3888 server.2=hadoopnode3:2888:3888 server.3=hadoopnode4:2888:3888

保存退出
7、分发ZooKeeper配置项
#在另外两个节点/data下创建文件目录zookeeper scp -r /data/zookeeper/apache-zookeeper-3.6.2-bin hadoopnode3:/data/zookeeper/apache-zookeeper-3.6.2-bin scp -r /data/zookeeper/apache-zookeeper-3.6.2-bin hadoopnode4:/data/zookeeper/apache-zookeeper-3.6.2-bin
8、创建ZooKeeper必要的文件目录
cat /data/zookeeper/apache-zookeeper-3.6.2-bin/conf/zoo.cfg #看自己设置的dataDir的位置,然后进行创建 mkdir /data/zookeeper/zk
9、根据配置文件添加ZooKeeper必要的服务器编号
cat /data/zookeeper/apache-zookeeper-3.6.2-bin/conf/zoo.cfg #观察刚才配置的服务器编号 #在节点2上 echo 1 > /data/zookeeper/zk/myid #在节点3上 echo 2 > /data/zookeeper/zk/myid #在节点4上 echo 3 > /data/zookeeper/zk/myid
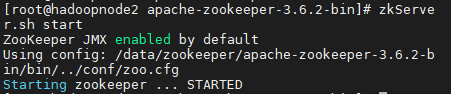
10、运行zookeeper
zkServer.sh start
zkServer.sh status #查看各个zk节点的状态

更多命令,请直接去官网查看
11、格式化集群
根据部署表,首先分别在各个服务器上启动journalnode进程
hdfs --daemon start journalnode
任意选择1个namenode节点进行格式化
hdfs namenode -format
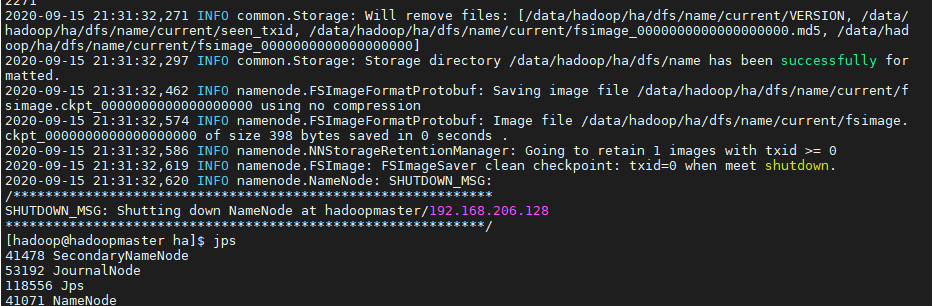
启动节点1的namenode
hadoop-daemon.sh start namenode
在其他需要启动namenode的服务器上执行命令进行同步
hdfs namenode -bootstrapStandby
12、ZooKeeper格式化
hdfs zkfc -formatZK

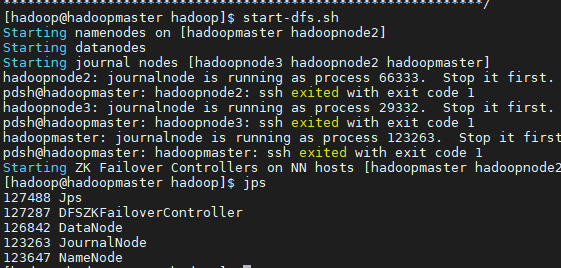
三、启动
start-dfs.sh
四、访问可视化
浏览器输入http://192.168.206.128:9870/
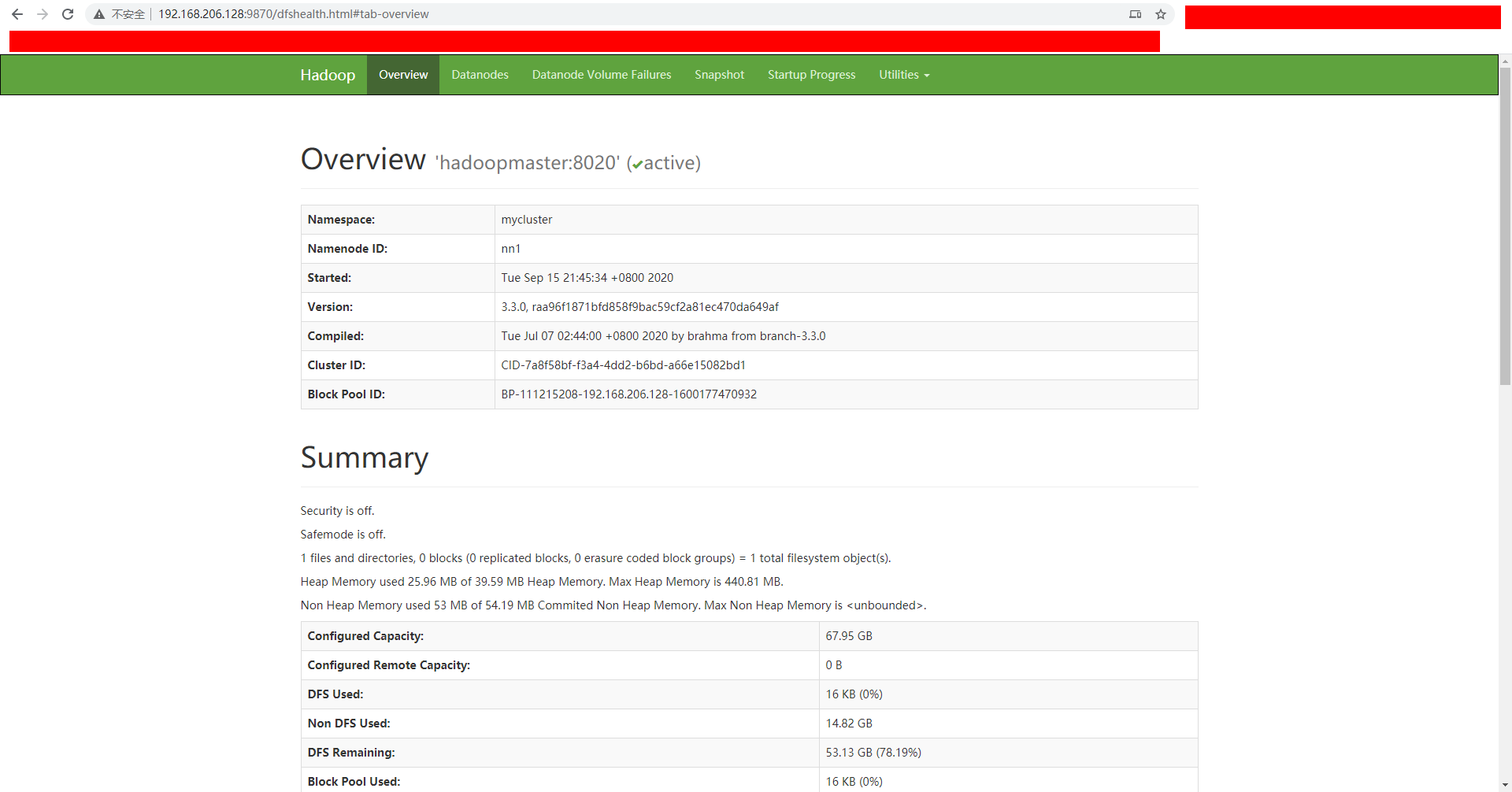
成功,且主节点的namenode节点可以看到是active状态
访问节点二的8970端口,即192.168.206.132:9870
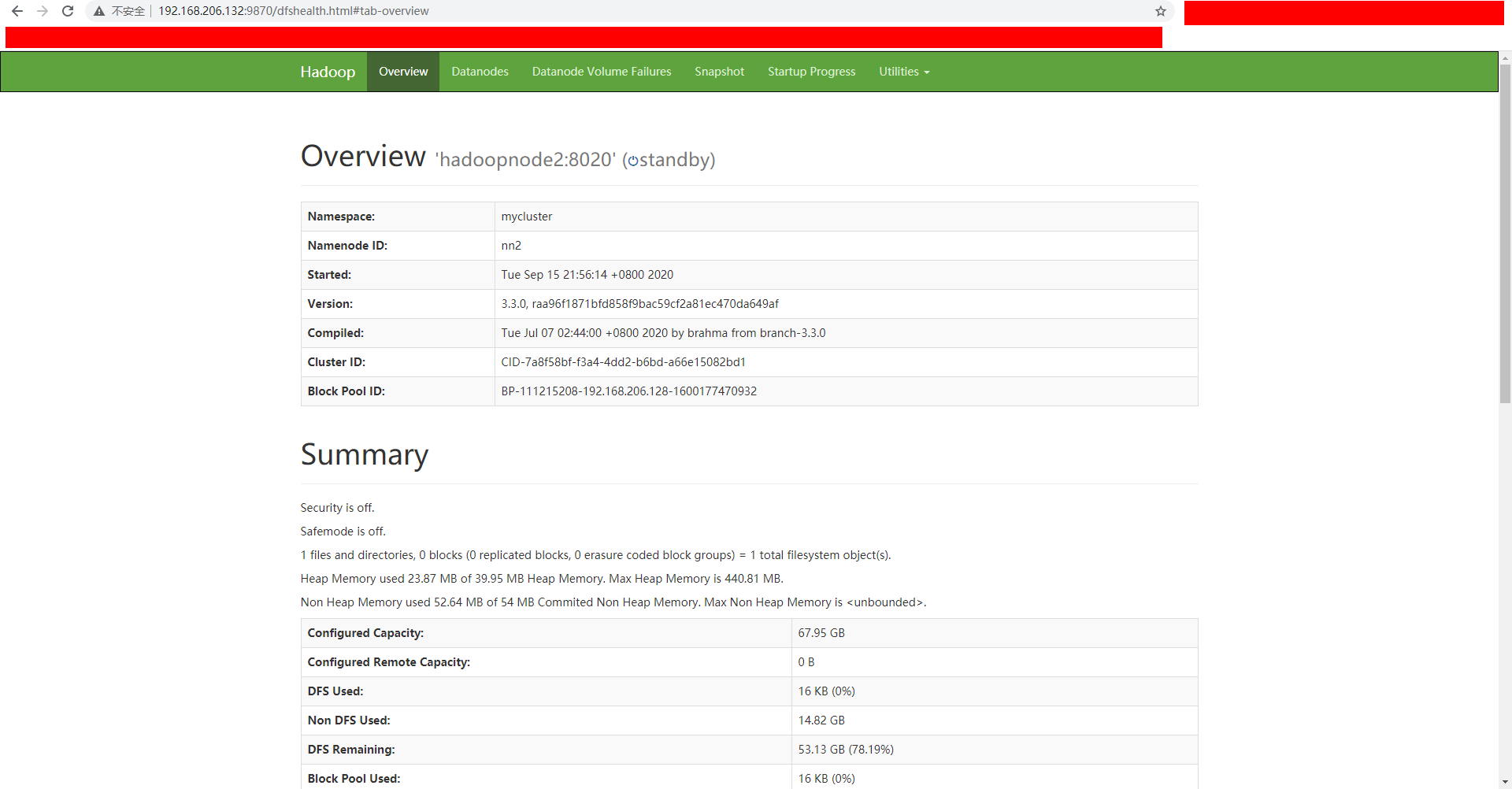
可以看到该节点的namenode是standby状态
到这里,一个高可用的Hadoop集群就部署完毕!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号