爬虫第一至第三次作业
作业①
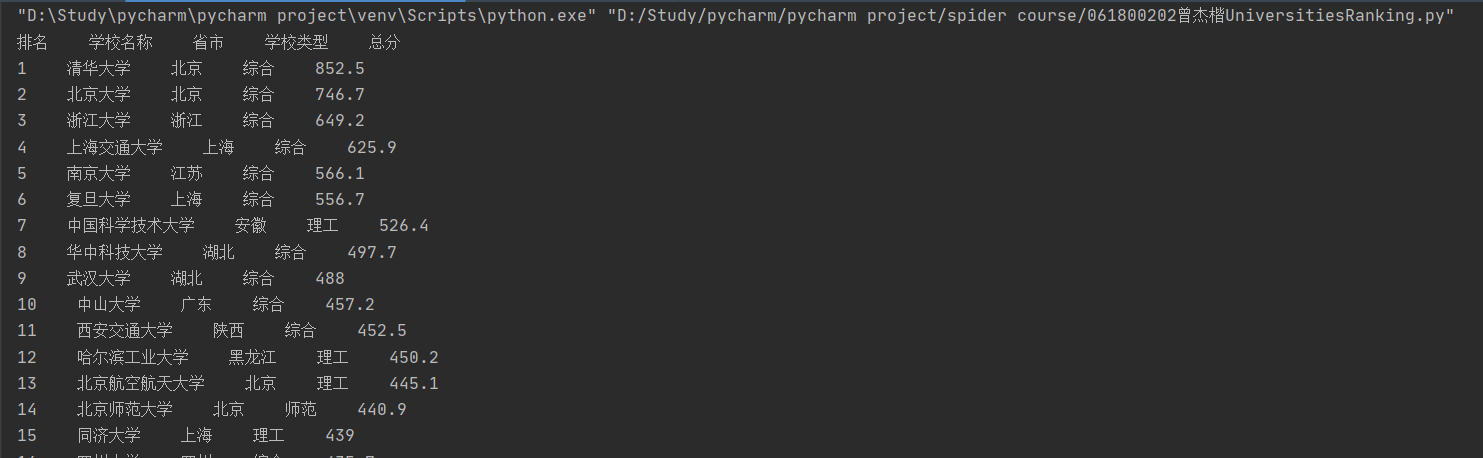
1)、UniversitiesRanking实验
import urllib.request
from bs4 import BeautifulSoup
req=urllib.request.Request(url='http://www.shanghairanking.cn/rankings/bcur/2020')
data=urllib.request.urlopen(req)
data=data.read()
soup=BeautifulSoup(data,"lxml")
schools=soup.select("tbody tr")
print("排名 学校名称 省市 学校类型 总分")
for school in schools:
try:
rank=school.select('td')[0].text
name=school.select('td')[1].text
province=school.select('td')[2].text
schooltype=school.select('td')[3].text
score=school.select('td')[4].text
print(rank.strip()+" "+name.strip()+" "+province.strip()+" "+schooltype.strip()+" "+score.strip())
except Exception as err:
print(err)
2)、心得体会
本次作业是要求爬取网站上的大学排名信息,通过利用BeautifulSoup讲网页的数据读进来,并通过在网页上利用F12的功能,查看网页的编排情况,通过观察发现我们所需要的信息都是保存在tbody标签下的tr标签下的td标签里。然后利用select函数挑出我们需要的内容,并调整格式输出。本次实验是本课程的第一次作业,通过此次作业我更好地掌握了如何通过观察网页的HTML结构来获取我所需要的信息。标签的信息是我们进行爬虫的一个很重要的信息。
作业②
1)、GoodsPrices实验
import urllib.request
from bs4 import BeautifulSoup
# 爬取的网址是在京东商城上,以书包为关键词搜索,爬取了页面上书包的商品名称和价格
url = "https://search.jd.com/Search?keyword=%E4%B9%A6%E5%8C%85&enc=utf-8&pvid=ef555c7a0f254824b71b1c334e44ee2e"
req=urllib.request.Request(url)
data=urllib.request.urlopen(req)
data=data.read()
soup=BeautifulSoup(data,"lxml")
Goods=soup.select("ul[class='gl-warp clearfix'] li[class='gl-item']")
print("序号 价格 商品名称")
num=0
for goods in Goods:
try:
num=num+1
name=goods.select('div[class="p-name p-name-type-2"] em')[0].text
price=goods.select('div[class="p-price"] i')[0].text
print("{:<5}{:^10}{:>40}".format(num, price, name.replace('\n', '').replace('\r', '')))
except IndexError:
pass

2)、心得体会
本次作业基本是和第一次作业是一样的思路,先到要爬取的京东商品的书包搜索页面下,按下F12,查看网页的HTML结构。观察到我们所需要爬取的商品名称和价格都是存在属性值为class='gl-warp clearfix'的ul标签下的属性值为class='gl-item'的li标签下,商品名称是存在属性值为class="p-name p-name-type-2"的div标签下的em标签,商品价格是存在属性值为class="p-price的div标签下的i标签,由此提取出其中的文本值并按要求输出。在一开始时,我的输出里出现了一些奇怪的东西,经过在网上查询后才知道原来标签里有存在着一些空标签,我没有对这些进行处理这才出现了错误。本次实验加深了我对于网页HTML结构的理解,并巩固了对于标签的提取操作。
PS.第二次修改:同样的程序过了几天又跑了一次,发现读出的内容为空,然后试着在Request函数后面加个headers就解决了,看来京东也是有反爬机制的。
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
req=urllib.request.Request(url,headers=headers)
作业③
1)、JPGFileDownload实验
import urllib.request
from bs4 import BeautifulSoup
def download(url):
global count
try:
count=count+1
if url[len(url) - 4]== ".":
ext=url[len(url) - 4:]
else:
ext=""
req = urllib.request.Request(url)
data = urllib.request.urlopen(req)
data = data.read()
fobj =open("images\\"+str(count)+ext, "wb")
fobj.write(data)
fobj.close()
print("download"+str(count)+ext)
except Exception as err:
print(err)
start_url = "http://xcb.fzu.edu.cn/"
req=urllib.request.Request(start_url)
data=urllib.request.urlopen(req)
data=data.read()
soup=BeautifulSoup(data,"lxml")
imgs=soup.select("img[src$='jpg']") # 筛选出所有jpg格式的
count=0
for image in imgs:
try:
src=image["src"]
url = urllib.request.urljoin(start_url, src)
download(url)
except Exception as err:
print(err)
2)、心得体会
本次作业的主框架还是和之前一样,对网页内容进行读取然后进行遍历并做相关处理。本次实验是多了对于网络图片的下载这一操作,在参考了课本上的代码后,我通过一个download函数来实现这一功能。除此之外,本次实验因为是要求下载网站上的所有jpg格式的图片,因此需要对读取的图片进行一下筛选,src$='jpg'表示的是以jpg为结尾的,由此利用select函数来筛选出所有的jpg格式的图片。通过此次实验我学习到了如何对网站上的图片进行爬取以及对于信息的筛选。
总结
这三次实验有相同的地方,也有不同地方。三次实验的开头基本都是先用BeautifulSoup来读取处理网站上的数据,接着都是得去查看网站的HTTML结构根据需求来写相应的代码,而不同的网站的结构都是不同的,而这就是需要我们自己的观察。这三次作业不断加深了我对于网页的结构的理解,强化了我对于soup的运用的能力,收获满满。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号