21/7/18 读书笔记 基于密度的聚类 基于图的聚类
21/7/18 读书笔记
数据挖掘导论 基于密度的聚类
之前学习的DBSCAN是一种基础的基于密度的聚类方法。本节中讨论其他基于密度的聚类方法,主要包括基于网格的聚类方法和基于核函数的聚类方法。本节探讨的主要问题有:
- 密度的定义带来的若干问题
- 对于子空间簇的搜索问题
- 基于网格的聚类优化
基于网格的聚类方法
网格是一种有效地组织数据集的方法。回想DBSCAN中,我们以欧几里得距离计算密度,这导致我们的时间复杂度是\(O(m^2)\)。而基于网格化,我们可以在一次遍历中就将所有的点指派到特定的网格,并在遍历结束后得到每个网格中的点的个数,因此其密度的计算只需要\(O(m)\)的复杂度。同时基于网格的聚类方法通常也只记录非空的网格,并利用搜索树优化邻近网格的访问,使得其效率具有明显优势。
由于网格的面积是提前设定的,网格中的密度可以用点数计算表示。我们考虑网格技术中的几个具体问题:
- 如何定义网格:存在多种方法将属性空间进行划分,常用的方法就是划分为等宽的离散区间。不过也可以采用等频率离散化等其他方法。
- 由邻近的稠密网格形成簇:我们将密度低于阈值的网格视作噪声,而由于网格大小的细度现在,有时数据点只相对密集地分别在网格的一部分面积中,而其他面积基本是空的,这种情况时常出现在簇的圆形边界上。如果阈值过稿,会使得这部分数据点丢失。如果过低,则无法有效区分噪声和离群点。
- 高维度下的低效性:正如之前所讨论的,高维数据下,很多网格都可能是空的,此时的聚类效果会很差
子空间聚类
我们通常使用所有的属性来进行聚类,但是很多情况下,高维度中不形成簇的数据,在低维度中表现出明显的聚类特性。比如我们考虑图书馆的数据,如果只考虑书的种类和他们所处的阅览室编号,我们可以很容易地发现他们的聚类关系。但是如果我们加入对于价格的考虑,由于在价格空间内的分散性,会导致聚类后的单元内的密度明显降低,聚类效果下降。
通常来说,子空间聚类问题中有两个重要事实:
- 一个点集可能在整个高维空间内不形成簇,但是在某个子空间中形成簇
- 一个在更高维存在的簇会在更低维度同样作为簇出现,这个簇是更高维的投影
书中介绍了CLustering In QUEst,CLIQUE算法,其将上述的第二点试试纳入考虑,基于先验原理:一个高维度的簇在低维度的投影一定也形成簇,避免了对所有子空间簇进行遍历。
回想我们在讨论Apriori算法时的先验原理:一个频繁项集的子集一定是频繁项集。事实上,我们也可以看到CLIQUE算法在思想上与Apriori算法的相似性。其先验原理同样保证了候选集的完备性。
- 令k=1,找出对应于每个一维属性的所有稠密区域,形成稠密的一维单元的集合
- k加一,通过稠密的k-1维单元形成候选的k维单元
- 从候选k维单元中删除不满足阈值要求的单元,得到稠密k维单元,回到第二步
- 直到不再存在稠密的k维单元,我们取所有邻接的高密度单元得到簇
CLIQUE算法的优点在于像Apriori算法一样减少了对簇的遍历,而缺点也是由于这种相似性导致允许簇之间共享对象,使得最终得出的簇个数大幅上升。另一个问题是,CLIQUE在判断不同维度的单元是否稠密时,使用了相同的阈值,这与高维度下密度下降的客观情况不相符,使得得到更高维度下的稠密单元更少。
基于核函数的方案
核函数描述了空间内一个点对于其附近空间的值(比如密度)的影响。通常来说,一个点对于周围空间的密度影响随着距离而减小,比如高斯函数是一种常用的核函数:
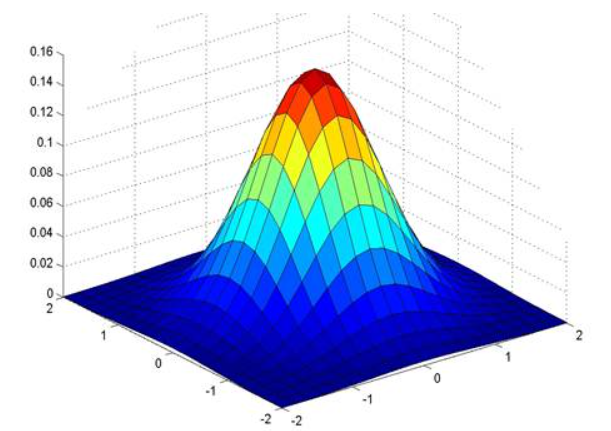
而对于空间内任意一处位置,其受所有数据点的作用之和称为该点处的结果总密度函数,这个函数在空间内通常连续分布,并在有的点呈现出特定的尖峰,称为局部密度吸引点。
本书介绍的DENsity CLUstEring, DENCLUE算法利用核函数给出了一个描述聚类问题的思路:对于空间内的结果总密度函数指定一个阈值,低于阈值的空间将被排除,然后所有在阈值线以上的连续的空间各自构成一个簇。更实际地,如果一个局部密度吸引点和另一个局部密度吸引点之间的数据点路径均大于阈值,那么则两个密度吸引点附近的处于高于阈值的区域内的点构成同一个簇,具体描述为:
- 利用数据点推导全局的结果总密度函数
- 识别出局部密度吸引点
- 对于每个数据点,通过沿密度增长最大的方向移动,指派到唯一的局部密度吸引点
- 指派到同一个吸引点的数据点构成一个簇
- 丢弃密度吸引点处结果总密度函数低于阈值的簇
- 合并那些能够通过密度大于阈值的数据点相连的簇
事实上,如果计算所有的数据点的影响来计算全局的总密度函数,将会导致很高的计算复杂度。因此DENCLUE算法提出利用网格进行优化,即像之前的方法将所有点指派到相应网格中,然后在计算总密度函数时,只考虑周围邻近网格内的数据点造成的影响。由于核函数的性质,距离较远时的影响可忽略,因此这种方法在降低计算复杂度的同时不会对最终结果产生较大影响。
不过尽管优化后,DENCLUE算法仍然具有较高的复杂度,而且无法处理高维数据和密度不同的簇数据。其优点在于可以更好地计算密度这一概念。
数据挖掘导论 基于图的聚类
基于图的观点如此描述空间内的点:每个数据点是一个结点,结点间的边的权值对应于空间内点间距离邻近度。这种聚类方法利用了图的一些重要性质,并基于以下技术进行聚类:
- 稀疏化邻近度图:这种方法使得对象仅保留其与最近邻之间的边,处理噪声和离群点。
- 基于共享的最近邻个数来定义对象间的相似度:对象和其最近邻通常是同一类的,而两个对象具有相同的最近邻的数量决定了他们二者的相似性。这种定义方式能够解决高维度空间内距离的意义衰弱问题和簇的变密度性问题。
- 定义核心对象并构建围绕它的簇:对稀疏化后的邻近度图引入基于密度的概念。
- 利用邻近度图中的信息:两个簇是否合并,仅当在邻近度图中合并后的簇具有与原两个簇的特性。
稀疏化
通过断开邻近度图中低于指定阈值的边,或者仅保留链接到点的k个最近邻的链接,我们能够将邻近度图稀疏化。其好处在于:
- 压缩了数据的存储规模。
- 通过排除j距离较远的点的影响,进行更好的聚类。
- 可以利用图划分的方法。图划分算法业已较为成熟。
通过稀疏化后的邻近度矩阵还可以进行一定的修改,然后再进行稀疏化。这种修改与迭代应当使得稀疏化更加接近于完美的期望簇分布。
图划分技术
书中仅引用了METIS算法,该技术可以将稀疏的矩阵划分为指定个数的区域,每个区域的包含的数据点个数粗略相同。
从Chameleon技术看如何利用自相似性解决层次聚类技术的问题
以往的大部分技术具有一些普遍的问题,比如无法应对密度、形状、大小不同的簇集合。这主要是因为大部分的聚类算法需要基于全局静态的簇模型,比如K均值算法假定了簇是球形,DBSCAN基于某个全局的密度阈值定义簇。这种全局性的限制使得算法无法应对不同的簇特性。我们应当动态地考量聚类标准。
而我们回顾层次聚类技术,不难发现层次聚类技术的聚类标准体现在其决定是否合并两个簇的标准上。之前提到的各种层次聚类的合并标准,比如单链、全链,都无法保证我们对于不同的密度、形状、大小具有适用性,归根结底也是这些标准是全局静态的。
Chameleon技术是一种凝聚聚类技术,其将图划分算法和新的层次聚类技术结合,其关键思想在于:仅当合并后的簇类似原来两个簇时才进行合并,这使得对于聚类的标准从全局的静态的考量转变为需要动态地基于将要合并的簇的情况进行判断,避免了在全局上的限制。Chameleon技术对于何为类似的定义是:合并后的簇应该在接近性和互连性上与原来的簇相近。
-
接近性,用相对接近度(Relative Closeness, RC)衡量,其描述了簇中点相互接近的程度。
\[RC(C_i,C_j)=\frac{\overline{S_{EC}}(C_i,C_j)}{\frac{m_i}{m_i+m_j}\overline{S_{EC}}(C_i)+\frac{m_j}{m_i+m_j}\overline{S_{EC}}(C_j)} \]其中\(C_i,C_j\)对应两个簇,\(m_i,m_j\)对应簇的大小,\(\overline{S_{EC}}(C_i,C_j)\)是连接两个簇的边的平均权值,\(\overline{S_{EC}}(C)\)是簇内部的边的平均权值。RC描述了两个簇之间相连的边与簇内部边的相似性。
-
互连性,用相对互连度(Relative Interconnectivity, RI)衡量,其描述了簇中点相互连接的程度。(注意Chameleon算法的初始化步骤是对邻近度矩阵进行稀疏化,因此对应的稀疏图中有是否连接的区别)
\[RI(C_i,C_j)=\frac{EC(C_i,C_j)}{\frac{1}{2}(EC(C_i)+EC(C_j))} \]其中\(EC(C_i,C_j)\)是连接两个簇的边之和,\(EC(C)\)是簇的割边的最小和。
Chameleon技术利用接近性和互连性的乘积来描述自相似性,自相似性高于阈值的的两个簇才会被合并。其虽然能够解决高维数据和不同密度、大小、形状带来的问题,但是具有较高的时间复杂度,无法拓展到较大的数据集上。
利用共享相似度概念解决传统相似度在高维空间下的问题
传统相似度在高维空间内普遍较低,使得利用这种相似度进行指导可能导致各种问题。尤其是这种情况下,距离最近的对象可能并不属于同一类,这使得层次聚类算法这样选择最近邻进行合并的算法性能下降更为显著。
但是我们同样能发现,传统相似度下,取若干的个最近邻,这若干个最近邻中与目标对象属于同一类的占比显著高。基于这一点,我们认为,最近邻的集合的相似度越高,两个对象越可能属于同一类。我们将其相似度描述为共享最近邻相似度(Shared Nearest Neighbor, SNN),定义为两个对象的k-最近邻构成的集合中共享的对象个数。
SNN通过共享最近邻的个数考虑了对象所处的环境(这也可以看作一种反对全局静态簇定义的方式),因此能够处理变密度簇和高维度下的问题。
SNN密度
SNN密度由SNN描述,定义为该点以SNN计算的邻域内对象点的个数。其描述了一个点被类似的点包围的程度,因此一个处于高密度和低密度区的点具有较高的SNN密度,而处于高密度与低密度区域中间的点具有较低的SNN密度,由此SNN密度用于DBSCAN算法中能够按照密度变化情况进行聚类划分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号