


C++ traits技法的一点理解
为了更好的理解traits技法。我们一步一步的深入。先从实际写代码的过程中我们遇到诸如下面伪码说起。
1 template< typename T,typename B> 2 void (T a,B c){ 3 if(变量a 属于类型b){ 4 //执行相应的代码 5 a+=c; 6 } else if(变量a 属于类型c){ 7 //执行相应的代码 8 a-=c; 9 } 10 }
虽然这样的代码可以执行。但是有一点不好的地方:
(1)变量a的类型是在运行期间才会知道的。这样就会导致if和else if对应的执行代码都会编译到可执行文件中,导致编译后代码量增大。
为了更好的理解上述缺点。我们首先引入一段代码(必须看明白了 否则后面的不好理解了)。来说明上述代码是在运行时刻才会知道变量的类型的。
1 #include<iostream> 2 using namespace std; 3 4 //声明两种类类型 5 struct Typeone{ 6 //判断是否是该类类型 7 static const int typeFlag = 1; 8 }; 9 struct Typetwo{ 10 //判断是否是该类类型 11 static const int typeFlag = 2; 12 }; 13 /****************文字解释的地方*****************/ 14 template< typename T > 15 void _func(T a ){ 16 if( 1 == a.typeFlag ){ //@ 在运行期间才会确定a是哪个类型。 17 cout<<"接下来是任务1要做的事!"<<endl; 18 //具体要执行的代码 19 } 20 else if(2 == a.typeFlag ){ //@ 在运行期间才会确定a是哪个类型。 21 cout<<"接下来是任务2要做的事情!"<<endl; 22 //具体要执行的代码 23 } 24 25 } 26 /*************************************************/ 27 28 //主函数 29 int main(int argc ,char ** argv) 30 { 31 Typeone b; 32 Typetwo d; 33 _func( b ); 34 _func( d ); 35 36 return 0; 37 }
上述代码运行结果:
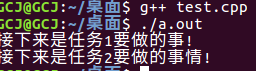
正如代码中标记@ 这个符号的地方所写。变量a是在运行期间通过if的判断才会确定a是哪个类型。虽然我们知道模板函数会对变量a的类型进行推导。也就是说在编译时刻就会把a推导为相应的类型。但是a.typeFlag与1的比较是在运行期,取出a.typeFlag变量的内容然后与1进行比较,当满足这个if条件后才会执行相应的代码。不知道你有没有发现一个问题。在编译程序的时候。if 和else if 对应的执行代码都会被编译到可执行文件中。这也就使得编译后的代码量增大。
上述代码和文字解释了最初那段伪码的缺点。为了解决上述问题我们有四个方案可供选择。
(1)直接函数重载
(2)声明内嵌类型或者叫做迭代器+函数重载
(3)Typeone和Typetwo类型以及内置类型转化为内嵌类型(普通迭代器)+函数重载
(4)traits技法 + 函数重载
先做一些准备工作,插入下面要说的名词代表的意思:
控制函数:
1 //控制函数(利用模板函数的参数推导功能) 2 template< typename T > 3 void _func(T a ){ //@@改变处 4 T b; 5 func(a,b); 6 }
Typeone类型对应的执行函数:
1 /*Typeone类型执行函数*/ 2 template<typename T> 3 void func( T&t,Typeone ){ 4 cout<<"接下来是Typeone要做的事!"<<endl;; 5 //具体要执行的代码 6 }
Typetwo类型对应的执行函数:
1 /*Typetwo类型执行函数*/ 2 template<typename T> 3 void func( T&t,Typetwo ){ 4 cout<<"接下来是Typetwo要做的事情!"<<endl; 5 //具体要执行的代码 6 }
int类型对应的执行函数:
1 /*int 类型执行函数*/ 2 template<typename T> 3 void func(T&t,int){ 4 cout<<"接下来是int要做的事情!"<<endl; 5 //具体要执行的代码 6 }
好了接下来进入正题。首先举一个例子来说明第一种方法:将上面代码修改为三个重载的模板函数,外加一个控制这些函数的模板函数即控制函数。如下代码以及运行结果图:
方法(1):直接函数重载:
1 #include<iostream> 2 using namespace std; 3 /*************************第二段代码***********************/ 4 //声明两种类类型 5 struct Typeone{ 6 //判断是否是该类类型 7 static const int typeFlag = 1; 8 }; 9 struct Typetwo{ 10 //判断是否是该类类型 11 static const int typeFlag = 2; 12 }; 13 /*******************相比第一段代码更改处**********************/ 14 //不同的重载函数 15 /*Typeone类型执行函数*/ 16 template<typename T> 17 void func( T&t,Typeone ){ 18 cout<<"接下来是Typeone要做的事!"<<endl;; 19 //具体要执行的代码 20 } 21 22 /*Typetwo类型执行函数*/ 23 template<typename T> 24 void func( T&t,Typetwo ){ 25 cout<<"接下来是Typetwo要做的事情!"<<endl; 26 //具体要执行的代码 27 } 28 29 /*int 类型执行函数*/ 30 template<typename T> 31 void func(T&t,int){ 32 cout<<"接下来是int要做的事情!"<<endl; 33 //具体要执行的代码 34 } 35 36 //控制函数(利用模板函数的参数推导功能) 37 template< typename T > 38 void _func(T a ){ //@@改变处 39 T b; 40 func(a,b); 41 } 42 /*************************************************/ 43 44 //主函数 45 int main(int argc ,char ** argv) 46 { 47 Typeone b; 48 Typetwo d; 49 int c; 50 51 _func( b ); 52 _func( d ); 53 _func(c); 54 55 return 0; 56 }
上述代码运行结果图:
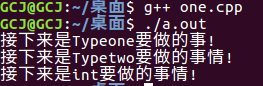
从代码上可以看出,在main主函数中,当我们分别输入Typeone、Typetwo、 int类型的变量时,都会通过控制重载函数去执行相应的函数,这样一来我们在编译的时刻就会减少了很多的代码(利用重载函数),并且在编译时刻就会知道控制函数中变量a b的类型(利用模板函数的参数类型推导功能)。到了这里就结束了吗?当然不是,如果到了这里就结束的话题目就没有必要说traits技法了。慢慢来。我们在更进一步的说明。从上面的代码可以看出,它对于内置类型和类类型还是有很强的适应性。试想一下。如果我们的需求变了,当我们要求控制函数_func()输入一个迭代器类型的变量,然后它对应的执行函数是迭代器内部类型对应的执行函数。比如myiterator<int> a ,我们要求_func(a)执行int类型对应的func()函数。目前的代码是不能够适应这个需求的。比如下面折叠的代码中就会出现编译错误,注意看主函数中增加的部分以及相比第二段代码更改处(代码中已标记),(因为e是一个迭代器,所以控制函数中T推导为myiterator<int>类型。然后调用函数func(a,b)时候,因为没有这种重载函数会编译出错,而且它本身也不符合我们要求的那样去调用int对应的执行函数)。错误代码如下:
1 #include<iostream> 2 using namespace std; 3 /*************************第三段代码***********************/ 4 //声明两种类类型 5 struct Typeone{ 6 //判断是否是该类类型 7 static const int typeFlag = 1; 8 }; 9 struct Typetwo{ 10 //判断是否是该类类型 11 static const int typeFlag = 2; 12 }; 13 /*******************相比第二段代码更改处**********************/ 14 template<typename T> 15 struct myiterator{ 16 typedef T type; 17 }; 18 /*************************************************/ 19 20 //不同的重载函数 21 /*Typeone类型执行函数*/ 22 template<typename T> 23 void func( T&t,Typeone ){ 24 cout<<"接下来是Typeone要做的事!"<<endl;; 25 //具体要执行的代码 26 } 27 28 /*Typetwo类型执行函数*/ 29 template<typename T> 30 void func( T&t,Typetwo ){ 31 cout<<"接下来是Typetwo要做的事情!"<<endl; 32 //具体要执行的代码 33 } 34 35 /*int 类型执行函数*/ 36 template<typename T> 37 void func(T&t,int){ 38 cout<<"接下来是int要做的事情!"<<endl; 39 //具体要执行的代码 40 } 41 42 //控制函数(利用模板函数的参数推导功能) 43 template< typename T > 44 void _func(T a ){ //@@改变处 45 T b; 46 func(a,b); 47 } 48 49 //主函数 50 int main(int argc ,char ** argv) 51 { 52 Typeone b; 53 Typetwo d; 54 int c; 55 myiterator<int> e; //增加的部分 56 57 _func( b ); 58 _func( d ); 59 _func(c); 60 _func(e); //增加的部分 61 62 return 0; 63 }
针对上面的错误代码,那么有没有其他方法能够解决呢?我们传统的思想是在控制函数内部在加一层判断是不是迭代器类型,之后在调用迭代器内部类型对应的执行函数。那么这样不仅是回到了原来伪码出现的问题(编译后的代码量会增加)。而且还修改了控制函数本身的结构。这破坏了控制函数代码的封装性(因为每加入一种类型就要变动函数内部的写法,这本身不符合函数封装性,而且影响了函数内部算法本身的适应性)。那么我们该如何更改呢?看了上述错误代码后你可能会想,我可以把控制函数内的T b 变为typename T::type_category b 这样就能很好的解决了上述的额外要求了!比如下面的折叠代码(主要看控制函数部分):


1 #include<iostream> 2 using namespace std; 3 /*************************第三段代码***********************/ 4 //声明两种类类型 5 struct Typeone{ 6 //判断是否是该类类型 7 static const int typeFlag = 1; 8 }; 9 struct Typetwo{ 10 //判断是否是该类类型 11 static const int typeFlag = 2; 12 }; 13 /*******************相比第二段代码更改处**********************/ 14 //迭代器或者内嵌类型 15 template<typename T> 16 struct myiterator{ 17 typedef T type_category; 18 }; 19 /*************************************************/ 20 21 //不同的重载函数 22 /*Typeone类型执行函数*/ 23 template<typename T> 24 void func( T&t,Typeone ){ 25 cout<<"接下来是Typeone要做的事!"<<endl;; 26 //具体要执行的代码 27 } 28 29 /*Typetwo类型执行函数*/ 30 template<typename T> 31 void func( T&t,Typetwo ){ 32 cout<<"接下来是Typetwo要做的事情!"<<endl; 33 //具体要执行的代码 34 } 35 36 /*int 类型执行函数*/ 37 template<typename T> 38 void func(T&t,int){ 39 cout<<"接下来是int要做的事情!"<<endl; 40 //具体要执行的代码 41 } 42 43 //控制函数(利用模板函数的参数推导功能) 44 template< typename T > 45 void _func(T a ){ //@@改变处 46 typename T::type_category b; 47 // T b; 48 func(a,b); 49 } 50 51 //主函数 52 int main(int argc ,char ** argv) 53 { 54 Typeone b; 55 Typetwo d; 56 int c; 57 myiterator<int> e; 58 59 /*相比第三段代码更改处*/ 60 _func( b ); //注释掉 61 _func( d ); 62 _func(c); 63 _func(e); 64 65 return 0; 66 }
但是这样真的能行吗?上面的代码也是会编译错误的。因为在主函数中Typeone Typetwo int 这三个类型的变量当调用控制函数_func()的时候。他们没有T::type_category这种形式。所以会编译错误。当我们注释掉主函数中_func(b)、_func(d)、_func(c)的时候,可以看出结果确实按照我们的要求执行int类型的执行函数了。注释后的代码以及运行结果如下:
这也是方法(2)声明内嵌类型或者叫做迭代器+函数重载
1 #include<iostream> 2 using namespace std; 3 /*************************第三段代码***********************/ 4 //声明两种类类型 5 struct Typeone{ 6 //判断是否是该类类型 7 static const int typeFlag = 1; 8 }; 9 struct Typetwo{ 10 //判断是否是该类类型 11 static const int typeFlag = 2; 12 }; 13 /*******************相比第二段代码更改处**********************/ 14 //迭代器或者内嵌类型 15 template<typename T> 16 struct myiterator{ 17 typedef T type_category; 18 }; 19 /*************************************************/ 20 21 //不同的重载函数 22 /*Typeone类型执行函数*/ 23 template<typename T> 24 void func( T&t,Typeone ){ 25 cout<<"接下来是Typeone要做的事!"<<endl;; 26 //具体要执行的代码 27 } 28 29 /*Typetwo类型执行函数*/ 30 template<typename T> 31 void func( T&t,Typetwo ){ 32 cout<<"接下来是Typetwo要做的事情!"<<endl; 33 //具体要执行的代码 34 } 35 36 /*int 类型执行函数*/ 37 template<typename T> 38 void func(T&t,int){ 39 cout<<"接下来是int要做的事情!"<<endl; 40 //具体要执行的代码 41 } 42 43 //控制函数(利用模板函数的参数推导功能) 44 template< typename T > 45 void _func(T a ){ //@@改变处 46 typename T::type_category b; 47 // T b; 48 func(a,b); 49 } 50 51 //主函数 52 int main(int argc ,char ** argv) 53 { 54 Typeone b; 55 Typetwo d; 56 int c; 57 myiterator<int> e; 58 59 /*相比第三段代码更改处*/ 60 //_func( b ); //注释掉 61 //_func( d ); 62 //_func(c); 63 _func(e); 64 65 return 0; 66 }
上述代码运行结果图:
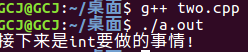
到了这里你也会发现方法(2)本身仅仅满足了迭代器类型的要求,对于传统内置类型却无能为力。而方法(1)解决了传统的内置类型,但是对迭代器类型也是无能为力。那么还有没有什么方法可以结合两种方法呢?方法(3)很好的解决了这个问题。
方法(3):Typeone和Typetwo类型以及内置类型转化为内嵌类型(普通迭代器)+函数重载
我们把所有基本类型以及自定义的类类型都用内嵌类型来表达,统一接口,都用myiterator<Typeone> b 这种方式来定义变量,然后在控制函数内部,定义变量b的时候修改为:typename T::type_category。这样是可以解决上面的问题的,如下代码以及运行结果图:
1 #include<iostream> 2 using namespace std; 3 /*************************第三段代码***********************/ 4 //声明两种类类型 5 struct Typeone{}; 6 struct Typetwo{}; 7 /*******************相比第二段代码更改处**********************/ 8 template<typename T> 9 struct myiterator{ 10 typedef T type_category; 11 }; 12 /*************************************************/ 13 14 //不同的重载函数 15 /*Typeone类型执行函数*/ 16 template<typename T> 17 void func( T&t,Typeone ){ 18 cout<<"接下来是Typeone要做的事!"<<endl;; 19 //具体要执行的代码 20 } 21 22 /*Typetwo类型执行函数*/ 23 template<typename T> 24 void func( T&t,Typetwo ){ 25 cout<<"接下来是Typetwo要做的事情!"<<endl; 26 //具体要执行的代码 27 } 28 29 /*int 类型执行函数*/ 30 template<typename T> 31 void func(T&t,int){ 32 cout<<"接下来是int要做的事情!"<<endl; 33 //具体要执行的代码 34 } 35 36 //控制函数(利用模板函数的参数推导功能) 37 template< typename T > 38 void _func(T a ){ //@@改变处 39 typename T::type_category b; 40 // T b; 41 func(a,b); 42 } 43 44 //主函数 45 int main(int argc ,char ** argv) 46 { 47 //Typeone b; 48 //Typetwo d; 49 //int c; 50 /*相比第三段更改处,上面的类型用内嵌类型来表达*/ 51 myiterator<Typeone>b; 52 myiterator<Typetwo>d; 53 myiterator<int >c; 54 myiterator<int> e; 55 56 _func( b ); 57 _func( d ); 58 _func(c); 59 _func(e); 60 61 return 0; 62 }
上述代码运行结果图:
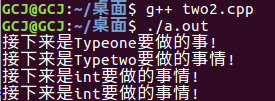
看了上面的代码,你有没有发现其实这样有一点不好,那就是我们在写代码的时候,对于这种方式:myiterator<Typeone>b,Typeone是想要的类型。调用函数_func()之前我们还要有意识的用上面的那种方式定义一个变量。即:
myiterator<Typeone>b; _func(b)
那就是说这种函数本身的封装性能做的不好,不符合我们平时调用函数的习惯。重要的是我们之前没有考虑指针类型。那么对于指针类型,也就是说当我们要求对于输入int *这种指针类型变量时,对应要执行指针指向类型的执行函数,即:
int * b; _func(b);
之后_func()函数会自动的调用int类型的执行函数。那么方法(3)也是无法做到的。只能通过在控制函数中添加一层判断语句才可以(这样又会导致了编译后代码量增大)。那么有没有两全其美的方法呢?那就是本文所说的traits技法。
方法(4):traits技法 + 函数重载
通过对指针类型做一个特化的版本(这是内嵌类型所不能做到的),如下面的代码和结果图(代码测试中加入了上面那部分代码所做的事情如:myiterator<Typeone> g;_func(g);这种不推荐的做法。目的是为了跟这种方式作比较Typeone b;_func(b);两种方法都能够执行相同的函数。但是traits技法更具封装性。符合我们调用代码的习惯。而且更重要的是下面的代码比上面的代码适应了指针类型。下面会有说明。):
1 #include<iostream> 2 using namespace std; 3 /*************************第三段代码*************************/ 4 //声明两种类类型 5 struct Typeone{}; 6 struct Typetwo{}; 7 8 /*******************相比第二段代码更改处**********************/ 9 //迭代器类型也叫做内嵌类型 10 template<typename T> 11 struct myiterator{ 12 typedef T type_category; 13 }; 14 /************************************************************/ 15 16 /*******************相比第三段代码更改处**********************/ 17 18 /***********特性萃取器-----------迭代器类型************/ 19 template<typename unknown_type> 20 struct mytraits{ 21 typedef typename unknown_type::type_category type_category; 22 }; 23 /***********特性萃取器偏特化-----指针类型****************/ 24 template<typename unknown_type> 25 struct mytraits<unknown_type *>{ 26 typedef unknown_type type_category; 27 }; 28 /***********特性萃取器偏特化-----常量指针类型************/ 29 template<typename unknown_type> 30 struct mytraits<const unknown_type *>{ 31 typedef const unknown_type type_category; 32 }; 33 /***********特性萃取器特化-------int类型*****************/ 34 template<> 35 struct mytraits<int >{ 36 typedef int type_category; 37 }; 38 /************特性萃取器-----Typeone类型********************/ 39 template<> 40 struct mytraits<Typeone>{ 41 typedef Typeone type_category; 42 }; 43 /************特性萃取器-----Typetwo类型********************/ 44 template<> 45 struct mytraits<Typetwo>{ 46 typedef Typetwo type_category; 47 }; 48 49 /*************************************************/ 50 51 //不同的重载函数 52 /*Typeone类型执行函数*/ 53 template<typename T> 54 void func( T&t,Typeone ){ 55 cout<<"接下来是Typeone要做的事!"<<endl;; 56 //具体要执行的代码 57 } 58 59 /*Typetwo类型执行函数*/ 60 template<typename T> 61 void func( T&t,Typetwo ){ 62 cout<<"接下来是Typetwo要做的事情!"<<endl; 63 //具体要执行的代码 64 } 65 66 /*int 类型执行函数*/ 67 template<typename T> 68 void func(T&t,int){ 69 cout<<"接下来是int要做的事情!"<<endl; 70 //具体要执行的代码 71 } 72 73 //控制函数(利用模板函数的参数推导功能) 74 template< typename T > 75 void _func(T a ){ //@@改变处 76 // typename T::type b; 77 // T b; 78 //通过traits 提取类型信息 并定义一个变量 79 typename mytraits<T>::type_category b; 80 func(a,b); 81 } 82 83 //主函数 84 int main(int argc ,char ** argv) 85 { 86 Typeone b; 87 Typetwo d; 88 int c; 89 myiterator<int> e; 90 int *f; 91 myiterator<Typeone>g; 92 93 _func( b ); //1、输出Typeone对应的执行函数 94 _func( d ); //2、输出Typetwo对应的执行函数 95 _func(c); //3、输出int 对应的执行函数 96 _func(e); //4、会输出int 对应的执行函数 97 _func(f); //5、会输出int对应的执行函数 98 _func(g); //6、会输出Typeone对应的函数 99 100 return 0; 101 }
上述代码运行结果图:
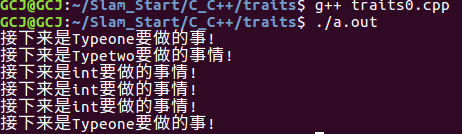
从代码中我们可以看出,相比方法(3)对应的代码,这里变动的地方就是多加了特性萃取器那部分的代码,然后在控制函数中,定义变量的时候用到了traits技术。实际上特性萃取器那部分的代码正是traits技法的核心,通过模板的特化(针对Typeone Typetwo int 等类型,其他类型也可以自己添加)和偏特化(int * 或者其他类型的指针类型),使其适应各种不同的类型变量。这里尤其说一下对于指针类型的说明。通过模板的偏特化当我们_func(指针变量如int*)的时候,在控制函数中通过模板的参数推导,在mytraits<T>::type_category中T被推导为了int *,通过特性提取。即对应mytraits模板类的偏特化--指针类型版本。使得mytraits<T>::type_category的类型为int ,所以在控制函数中变量b的类型就是int型,当调用func(a,b)的时候,我们仍然能够保持a的类型是指针类型int *,但是b是其指针指向的类型int。对于main函数中的Typeone Typetwo等等的类型,也是通过特性萃取器对应的特化版本来实现类型的提取。引用一篇博客的一句话:"当函数,类或者一些封装的通用算法中的某些部分会因为数据类型不同而导致处理或逻辑不同时,traits会是一种很好的解决方案。"。
总结:
对于上述伪码部分if else if带来的不好的地方,事先不知道变量的类型并且代码量会很多。我们用了函数重载以及模板函数的参数类型推导来解决了这个问题,但是当我们提出更高的要求时,控制函数本身算法不能动的前提下,我们想到了用内嵌类型将所有内置类型包装起来。也就是方法(3),但是又不符合我们平时调用函数的习惯。更重要的一点是内嵌类型或者说迭代器方法不能适用于指针类型就是方法(3)引用代码例子。为了更好的解决编译时刻即能确定类型。又能适应指针类型的要求时,我们引出了traits技术。优点是:编译时刻确定类型(而且能够确定 内置类型+指针类型+类类型) 并且结合重载函数可以在编译时刻确定具体要执行的代码。 也就是相当于#if #endif将需要的代码编译到可执行文件,其余无用的代码自动舍掉。通过上面的一步步的深入。你也就会明白这句话的意思了。如果上面某些话或者例子不对,希望读者留言。帮我加深对traits技法的理解。
参考资料:
1、http://www.cnblogs.com/mangoyuan/p/6446046.html
2、Effective C++
3、https://www.bbsmax.com/A/gAJGPLQX5Z/
4、http://blog.pfan.cn/rickone/32496.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号