20190407 Word合并单元格
很长一段时间没处理word合并单元格,又忘记了采取忽略错误的方式测试出相应单元格的行列坐标这种方式。真是浪费时间。以后再也不想为此在深夜熬命。
今晚算是和它杠上了,很想弄清楚合并单元格之后行列坐标重新分配的机制。于是做了一点测试。插入一个11行10列的表格,然后合并其中的部分,利用代码插入新的坐标。
转载请说明出处。
Sub NewPos()
Dim tb As Table, cel As Cell
Dim doc As Document
Set doc = ThisDocument
Set tb = doc.Tables(1)
For i = 1 To 10
For j = 1 To 10
On Error Resume Next
Set cel = tb.Cell(i, j)
On Error GoTo 0
If Not cel Is Nothing Then
Debug.Print Len(cel.Range.Text); " "; i; " "; j
If Len(cel.Range.Text) > 2 Then
cel.Range.Text = Replace(cel.Range.Text, vbCr, "") & ";" & "(" & i & "," & j & ")"
Else
cel.Range.Text = "(" & i & "," & j & ")"
End If
End If
Set cel = Nothing
Next j
Next i
Set doc = Nothing
Set cel = Nothing
Set tb = Nothing
End Sub
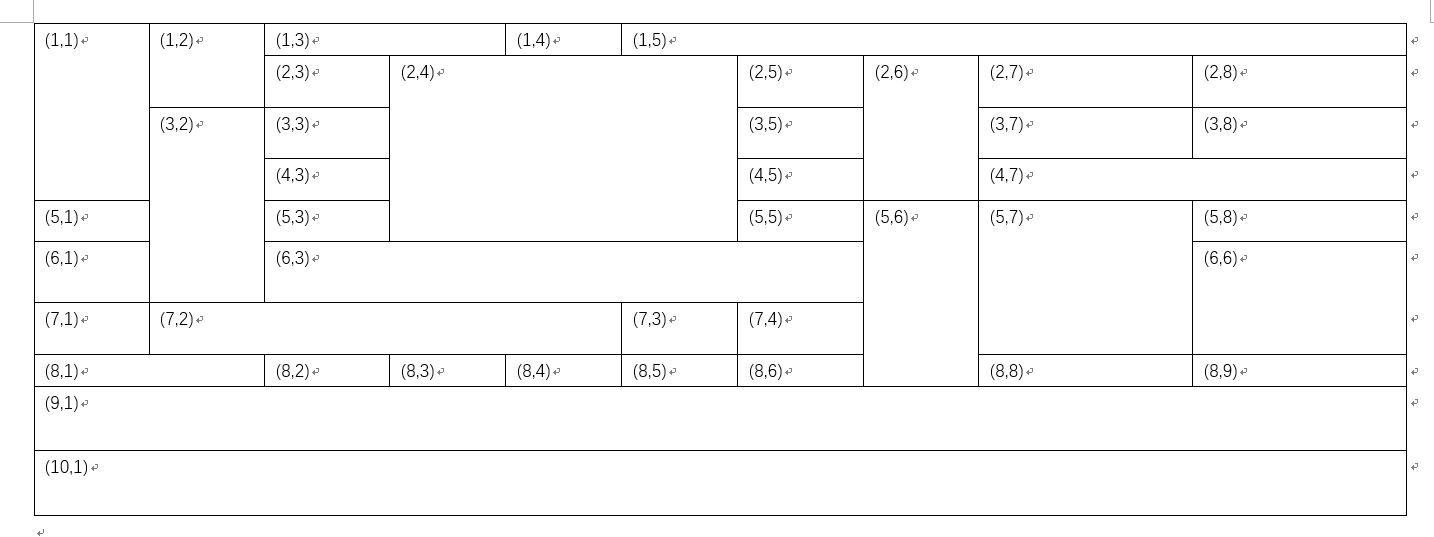
新坐标分配总结如下:
0、先行后列
1、行坐标的分配:从上向下逐一递增,如果遇到连续几个整行水平合并,则视为一行。如(9,1)实为原始的第9和第10行合并。
2、列坐标的分配:从左向右逐一递增分配,如果遇到垂直合并单元格则需要分为两种情况:
第一种情况,该行正好是垂直合并单元格所在的首行,则列号依然遵循从左至右逐一递增分配,如(2,3)到(2,4),(5,5)到(5,6)
第二种情况较为复杂,如果该行并非垂直合并单元格所在的首行,则列号会出现缺失。
(1)在一行中间出现这种情况:(3,3)到(3,5)缺失了(3,4);
(2)在一行的行末遇到这种情况:(7,4)成为第7行最后一个列坐标;
(3)如在一行的行首遇到这种情况:第二行缺失了(2,1)(2,2)第三行缺失了(3,1)
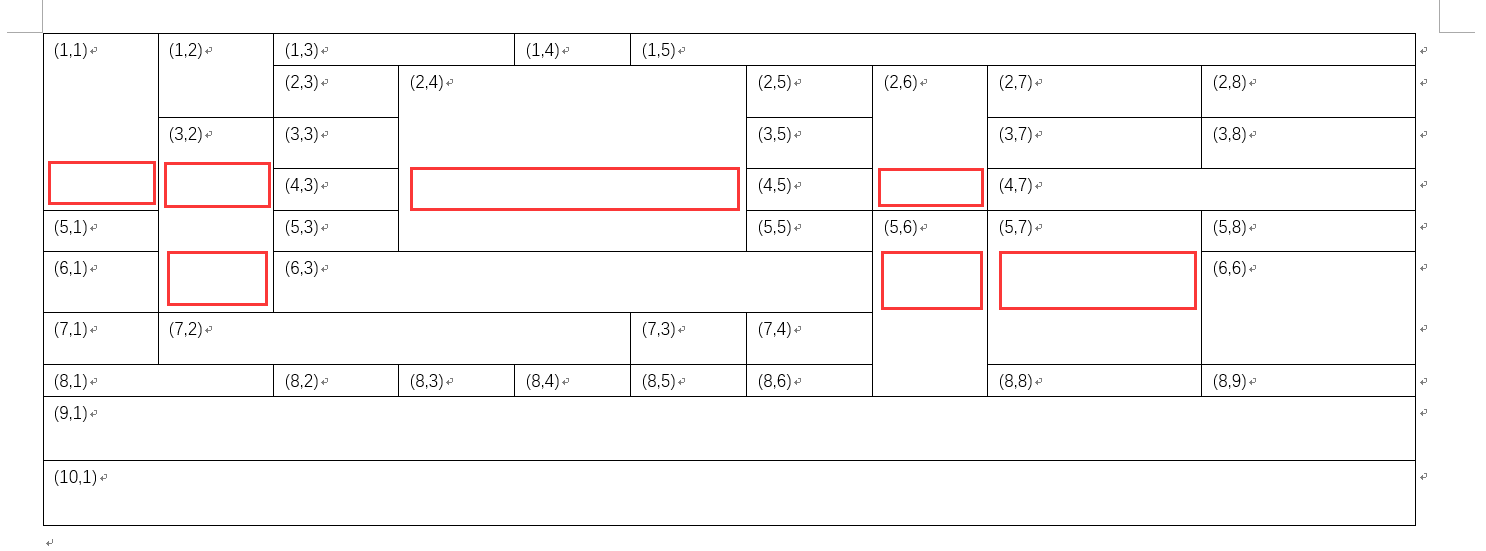
通过正则表达式则提取到以下结果
Public Sub RegGet()
Dim Regex As Object
Dim Mh As Object
Set Regex = CreateObject("VBScript.RegExp")
With Regex
.Global = True
.MultiLine = True
.Pattern = "(\(\d+\,\d\))\s\x07"
End With
txt = ThisDocument.Content.Text
Set Mh = Regex.Execute(txt)
n = 0
For Each m In Mh
n = n + 1
Debug.Print n; " > "; m.submatches(0)
Next
Set Regex = Nothing
End Sub
1 > (1,1)
2 > (1,2)
3 > (1,3)
4 > (1,4)
5 > (1,5)
6 > (2,3)
7 > (2,4)
8 > (2,5)
9 > (2,6)
10 > (2,7)
11 > (2,8)
12 > (3,2)
13 > (3,3)
14 > (3,5)
15 > (3,7)
16 > (3,8)
17 > (4,3)
18 > (4,5)
19 > (4,7)
20 > (5,1)
21 > (5,3)
22 > (5,5)
23 > (5,6)
24 > (5,7)
25 > (5,8)
26 > (6,1)
27 > (6,3)
28 > (6,6)
29 > (7,1)
30 > (7,2)
31 > (7,3)
32 > (7,4)
33 > (8,1)
34 > (8,2)
35 > (8,3)
36 > (8,4)
37 > (8,5)
38 > (8,6)
39 > (8,8)
40 > (8,9)
41 > (9,1)
42 > (10,1)
因此也可以采用正则的办法提取单元格的内容
Public Sub RegGet()
Dim Regex As Object
Dim Mh As Object
Set Regex = CreateObject("VBScript.RegExp")
With Regex
.Global = True
.MultiLine = False '设为单行模式,^元义符代表全文的开始,{n}通过重复括号内的子表达式n次的方式提取第n个单元格的内容
.Pattern = "^(.*?\s\x07){2}"
End With
txt = ThisDocument.Content.Text
Set Mh = Regex.Execute(txt)
n = 0
For Each m In Mh
n = n + 1
Debug.Print n; " >>>>>>>>>>> "; m.Value
Debug.Print "提取内容:"; m.submatches(0)
Next
Set Regex = Nothing
End Sub
所有的问题产生的根源都是对WORD 对象模型不熟悉
原来可以如此循环所有单元格
Sub RangeCells()
For Each cel In ThisDocument.Tables(1).Range.Cells
Debug.Print cel.Range.Text
Next cel
End Sub

 浙公网安备 33010602011771号
浙公网安备 33010602011771号