软件工程结对编程项目总结博客
22年罗杰软工——结对编程总结博客
- 教学班级:周五班
- 项目地址:https://github.com/neumyor/word-list
预估的项目开发耗时 PSP 表格
在项目开始前,我个人对该项目的开发过程进行了预估,制作了下表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) |
|---|---|---|
| Planning | 计划 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 20 |
| Development | 开发 | 1480 |
| · Analysis | · 需求分析 (包括学习新技术) | 300 |
| · Design Spec | · 生成设计文档 | 120 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 |
| · Design | · 具体设计 | 200 |
| · Coding | · 具体编码 | 200 |
| · Code Review | · 代码复审 | 200 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 400 |
| Reporting | 报告 | 360 |
| · Test Report | · 测试报告 | 200 |
| · Size Measurement | · 计算工作量 | 100 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 |
| 合计 | 1860 |
在涉及接口时应用封装方法
Information Hiding
信息隐藏(Information Hiding)是指在设计与确定模块时,尽可能让一个模块中的特定信息对于其他不需要这些信息的模块来说是不可访问的。
在接口设计中,我们专注于将每个功能所需的信息进行分离,抽象为单独的模块。模块间的相互信息暴露遵循最小原则,而对信息访问的控制则通过 C++ 的继承实现。在我们的实际工作中可以总结为:
- 合理安排类内成员变量和成员函数的访问修饰符
- 依照调用关系合理安排各层次类之间的继承关系
详细内容可参考后文接口设计与实现章节。
Interface Design
接口设计(Interface Design)遵守面向对象设计的六大设计原则:
- 单一职责原则
- 开闭原则
- 里氏替换原则
- 迪米特法则
- 接口分离原则
- 依赖倒置原则
在这里对六大原则的内容不做详细展开,有兴趣可查看面向对象设计的六大设计原则。
在我们的实际工作中可以总结为:
- 尽可能避免让类承担超过多种职责,以满足单一职责原则
- 尽可能为未来可能发生扩展的功能设计抽象类,来实现开闭原则(比如后文中提到的 Handler 类)
- 里氏替换规则的可替换性由 C++ 语法规范保证,而上下文限制由 design by contract 实现
- 根据依赖倒置原则引入抽象类,实际上是在实现开闭原则的过程中体现的
限于软件规模,我们并不希望建立过于复杂的层次化关系。进一步复杂化层次关系虽然会让程序“从名义上”覆盖六大设计原则,但是势必带来了不必要的复杂度。六大设计原则绝非银弹,因此我们并不盲目追求。
Loose Coupling
松耦合理论(Loose Coupling)属于耦合关系的一种,描述了一种松散的耦合状态:
- 松散:体系要素具有不确定性,处在快速变化中
- 耦合:体系要素之间具有相互联系,维持一定程度的确定性
有许多理论研究者在松耦合理论领域进行了深入的研究。目前学术界可采信的一种结论认为松散耦合通常存在于:
- 要素间的交互频率较低:个人理解是指在软件设计中可以理解为模块间调用关系不要太复杂。
- 要素间存在非直接的关系:比如 A 与 B 通话,A 和 B 按双方约定的格式说话,这样他们的关系就是基于这种约定而形成的非直接关系。
- 要素间存在高度的因果不确定性:要素 A 的设计并不是基于“要素 B 如何如何”,而应该是基于“要素 A 应该做什么”。
- 要素间存在非即时效应:相关要素间的相互影响应存在延滞。
在软件工程中,我们着眼于让模块间的相互依赖尽可能减少。
在我们的实际工作中可以总结为:
- 尽可能让底层函数功能单一
- 在涉及模块间信息传递时尽可能保持简洁和统一(比如后文的 GUI 接口)
计算模块的接口的设计与实现过程
问题分析
输入的单词,可以看成一个有 26 个点的有向图。每个单词是这个图上的一条边,建立一条从首字母到尾字母的边。在没有 -r 的情况下,这是一个有向无环图。
我们要做的,就是在这个图中找到满足要求的一条链。由于图上有许多现成的算法,像后面加速时用到的拓扑排序,强连通分量等,都是图上成型的算法。对于有向无环图来说,这四个问题几乎都可以使用拓扑排序来求解,这就需要求图的每个点的入度。对于有环图来说,可以先求出图的所有强联通分量,再在强连通分量上进行拓扑排序。
模块和接口设计
计算模块的接口主要包括以下四个:
int gen_chains_all(char* words[], int len, char* result[])
int gen_chain_word(char* words[], int len, char* result[], char head, char tail, bool allowRing)
int gen_chain_word_unique(char* words[], int len, char* result[])
int gen_chain_char(char* words[], int len, char* result[], char head, char tail, bool allowRing)
我们约定:
words:传入读入的文件内容,数组中每个元素都是一个单词的头指针,单词均以'\0'结尾len:传入的words长度results:用于接收返回的结果,需要由调用者为其申请长度为MAX_RESULT_LINE(20000+5)空间用于存储结果head:传入指定的单词链首字母,若指定则必须为小写,若不指定则传入0tail:传入指定的单词链尾字母,若指定则必须为小写,若不指定则传入0allowRing:传入是否允许传入的words对应的单词链中存在循环- 返回值:
- 对
gen_chains_all,返回最多单词数量的最长单词链的单词数量 - 对
gen_chain_word,返回所有符合定义的单词链的数量 - 对
gen_chain_word_unique,返回首字母不同的单词数最多的单词链的单词数量 - 对
gen_chain_char,返回最多字母数量的最长单词链的字母数量
- 对
对于四种处理需求,设计了四个类,分别进行处理。由于这四个处理需求有一些相同的部分,可以进行一部分代码的复用。最多单词数和最长单词链,两个需求比较接近,又都有可能出现环,因此它们可以复用的代码更多。
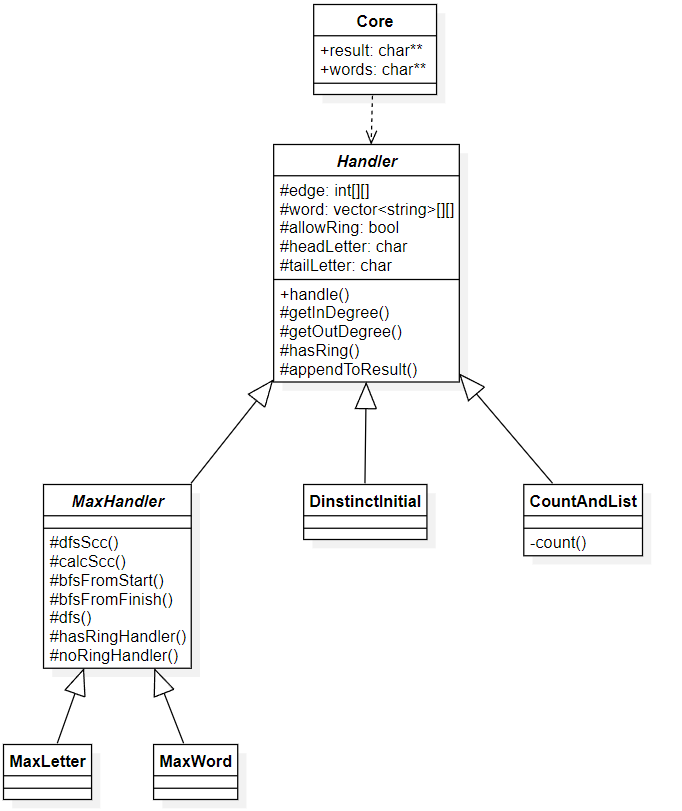
为实现功能,我们创建了一个基类 Handler,包含建的图,提供计算这个图每个节点入度出度的接口。同时提供一个 handle 虚方法,由继承它的子类去实现。
四个所需处理的需求,每个定义一个类。其中列出所有单词链和首字母不能重复的两个功能,不能有其他参数,它们直接继承基类。建一个 MaxHandler 类,继承 Handler,存储其他参数的信息。计算最多单词数和最多字母数的两个类,继承这个 MaxHandler 类。
对外,还定义了一个 Core 类,并提供了四个静态函数,分别对应了四种需求。每种需求只需要传入单词数组,经过 handle 函数计算后,最终将结果写入参数中的指定地址,并返回结果的总行数(在处理-c时返回的是总字符数)。
使用命令行输入数据时,还需要先对参数进行解析,并从文件中将所需的内容读出,然后调用 Core 类的接口。
为了提供命令行指令异常的相关测试和GUI接口,我们还在主程序中添加了call_by_cmd接口。该接口接收一个字符串形式的命令行指令并进行解析,然后调用计算模块。该模块可以用于单元测试时对指令异常的处理测试,也可直接提供给GUI作为前后端交流的接口。值得指出的是,该接口是独立的,即使我们采用了cmd这一词来表示指令,但是这与win平台的cmd完全没有关系。
程序流程
程序的入口处,会调用 read 方法进行参数的解析和数据的读入。然后将读入数据根据不同需求调用 Core 类的不同方法进行处理。
在处理时,会先根据参数实例化一个该需求类型的对象。在对象的创建时,会将输入的单词列表转化为矩阵存储的有向图形式。在这时,做了一个特殊的处理:如果一条边起点入度为 0,终点出度为 0,那么这条边就永远不会产生贡献,就不需要在图中加入这条边。这个方法,十分有效地解决了后面,尤其是最多字母问题时,找到的结果只有一个单词,不构成单词链的情况。
对于列出所有单词链和首字母不能重复单词链的两个功能,不会有其他参数。它们的 handle 方法会比较简单地进行处理。而最多单词数和最多字母数需求,可能有无环和有环两种可能。根据是否允许有环,程序将问题分别交给 allowRing 和 noRing 来处理。
计算模块部分各实体间关系(UML)
斜体表示抽象类
为了清晰简明,省略了子类实现的父类方法,以及部分内部成员变量
计算模块接口部分的性能改进
针对无环和有环情况,我们分别设计了算法,以提升其计算性能。
花费的时间
为了提升性能,我们在修改代码上花费了大量的时间(两次结对编程,耗时4个小时左右)。
性能分析
由于数据限制问题,无环状态下的极限用例也无法对程序造成足够大的负载。
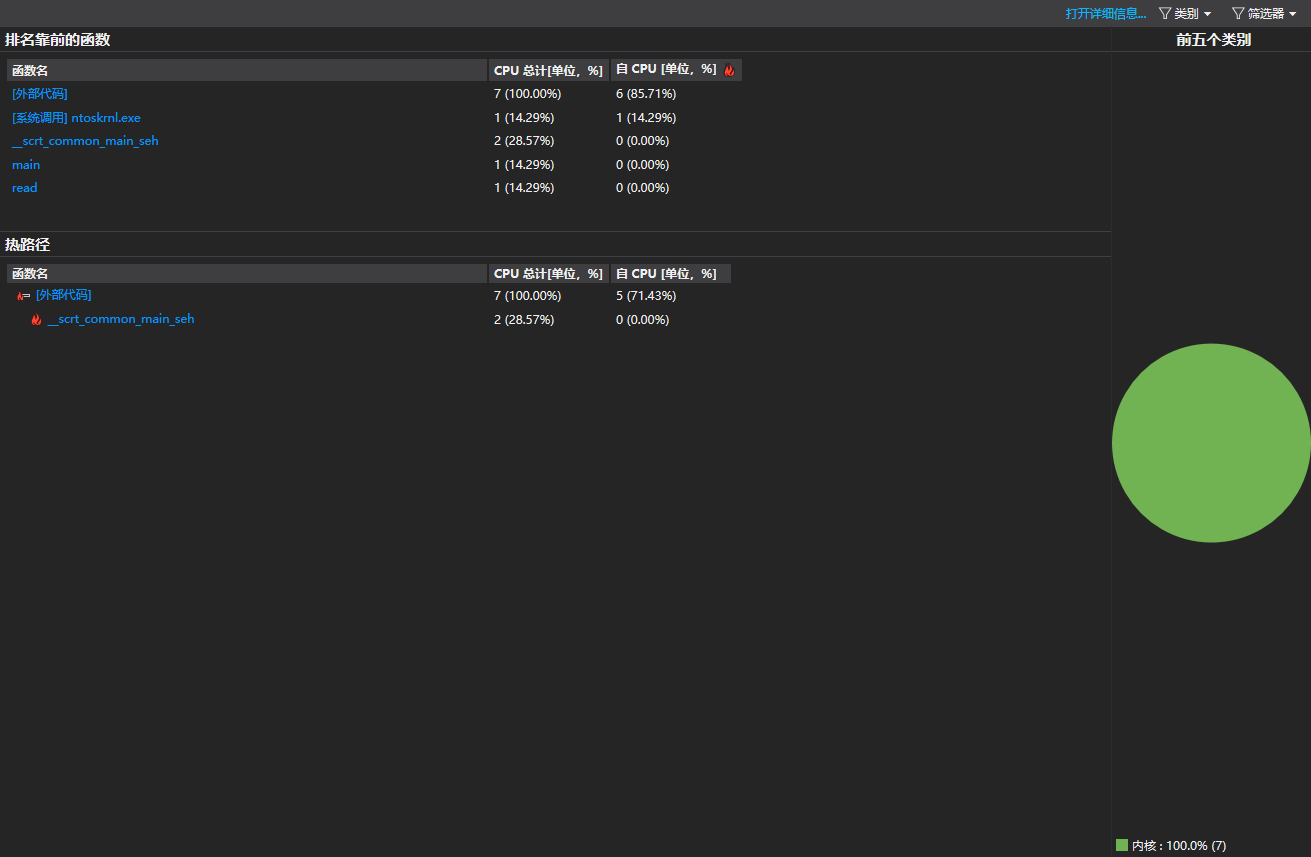
主要性能瓶颈在有环部分,其dfs过程构成了主要耗时。
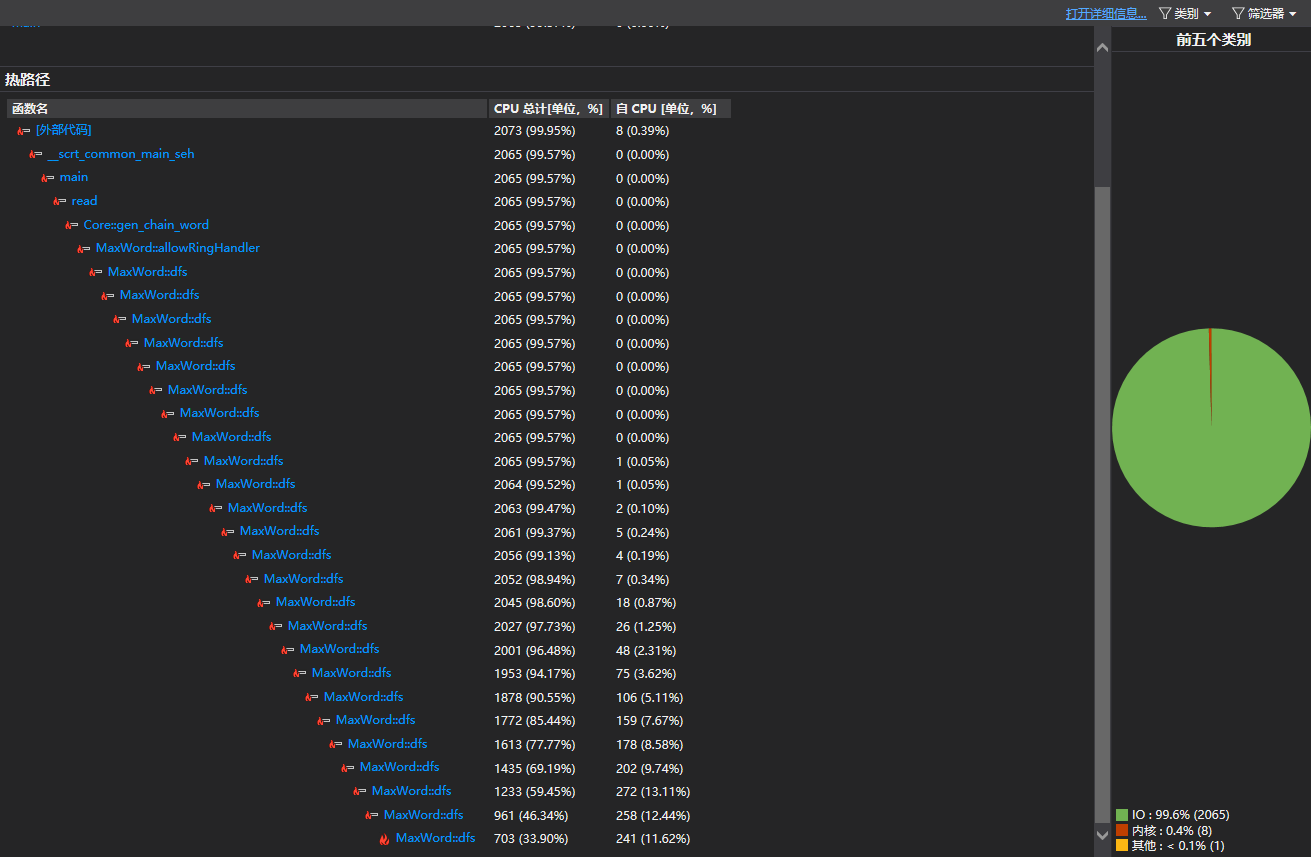
展示耗时最大的函数dfs
void dfs(int cur, int start, int length) {
route[length] = cur;
if (length > maxLength[start][cur]) {
for (int i = 0; i <= length; i++) {
maxRoute[start][cur][i] = route[i];
}
maxLength[start][cur] = length;
}
for (auto & i : sccElement[sccBelong[start]]) {
if (edge[cur][i] > used[cur][i]) {
used[cur][i]++;
dfs(i, start, length + 1);
used[cur][i]--;
}
}
}
无环情况的改进思路
对于有向无环图,最好的方法就是拓扑排序 + 动态规划。
有向无环图存在拓扑序,可以 dp 计算出以每个节点结尾的最优情况。不妨看最复杂的,最多字母数单词链需求。这个需求等价于找有向图上的最长链,其中有向图的边权就是单词的长度。
对于节点 \(v\),所有直接可达 \(v\) 的节点集合记作 \(in_v\)。设以 \(i\) 结尾的最多字母单词链字母数为 \(f_i\)(这里允许单词链只有一个单词)。假设对 \(\forall i\in in_v\),\(f_i\) 均已知,则
其中 \(self_v\) 表示节点 \(v\) 最大的一个自环,即最长的首尾字母均是 \(v\) 的单词的字母数,不存在则为 0。由于拓扑序的特性,我们可以按照拓扑序,用线性时间得到这个结果。
对于最多单词数需求,只需将所有边的边权设为 1 即可。对于首字母不同的需求,\(self_v\) 都是 0,只有在终点可能为 1。
如果首字母有限制,就先 BFS 一遍,得到这个首字母所能抵达的节点,构建子图。如果尾字母有限制,假设是 \(t\),最终的结果就一定是 \(f_t\)。
有环情况的改进思路
对于有环图,采用了 Tarjan 缩点 + BFS 求所有可能起点 + 拓扑排序的方式。
首先,使用 Tarjan 算法计算所有的强连通分量。对不同强连通分量,可以使用拓扑排序 + 动态规划进行计算。从每个强连通分量内可能作为起点的点开始进行 DFS,记录到达该强连通分量其他点的最长路径。
而一个强连通分量哪些点可能作为起点呢?这就需要由 BFS 进行计算。如果没有指定单词链首字母,那么起点一定是一个入度为 0 的强连通分量中的点。除了入度为 0 的强连通分量,如果一个点没有直接来自其他强连通分量的点进入它,那它就不可能作为这个强连通分量的入口。如果指定了单词链尾字母,而这个强连通分量无法达到尾字母,那么这个强连通分量也没有意义。因此,从所有起点和终点分别进行 BFS,得到所有可能作为强连通分量入口的节点。
得到了强连通分量内部的最优子结果,只需进行拓扑排序,就能计算出最终的结果。
Design By Contract 思想的引入
契约式设计(Design By Contract),其试图在设计程序时明确地规定一个模块单元在调用某个操作前后应当处于何种状态。契约式设计中的核心概念包括:
- 前置条件(precondition)
- 后置条件(postcondition)
- 不变式(invariant)
在实际代码中,我们在开发过程中的代码添加了断言以实现契约式设计,以及在调试过程中通过追溯函数的前置条件和后置条件来寻找BUG,极大地降低了我们调试的难度。同时,在结对编程过程中同时采用契约式编程和实时代码审查,让我们能够将大部分BUG扼杀在编码过程中。
为了程序效率,我们在测试完成后提交的代码中删除了断言检查
本文中不对契约式设计的具体实现和方法论进行讨论,仅探讨个人对契约式设计优缺点的一些看法:
- 优点:无论是理论上还是实践上,契约式设计大幅提高了软件工程的质量,这毋庸置疑。
- 缺点:契约式设计会带来较高的额外编码时间与人力开销。同时,对于大型软件的开发,团队内还需要对契约式设计的描述方式进行统一规范,比如使用建模语言等,进一步提高了学习成本。
Code Contract 是由微软开发的用于实现契约式设计的插件,用于对 .NET 编程提供运行时检查、静态检查和文档生成。由于本次作业采用 C++ 语言进行开发,未采用 Code Contract 插件,故不再评价。
计算模块部分单元测试展示
对 Core 所暴露的五个接口进行了测试;
int gen_chain_word(char* words[], int len, char* result[], char head, char tail, bool enable_loop);
int gen_chains_all(char* words[], int len, char* result[]);
int gen_chain_word_unique(char* words[], int len, char* result[]);
int gen_chain_char(char* words[], int len, char* result[], char head, char tail, bool enable_loop);
char* call_by_cmd(int len, char* cmd)
构造数据的思路
构造数据的思路主要遵循:
- 重视边界条件和特例
- 根据题目要求形成构造数据的决策树,树的叶子节点分别对应一种类型的数据
- 比如“(单词链)至少 2 个单词组成,前一单词的尾字母为后一单词的首字母,且不存在重复单词”,则可构造决策树,决策节点包括“单词链是否包含至少两个单词”以及“单词链是否包含重复单词”
最终构造数据的决策树节点包括:
- 分割符是空格还是其他非英文字符
- 输入单词是否大写
- 输入是否是连续英文字符
- 输入是否为空
- 输入是否包含单词环
- 在不考虑单词链必须包含至少两个单词的情况下,对应输出的单词链是否包含至少两个单词
- 在不考虑单词链不能包含重复单词的情况下,对应输出的单词链是否包含重复单词
- 是否指定头尾字符
- 头尾字符是否存在
- 是否指定允许单词环
- 其他(在开发过程中随机测试测出 BUG 的样例,用于回归测试)
具体单元测试过程中,我们使用的样例可能同时覆盖多个决策树节点。
部分单元测试代码
以下代码用于测试gen_chain_word接口,主要构造无环情况下的用例,通过validateChain()函数来检查单词链正确性。
TEST_METHOD(TestCoreW_1) {
char* result[MAX_RESULT_LINE];
std::vector<char*> words(0);
int inputSize = generateExample(words, "ab bc cd de ee xy yz zg ef ff fg gg gh hi ij jk kl lm mn");
Assert::AreEqual(Core::gen_chain_word(&(words[0]), inputSize, result, 0, 0, false), 16);
Assert::IsTrue(validateChain(result, 15));
Assert::AreEqual(Core::gen_chain_word(&(words[0]), inputSize, result, 0, 'k', false), 13);
Assert::IsTrue(validateChain(result, 13));
Assert::AreEqual(Core::gen_chain_word(&(words[0]), inputSize, result, 'e', 'k', false), 9);
Assert::IsTrue(validateChain(result, 9));
Assert::AreEqual(Core::gen_chain_word(&(words[0]), inputSize, result, 'i', 'z', false), 0);
}
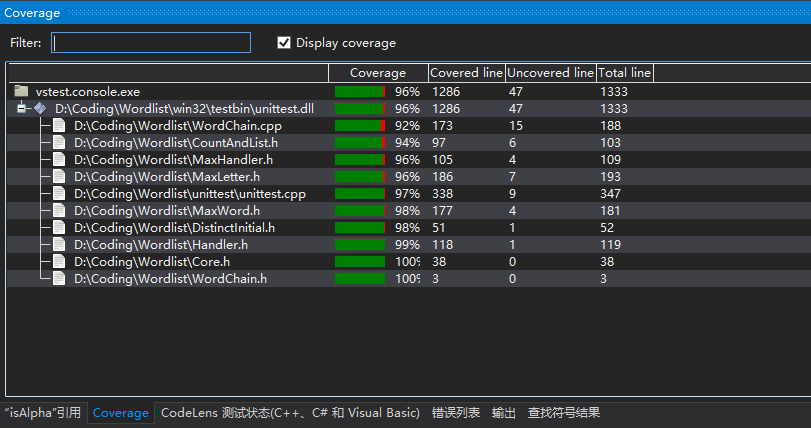
代码覆盖率截图
计算模块部分异常处理说明
我们从命令行指令的角度为以下情况设计了以下的异常处理:
- 出现异常参数,比如
-g,输出-g is neither a text file nor an argument -h(-t)后为空,输出 need letter after '-h' ('-t')- 多次
-h(-t),输出 multiple head (tail) - 多个文件,输出 multiple files found
- 输入的文件未找到,输出 can't find file
- 未输入文件,输出 no input file
- 未输入类型,输出 unmatch type
- 无
-r参数却有环,输出 has cycle -n或-m模式下有-h(-t)参数,输出warning: head(tail) letter specification is ignored-n或-m模式下有-r参数,输出warning: cycle allowance is ignored
此外,还有以下警告:
-n或-m模式下有-h(-t)参数,输出warning: head(tail) letter specification is ignored-n或-m模式下有-r参数,输出warning: cycle allowance is ignored
异常提醒方式为向标准输出打印提示信息。
对命令行涉及的异常进行单元测试方式可以描述为:
- 在计算模块中暴露一个
call_by_cmd方法对字符串形式的命令行指令进行解析,并将输出重定向到字符串,然后将该字符串返回 - 在单元测试中构造命令行指令传入该函数,并对返回的字符串进行比对
TEST_METHOD(TestCmdError_5) {
string cmd = "传入的命令行指令";
cmd += '\0';
char* cmdArray = (char*)malloc(sizeof(char) * (cmd.size() + 1));
if (cmdArray != NULL) {
strcpy_s(cmdArray, cmd.size(), cmd.c_str());
}
Assert::AreEqual("期望的报错信息", call_by_cmd(cmd.size(), cmdArray));
}
异常处理对应样例
值得注意到,以下测试用例并不是命令行输入,而是一个和命令行输入形式一模一样的字符串
-
出现异常参数,比如
-g,输出-g is neither a text file nor an argument-
wordlist.exe -n temp.txt -gTEST_METHOD(TestCmdError_1_2) { string cmd = "wordlist.exe -n temp.txt -g"; cmd += '\0'; char* cmdArray = (char*)malloc(sizeof(char) * (cmd.size() + 1)); if (cmdArray != NULL) { strcpy_s(cmdArray, cmd.size(), cmd.c_str()); } Assert::AreEqual("-g is neither a text file nor an argument\n", call_by_cmd(cmd.size(), cmdArray)); }
-
-
-h(-t)后为空,输出 need letter after '-h' ('-t')-
wordlist.exe -w temp.txt -h -
wordlist.exe -w temp.txt -tTEST_METHOD(TestCmdError_8_1) { string cmd = "wordlist.exe -w temp.txt -h"; cmd += '\0'; char* cmdArray = (char*)malloc(sizeof(char) * (cmd.size() + 1)); if (cmdArray != NULL) { strcpy_s(cmdArray, cmd.size(), cmd.c_str()); } Assert::AreEqual("need letter after \'-h\'\n", call_by_cmd(cmd.size(), cmdArray)); }
-
-
多次
-h(-t),输出 multiple head (tail)-
wordlist.exe -w temp.txt -h k -h g -
wordlist.exe -w temp.txt -t k -t gTEST_METHOD(TestCmdError_2_1) { string cmd = "wordlist.exe -w temp.txt -h K -h g"; cmd += '\0'; char* cmdArray = (char*)malloc(sizeof(char) * (cmd.size() + 1)); if (cmdArray != NULL) { strcpy_s(cmdArray, cmd.size(), cmd.c_str()); } Assert::AreEqual("multiple head\n", call_by_cmd(cmd.size(), cmdArray)); }
-
-
多个文件,输出 multiple files found
-
wordlist.exe -w temp.txt another.txt -
wordlist.exe -w temp.txt -another.txtTEST_METHOD(TestCmdError_3) { string cmd = "wordlist.exe -w temp.txt another.txt"; cmd += '\0'; char* cmdArray = (char*)malloc(sizeof(char) * (cmd.size() + 1)); if (cmdArray != NULL) { strcpy_s(cmdArray, cmd.size(), cmd.c_str()); } Assert::AreEqual("multiple files found\n", call_by_cmd(cmd.size(), cmdArray)); }
-
-
输入的文件未找到,输出 can't find file
-
wordlist.exe -w another.txtTEST_METHOD(TestCmdError_4) { string cmd = "wordlist.exe -w another.txt"; cmd += '\0'; char* cmdArray = (char*)malloc(sizeof(char) * (cmd.size() + 1)); if (cmdArray != NULL) { strcpy_s(cmdArray, cmd.size(), cmd.c_str()); } Assert::AreEqual("can't find file\n", call_by_cmd(cmd.size(), cmdArray)); }
-
-
未输入文件,输出 no input file
-
wordlist.exe -wTEST_METHOD(TestCmdError_5) { string cmd = "wordlist.exe -w"; cmd += '\0'; char* cmdArray = (char*)malloc(sizeof(char) * (cmd.size() + 1)); if (cmdArray != NULL) { strcpy_s(cmdArray, cmd.size(), cmd.c_str()); } Assert::AreEqual("no input file\n", call_by_cmd(cmd.size(), cmdArray)); }
-
-
未输入类型,输出 unmatch type
-
wordlist.exe temp.txtTEST_METHOD(TestCmdError_6) { string cmd = "wordlist.exe temp.txt"; cmd += '\0'; char* cmdArray = (char*)malloc(sizeof(char) * (cmd.size() + 1)); if (cmdArray != NULL) { strcpy_s(cmdArray, cmd.size(), cmd.c_str()); } Assert::AreEqual("unmatch type\n", call_by_cmd(cmd.size(), cmdArray)); }
-
-
无
-r参数却有环,输出 has cycle-
wordlist.exe -w temp.txtTEST_METHOD(TestCmdError_7) { string cmd = "wordlist.exe -w temp.txt"; cmd += '\0'; char* cmdArray = (char*)malloc(sizeof(char) * (cmd.size() + 1)); if (cmdArray != NULL) { strcpy_s(cmdArray, cmd.size(), cmd.c_str()); } Assert::AreEqual("has cycle\n", call_by_cmd(cmd.size(), cmdArray)); }
-
-
-n或-m模式下有-h(-t)参数,输出warning: head(tail) letter specification is ignored-
wordlist.ext -n temp.txt -h g -
wordlist.ext -m temp.txt -h g -
wordlist.ext -n temp.txt -t g -
wordlist.ext -m temp.txt -t gTEST_METHOD(TestCmdWarning_2) { string cmd = "wordlist.exe -n temp.txt -h f"; cmd += '\0'; char* cmdArray = (char*)malloc(sizeof(char) * (cmd.size() + 1)); if (cmdArray != NULL) { strcpy_s(cmdArray, cmd.size(), cmd.c_str()); } Assert::AreEqual("warning: head letter specification is ignored\nhas cycle\n", call_by_cmd(cmd.size(), cmdArray)); }
-
-
-n或-m模式下有-r参数,输出warning: cycle allowance is ignored-
wordlist.ext -n temp.txt -r -
wordlist.ext -m temp.txt -rTEST_METHOD(TestCmdWarning_1) { string cmd = "wordlist.exe -n temp.txt -r"; cmd += '\0'; char* cmdArray = (char*)malloc(sizeof(char) * (cmd.size() + 1)); if (cmdArray != NULL) { strcpy_s(cmdArray, cmd.size(), cmd.c_str()); } Assert::AreEqual("warning: cycle allowance is ignored\nhas cycle\n", call_by_cmd(cmd.size(), cmdArray)); }
-
界面模块的详细设计过程
CLI 命令行交互界面
该结对项目要求我们为编写的单词链程序实现一个CLI界面,支持-n -w -m -c -h -t -r参数的设置。
参数读取部分,我们采用基本的命令行参数解析方式,以字符处理的方式指定对-n -w -m -c -h -t -r的读入与参数值提取,同时对参数的合法性进行一定检查。如果用户违反了参数配置的约定或数据与文件出现某些问题,则会返回相应的错误或警告提示。
在实际编码中用将参数解析和模块调用相结合的方式,因此支持对运行时异常的处理,以面向过程的方式完成了相关解析和调用的工作。
我们没有调用任何现有的参数解析框架,虽然这使得我们的解析模块较为复杂,但是也给予了我们更大的参数检查与操作的自由度。
static void read(int argc, char *argv[]) {
vector<char*> word;
FILE *file = NULL;
HandlerType type = HandlerType::UNKNOWN;
// 进行参数解析并进行实时检查与报错
for (int i = 1; i < argc; i++) {
if (strcmp(argv[i], "-n") == 0) {
if (type != HandlerType::UNKNOWN) {
cout << "multiple type" << endl;
return;
}
type = HandlerType::COUNT_AND_LIST;
} else if (strcmp(argv[i], "-w") == 0) {
if (type != HandlerType::UNKNOWN) {
cout << "multiple type" << endl;
return;
}
type = HandlerType::MAX_WORD;
} else if (strcmp(argv[i], "-m") == 0) {
if (type != HandlerType::UNKNOWN) {
cout << "multiple type" << endl;
return;
}
type = HandlerType::DISTINCT_INITIAL;
} else if (strcmp(argv[i], "-c") == 0) {
if (type != HandlerType::UNKNOWN) {
cout << "multiple type" << endl;
return;
}
type = HandlerType::MAX_LETTER;
} else if (strcmp(argv[i], "-h") == 0) {
i++;
if (i >= argc || strlen(argv[i]) > 1 || !isAlpha(*argv[i])) {
cout << "need letter after '-h'" << endl;
} else if (headLetter) {
cout << "multiple head" << endl;
} else {
headLetter = toLowercase(*argv[i]);
continue;
}
if (file != NULL) {
fclose(file);
}
return;
} else if (strcmp(argv[i], "-t") == 0) {
i++;
if (i >= argc || strlen(argv[i]) > 1 || !isAlpha(*argv[i])) {
cout << "need letter after '-t'" << endl;
} else if (tailLetter) {
cout << "multiple tail" << endl;
} else {
tailLetter = toLowercase(*argv[i]);
continue;
}
if (file != NULL) {
fclose(file);
}
return;
} else if (strcmp(argv[i], "-r") == 0) {
allowRing = true;
} else {
int l = (int)strlen(argv[i]);
if (l < 4 || argv[i][l - 4] != '.' || argv[i][l - 3] != 't' || argv[i][l - 2] != 'x' || argv[i][l - 1] != 't') {
cout << argv[i] << " is neither a text file nor an argument" << endl;
return;
}
if (file != NULL) {
cout << "multiple files found" << endl;
fclose(file);
return;
}
#ifdef __linux__
file = fopen(argv[i], "r");
#else
fopen_s(&file, argv[i], "r");
#endif
if (file == NULL) {
cout << "can't find file" << endl;
return;
}
}
}
if (file == NULL) {
cout << "no input file" << endl;
return;
}
/* 忽略文件读写过程 */
switch (type) {
case HandlerType::COUNT_AND_LIST:
warning();
ret = Core::gen_chains_all(&word[0], (int)word.size(), result);
// 根据函数返回值,进行异常提醒
if (ret > MAX_RESULT_LINE) {
cout << "too many chains" << endl;
fout << "too many chains" << endl;
} else if (ret >= 0) {
cout << ret << endl;
fout << ret << endl;
}
break;
case HandlerType::DISTINCT_INITIAL:
warning();
ret = Core::gen_chain_word_unique(&word[0], (int)word.size(), result);
break;
case HandlerType::MAX_WORD:
ret = Core::gen_chain_word(&word[0], (int)word.size(), result, headLetter, tailLetter, allowRing);
break;
case HandlerType::MAX_LETTER:
ret = Core::gen_chain_char(&word[0], (int)word.size(), result, headLetter, tailLetter, allowRing);
break;
default:
cout << "unmatch type" << endl;
return;
}
// 根据函数返回值,进行异常提醒
if (ret == -1) {
cout << "has cycle" << endl;
return;
}
for (int i = 0; result[i] != nullptr; i++) {
cout << result[i] << endl;
fout << result[i] << endl;
free(result[i]);
result[i] = nullptr;
}
for (auto &i : word) {
free(i);
}
if (ret > MAX_RESULT_LINE) {
cout << "..." << endl;
}
}
需要特别指出,在调用CLI时请注意:
- 所有四种输出方式均会往
solution.txt进行答案的输出 - 标准输出中除了答案文本,还会包含警告信息和提示信息
- 异常与警告信息向标准输出进行打印
GUI 图像交互界面
该结对项目作业要求为我们编写的单词链程序实现一个 GUI 界面,具体的要求引用原文如下:
界面需正确实现下述功能,会按点给分:
- 支持两种导入单词文本的方式:①导入单词文本文件,②直接在界面上输入单词并提交(3')
- 提供可供用户交互的按钮和,实现
-n -w -m -c -h -t -r这七个参数的功能,对于异常情况需要给予用户提示(3')- 将结果直接输出到界面上,并提供“导出”按钮,将结果保存到用户指定的位置(3')
以上功能全部正确完成,可以获得 10 分满分。【注意】选择完成本附加题目的同学,需要将 GUI 与单词计算模块作为两个工程开发,后者可以作为依赖库为前者提供调用接口,但不可以把两个工程直接混在一起。 GUI 相关的部分也需要提供新的可执行文件,放在根目录的
guibin/文件夹下。
因此,在设计阶段选择图形界面的实现方案前,我们总结了几大技术要点:
- 该实现方案需要能够支持与文件系统的交互,需要能够打开(Windows 环境下的)文件管理器交互界面。
- 该实现方案需要能够直接实时在界面上展示输出。
- 该实现方案需要能够支持将界面上的输出内容导出至文件。
- 该实现方案需要具有一定的响应式特性。
- 该实现方案需要能够弹出提示和警告信息。
- 该实现方案需要能够调用C类型的依赖库。
- 该实现方案需要能够直接转化为可执行文件。
在此基础上我们考量了多种可能的实现方案,并最终选择了 Python 的 wxPython 库进行实现,因为该实现方案具有以下特性:
- Python 的
ctypes库支持直接调用.dll文件中的接口。 - Python 的
pyinstaller工具能够直接将脚本与相关依赖包打包为可执行文件。 - wxPython 提供了
MessageDialog组件来满足提示和警告要求。 - wxPython 可以直接实时读写界面组件中的内容。
- wxPython 提供了
FilePicker等和文件系统交互的组件。 - wxPython 支持对组件的隐藏和重现,实现了一定的响应式功能。
随后,我们对页面排版进行了大致设计,计划如下:
- 页面主要分为左右两大部分
- 左边部分实现交互功能,包括交互按钮、参数选择、输入选择等
- 交互按钮位于左下方,主要包括开始、清空输出、导出到指定文件。
- 输入选择采用单选框形式,选择使用文件或直接输入。
- 参数选择的
-n -w -m -c采用单选框形式,-h -t -r采用多选框形式。 - 对应于各个参数和选项的输入框在初始状态下隐藏,需要在选定该项后才响应式地展示出来。
- 右边部分展示输出
- 多行显示,为
ReadOnly模式 - 支持上下滚动查看
- 多行显示,为
随后进行了编码,下面就主要实现功能相对应的代码进行解释说明;
# 选择输入类型
self.select_input_type_box = wx.RadioBox(self.panel, -1, "选择输入类型", (20, baseline), (150, baseline), ["使用文件作为输入", "使用文本作为输入"])
self.select_input_type_box.Bind(wx.EVT_RADIOBOX, self.select_input_type)
self.file_picker = wx.FilePickerCtrl(self.panel, -1, "选择输入文件", pos=(50, baseline + 60), style=wx.FLP_USE_TEXTCTRL, size=(300, 30))
self.file_picker.Bind(wx.EVT_FILEPICKER_CHANGED, self.select_file)
self.text_input = wx.TextCtrl(self.panel, -1, "请在这里输入你的文本", pos=(50, baseline + 60), size=(400, 40), style=wx.TE_MULTILINE)
self.text_input.Hide()
在响应式的实现上,我们以选择输入方式为例。上述代码中,我们声明了一个单选框,并将文本输入框初始隐藏。随后在将单选事件绑定到 select_input_type 函数,并在该函数内设置相关的参数与组件的展示和隐藏,从而实现响应式。
def select_input_type(self, evt):
selected = self.select_input_type_box.GetSelection()
if selected == 0:
self.use_file = True
else:
self.use_file = False
print(f"use file as input {self.use_file}")
if self.use_file:
self.file_picker.Show()
self.text_input.Hide()
else:
self.text_input.Show()
self.file_picker.Hide()
而在文件系统交互上,我们以导出至指定文件为例。下面的代码中我们通过 Python 的 os 模块配合 wxPython 的 MessaggeDialog 和 FileDialog 组件实现了保存文件的功能,并提供了展示提示与错误的功能。
def download(self, evt):
print("download")
fd = wx.FileDialog(self, '把文件保存到何处', os.getcwd(), '.txt', 'TEXT file(*.txt)|*.txt', wx.FD_SAVE)
if fd.ShowModal() == wx.ID_OK:
file_name = fd.GetFilename()
dir_name = fd.GetDirectory()
try:
with open(os.path.join(dir_name, file_name), 'w', encoding='utf-8') as f:
text = self.output_box.GetValue()
f.write(text)
save_msg = wx.MessageDialog(self, '文件已保存', '提示')
except FileNotFoundError:
save_msg = wx.MessageDialog(self, '保存失败,无效的保存路径', '提示')
else:
save_msg = wx.MessageDialog(self, '未选择保存路径', '错误')
save_msg.ShowModal()
save_msg.Destroy()
界面模块与计算模块的对接
界面模块采用 Python 开发,而计算模块以 .dll 动态链接库的形式提供,而充当极为关键的前后端连接者角色的正是 Python 的 ctypes 模块。
为了使用 ctypes 模块,我们需要同时在计算模块和界面模块中进行一定的改动。
界面模块的改动
def command_exe(self, command):
try:
dll = ctypes.windll.LoadLibrary("core.dll")
call_func = dll.call_by_cmd
call_func.argtypes = [ctypes.c_int, ctypes.POINTER(ctypes.c_char)] # 参数类型为char指针
call_func.restype = ctypes.c_char_p # 返回类型为char指针
result = dll.call_by_cmd(len(command), ctypes.c_char_p(command.encode('utf-8'))).decode("utf-8")
self.output_box.AppendText("执行" + command + '\n')
self.output_box.SetDefaultStyle(wx.TextAttr(wx.BLUE)) # 将后面输出字段设置为蓝色
self.output_box.AppendText(result)
self.output_box.SetDefaultStyle(wx.TextAttr(wx.NullColour)) # 将后面输出字段设置为默认颜色(黑色)
except Exception as e:
self.output_box.SetDefaultStyle(wx.TextAttr(wx.RED)) # 将后面输出字段设置为红色
self.output_box.AppendText('ERROR! ' + command + ' failed!' + '\n')
self.output_box.AppendText(str(e))
self.output_box.SetDefaultStyle(wx.TextAttr(wx.NullColour)) # 将后面输出字段设置为默认颜色(黑色)
self.output_box.AppendText('执行结束\r\n')
self.output_box.AppendText('-------\r\n')
在上述代码中,主要在于我们需要利用 ctypes.windll.LoadLibrary 函数将 .dll 加载到 Python 环境下,然后对调用的接口 call_by_cmd 的参数情况进行声明(argtypes 和 restype)。注意这里的参数声明方式也是采用 ctypes 模块的数据类型进行声明的,比如 c_char_p 对应C语言环境下的 char*。
计算模块的改动
extern "C" {
__declspec(dllexport) char* __stdcall call_by_cmd(int len, char* cmd);
}
为了将接口暴露给 ctypes 模块进行调用,计算模块的源码中也需要额外对接口函数进行修饰。以上的修饰分别对应着:
extern "C":为了暴露给ctypes模块而特有的外部声明。__stdcall:声明调用约定,以对应界面模块中的windll,具体对应关系请查看python使用ctypes调用C编译dll函数方法。__declspec:Microsoft 专用的关键字,是一种扩展属性的定义.
实现效果截图
界面各组件功能展示
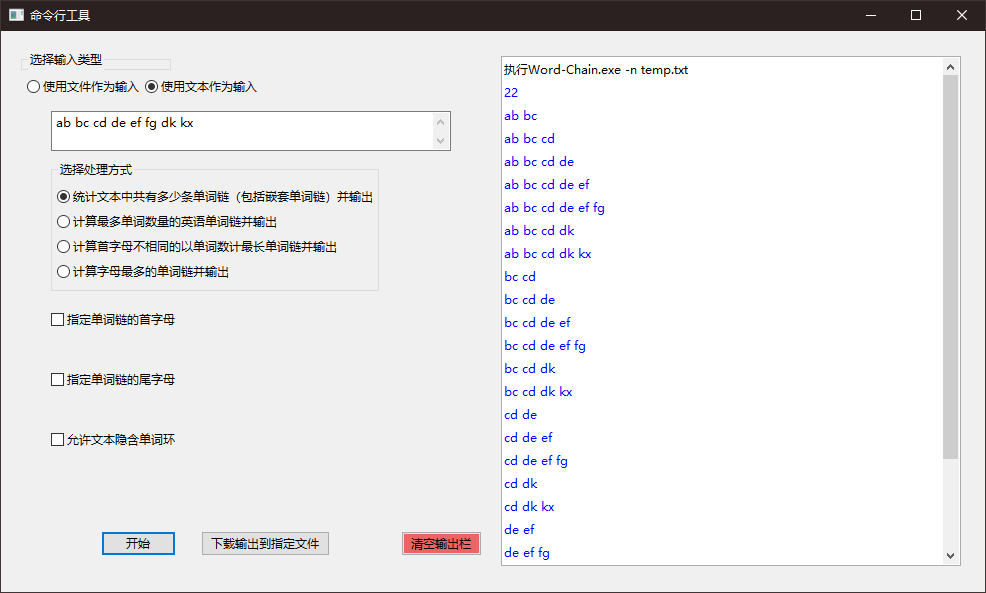
报错与提示功能展示
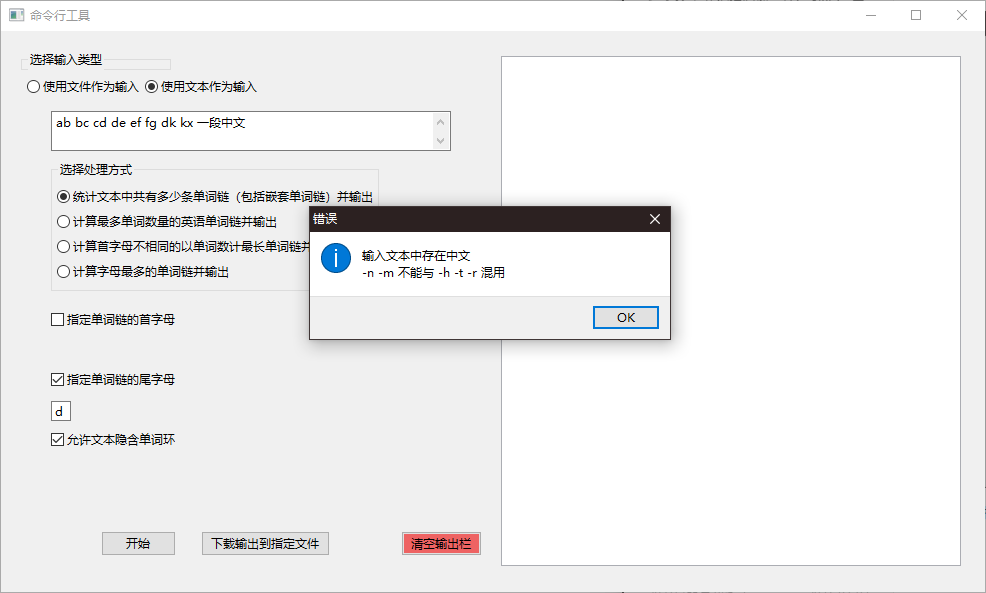
文件系统交互展示
与其他小组交换测试松耦合
我们与其他小组进行模块的互换以检查我们程序的松耦合性。
其他小组的两位成员:
- 19373118 薛欣
- 19373469 陈纪源
他们组采用了C#进行项目编写,同时具有多个.dll文件。
在模块交换合并的过程中,我们组主要发现了下列问题:
- 对方采取的前后端交互策略与我们组不同,需要修改前端的界面读取逻辑
- 对方采取的异常处理定义与我们组不同,需要修改报错逻辑
在经过充分的沟通交流并解决一些模块定义上的误解后,我们成功完成了松耦合实验。
对方组通过前后端对接发现了我们组存在的一个问题:
- 我们提供给对方组的代码时Debug模式下生成的,因此会进行下标检查。而生成的exe文件为了算法效率,是在Release模式下生成的,并没有嵌入调试代码。同样,为了测试
.exe文件的正确性,单元测试的代码也是在Release模式下生成的。 - 当输入的
.txt文件为空时,在代码中一处我们会将首地址进行传递,而获取首地址的方式是&array[0]。Debug模式下这里会因为下标问题而抛出异常,但是Release模式下可以正常获取,这就导致了单元测试结果与GUI使用结果不符。
之后我们将GUI使用的.dll文件也改为Release模式下生成,从而解决了上述问题。
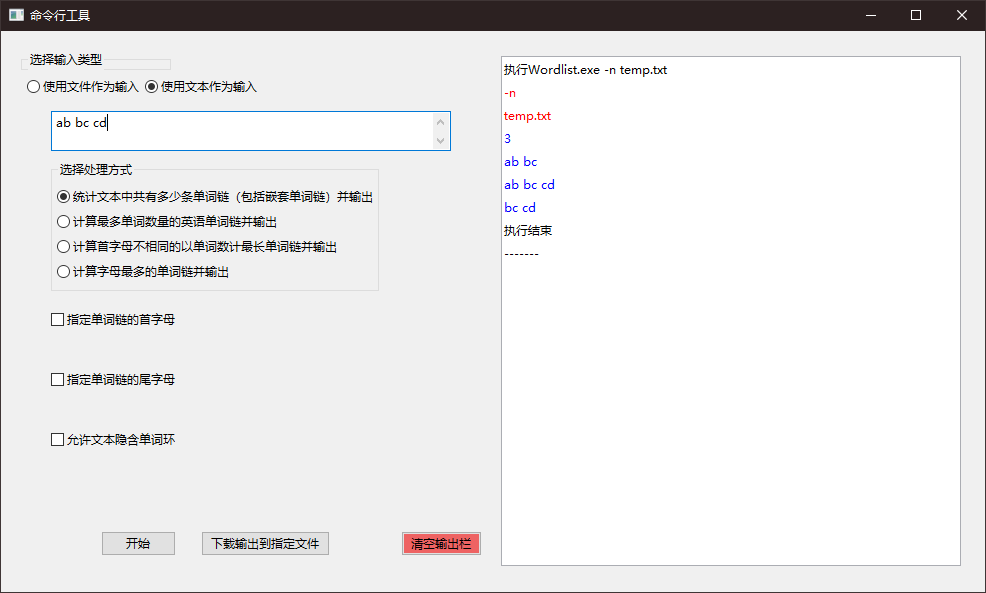
交换后效果截图如下:
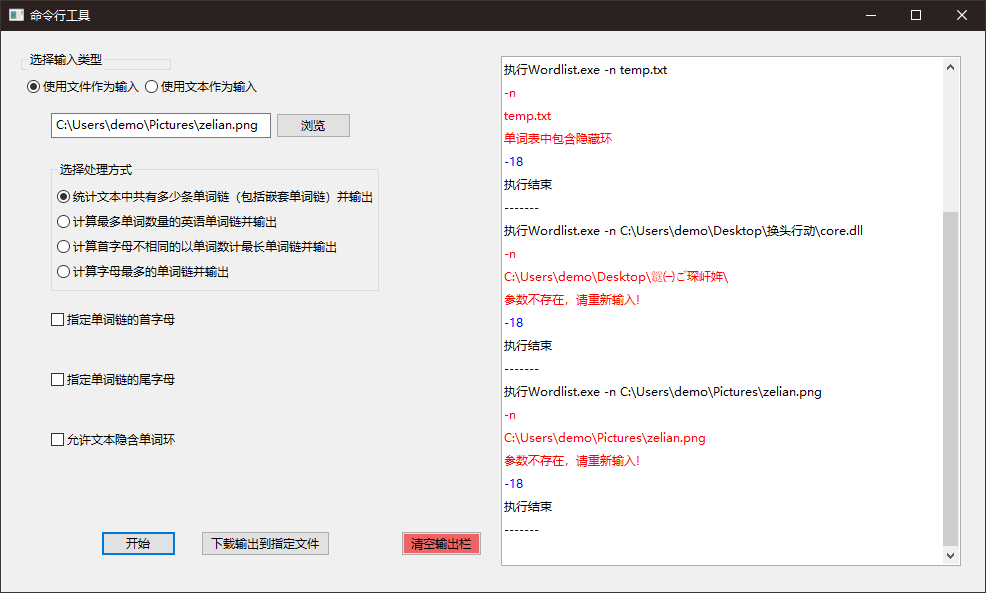
结对编程的过程
在结对过程中,我们始终保持两个人的交流。
为了真真正正地进行结对编程,我额外搬来一套桌椅放在我旁边。
为什么要额外突出呢?因为扛一套桌椅到宿舍工作量真的不小!

我们将每次结对编程规范为以下流程:
- 提前约定一个时间段进行结对编程。
- 开始结对编程前确认一个当前阶段目标。
- 使用同一台电脑、同一个显示屏、同一套键鼠。
- 一人开始编程,一人在旁审查代码和对照博客要求
- 每完成一个小阶段(比如一个函数或模块,约 40 分钟)交换角色
- 通常一个阶段长度在2~ 4 个小时
- 结束后吃点东西,休息交流一下
在结对编程过程中,我们互相审查对方的代码,并互相为对方在代码测试前就指出代码逻辑上的 BUG,极大地减少了测试后修复 BUG 的耗时。同时,我们也可以在编程遇到技术瓶颈时交流意见,互相提供新思路。
组队成员中另一位同学对 Visual Studio 的使用不甚熟悉,而我对 C++ 的语法标准不甚了解。因此我们两人在结对编程的交流过程中不断互补学习,经常在结对编程结束后就一些问题进行深入交流。经过这一次结对编程,我了解了很多 C++ 的有趣知识,比如 nullptr 和 NULL 的区别等。同时另一位同学也了解了如何使用 Visual Studio 进行项目开发以及面向对象的相关知识。
我和郭佬是旧相识,两个人也都是属于友善而有原则的人,因此在整个结对过程中,我们二人经常就某些问题持有不同观点,但是都能心平气和地讨论出一个一致的结论。在讨论过程中我们对彼此的了解也更加深入,进一步深化了我们俩的友情。
就我个人而言,郭佬在讨论过程中展现出的对 C++ 的深入理解和近乎本能般的性能调优能力实实在在地折服了我,让我体会到什么才是一个真真正正的 C++ 大佬。
个人对结对编程的理解
第一次尝试结对编程是一段非常有意思的经历。
优点
- 两人能够实现相互的监督,使得我们都能更加专心于工作
- 不间断地对代码进行审查,使得很多 BUG 在测试前就被发现,极大地降低了后期调试 DEBUG 的难度
- 相互就某些遇到的瓶颈问题交换意见,开放思维避免走进死胡同
- 在调试了很久也没能解决问题时相互鼓励,避免心情低落
缺点
- 需要磨合
- 我和郭同学是旧相识,因此可以把他拉到宿舍来极限 Coding,并且在编程过程中很直截了当地指出他的错误,以及向他请教 C++ 的若干问题。
- 但是如果我们以前从不认识的话,很难想象两个害羞的码农该如何合作。
- 在二者编程能力方向差异较大时带来麻烦
- 我主要擅长各种工具和编程理论的使用。
- 郭佬主要擅长编程与性能调优。
- 每次结对编程的工作目标是唯一的,工作内容大多是同质的。这也就意味着会出现我对性能调优一头雾水而郭佬在旁边不断指点,或者郭佬对着 Visual Studio 的界面一头雾水而我在旁边为他逐个解释。
- 虽然这样能丰富我们二人的知识,但是就工作而言,在前期会比较影响工作效率。
对结对编程伙伴的评价
郭佬真的厉害!
优点:
- C++基本知识非常扎实,对潜在的语法问题非常敏感
- 对算法和性能优化有独到见解,其提出的算法性能非常好
- 为人和善且有责任心,催他debug和约来宿舍结对编程时随时都能联系上
缺点:
- 对Visual Studio是真不熟
自评
优点:
- 新工具上手快
- 宅男,在宿舍随时待命
- 器材控,能提供舒适的编程环境
缺点:
- 没有用C++开发过项目
- Git的高级指令不是很懂
实际的项目开发耗时PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 200 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 200 |
| Development | 开发 | 1480 | 1580 |
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 200 |
| · Design Spec | · 生成设计文档 | 120 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| · Design | · 具体设计 | 200 | 150 |
| · Coding | · 具体编码 | 200 | 600 |
| · Code Review | · 代码复审 | 200 | 与编码同步进行 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 400 | 500 |
| Reporting | 报告 | 360 | 380 |
| · Test Report | · 测试报告 | 200 | 300 |
| · Size Measurement | · 计算工作量 | 100 | 50 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 30 |
| 合计 | 1860 | 2160 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号