Java-Web学习-Web基础-HTTP/TCP/IP
Java Web系列可能要停更一段时间了,原因是最近在做一个Django的项目
最近可能更新些Django笔记,敬请期待
网络协议基础
HTTP
HTTP属于应用层协议
HTTP事务工作流程
HTTP事务,是指请求命令 + 响应结果,是HTTP请求的最小单元。缺乏响应结果的不能看作一次完整的事务。
HTTP的流程步骤可以描述为:
- 域名解析
- 客户端发起HTTP请求
- 服务端响应HTTP请求得到HTML代码
- 浏览器解析并渲染HTML页面
注意HTTP中限制每次连接只处理一次请求,当服务器对客户端的请求作出响应后,马上断开连接。
报文
报文:报文是在HTTP应用程序间发送的数据块,其具有一定的格式。包括文本形式的元信息,以及可选的数据部分。
报文流:报文从客户端流出并流入服务器,随后流回客户端,形成了一次完整的HTTP事务。
HTTP报文由三个部分组成:
-
起始行(start line):在请求报文中说明需要做什么,响应报文中说明出现了什么情况
- 请求行:包含了一个方法和一个请求URL。方法描述了服务器应该执行的操作,请求URL描述了需要对哪个资源进行操作。请求行中还包含了HTTP版本,用于向服务器说明。所有字段使用空格分隔。
- 方法:GET、POST、HEAD、PUT、TRACE、DELETE等
- 小知识:根据规范,GET用于不改变服务器数据的请求。如果你逆天而行,那么很多插件很有可能会误会你的意思,导致某些预加载插件错误预加载了GET请求的链接,使得服务器的数据错误地改变。
- 方法:GET、POST、HEAD、PUT、TRACE、DELETE等
- 响应行:承载了状态信息和操作参数的所有结果数据。其包含HTTP版本、数字状态码、以及描述操作状态的文本形式的原因短语。
- 请求行:包含了一个方法和一个请求URL。方法描述了服务器应该执行的操作,请求URL描述了需要对哪个资源进行操作。请求行中还包含了HTTP版本,用于向服务器说明。所有字段使用空格分隔。
-
首部(header):包括多个键值对(称之为首部字段,每个字段独占一行,包含一个民名字和一个值,利用冒号相隔)。首部以一个空行结束。
- 首部类型:请求和响应报文分别拥有不同的首部字段,也有一些通用的字段同时存在于两者之中。还有实体字段,用于对主体中的数据进行说明。开发者还可以自定义一些新的首部,HTTP程序也需要对它们进行转发。
-
主体(entity-body):不同于起始行和首部,其采用二进制方式包含任意的数据
Cookie & Session
一个用户的所有操作都在一个会话上进行,跟踪会话是网络协议中重要的一环。Cookie和Session都是为了跟踪用户的整个会话的技术(因为HTTP协议中规定每次连接响应一次后自动断开,使得服务器无法跟踪用户的后续行为)。Cookie是在客户端记录信息,而Session是在服务端记录用户信息的。
Cookie形式上是一小段的文本信息,包含多个键值对字段。当客户端发送请求后,服务端会判断是否需要跟踪用户会话,如果需要的话会颁发一个Cookie给客户。当客户再次链接时会连带上次收到的Cookie,服务端会检查Cookie(是否过期?是否有效?各字段的值?),来识别用户的状态。
Cookie具有不可跨域性,所有浏览器都被要求根据域名携带Cookie,即使得访问cscore.net.cn只会携带cscore.net.cn之前颁发给客户的Cookie而不会携带www.baidu.com颁发的Cookie。因此如果需要实现跨域名,需要同时发送多个Cookie,每个Cookie的domain字段执行需要跨域名的多个不同域名。
Cookie一般具有有效期。maxAge这一字段说明了最长生命周期,当maxAge为正,将被接受到该Cookie的浏览器进行持久化,即保存为Cookie文件直到过期失效;当为负,将被设置为临时Cookie被保存在内存中,一旦浏览器关闭则失效;当为0,将视作即时失效,由浏览器来决定是否移除。
Session是客户端在第一次请求服务器的时候创建的,也是使用键值对来保存属性字段。Session是存放在服务端内存中的,因此信息尽量精简,只有当访问程序时才会建立Session,只访问静态的HTML或图片是不会建立的。
Session通过超时时间来表示有效期。每次用户访问服务端都会更新一次Session状态,使其活跃一次,当Session与上一次活跃之间的时间超过了一定限制,该Session就会自动失效。
Session需要依靠Cookie,因为单靠Session本身并不能判断访问者是具体哪个用户。通常用单独的一个名叫JSESSIONID的Cookie存放该用户的对应的Session ID,从而让服务端根据这个Cookie来识别具体用户。或者在不支持Cookie的浏览器上使用URL地址重填,即让用户在请求时将自己的Session ID重写到URL信息中,由此服务器通过解析用户发来的URL请求来找到具体的Session。
Java Web规范中支持使用配置的方法禁用Cookie。事实上我们也推荐索性禁止Cookie,因为很多浏览器不支持Cookie。
从HTTP到HTTPS
基于HTTP协议,通过SSL或TLS提供加密处理数据、验证身份、数据完整性保护。HTTPS具有以下特点:
-
内容加密:混合加密
-
身份验证:证书认证
-
数据完整性检测:防止数据被篡改和冒充
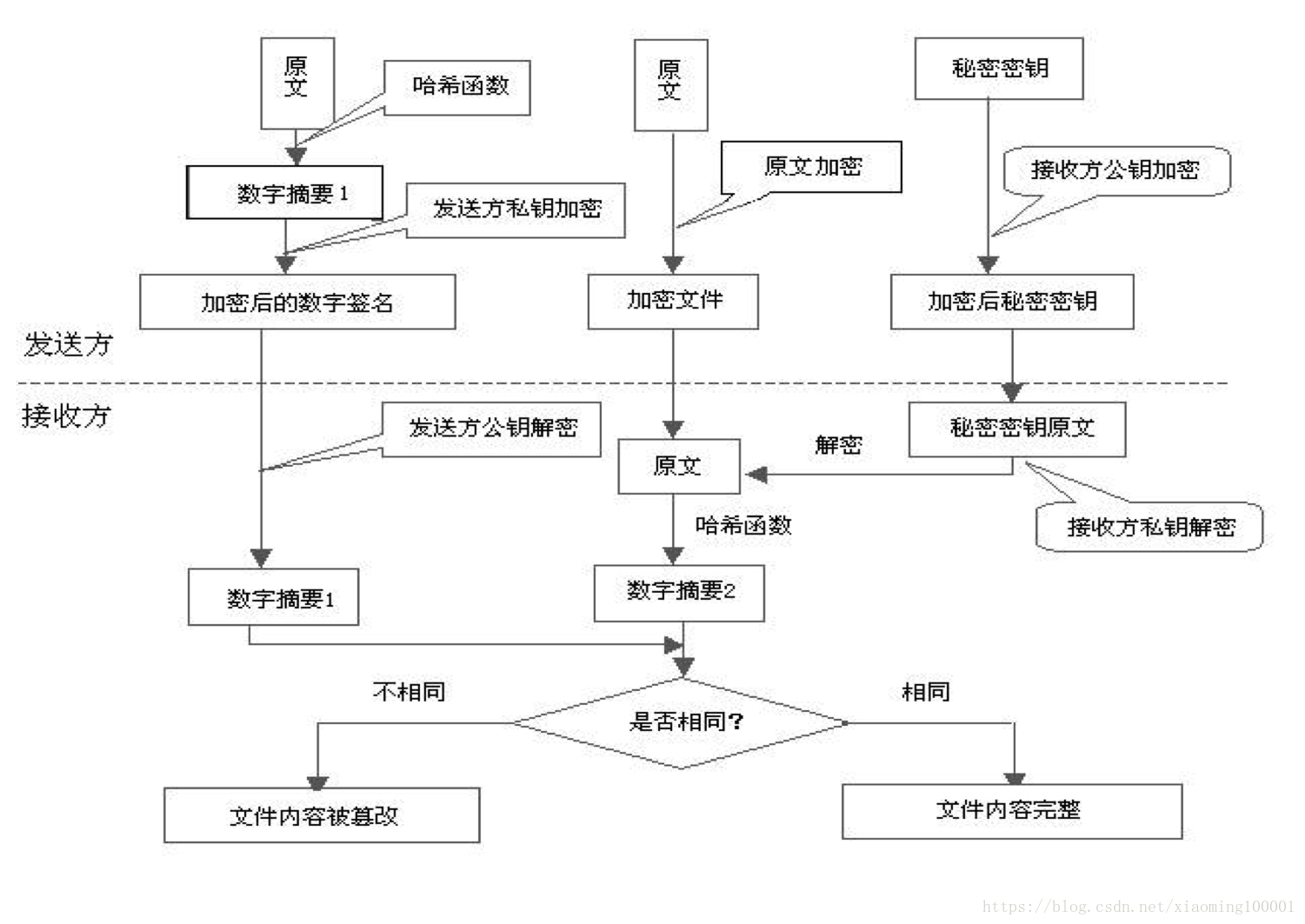
-
对称加密:加密和解密使用同一密钥。
-
非对称加密:需要两个密钥,私有密钥和公有密钥。用公有密钥加密的数据需要私有密钥来解密,而私有密钥加密的数据需要公有密钥解密。
-
数字摘要:通过hash函数对原文进行处理生成固定长度的密文。原文任何信息的改变都会大幅改变对应的密文,保证了同样的数据的密文必然一致。
-
数字签名:建立在非对称加密机制上,结合数字摘要技术形成的实用数据签名技术。数据前面实际上就是数据摘要经过私钥加密后的数据。
-
数字证书:为了判断公钥是否安全,对公钥进行认证。即要求第三方Certificate Authority使用其认证中心自己的私钥,将需要认证的公钥和相关信息进行加密,生成数字证书。在传输公钥的过程中附加数字证书,任何人都可以使用认证中心的公钥对证书进行解密,以判断当前传输的公钥是否是正确的公钥。通常在涉及公钥传输时都会附带数字证书。
-
HTTPS集合了非对称加密和对称加密技术,客户端使用对称加密生成密钥对数据进行加密,然后使用非对称加密的公钥对密钥本身进行加密。网络上传输的是被密钥加密的密文和公钥加密后的秘密密钥。由于黑客无法获取到私钥,因此数据是安全的。并且依靠数字签名和数字证书保证公钥和数据的正确性。
TCP
TCP属于传输层协议
建立连接——三次握手
- 客户端发送请求报文SYN
- 服务端接收到请求后,发送ACK报文确认收到连接,并分配资源和发送SYN报文
- 客户端接收到确认后,发送ACK报文确认建立连接,并分配资源和发送SYN报文
断开连接——四次挥手
若客户端发起中断连接请求
- 客户端发送FIN,关闭传输
- 服务端接收到FIN,发送ACK确认,此时客户端接收到FIN,但不发送任何信息
- 服务端发送FIN,关闭传输
- 客户端接收FIN,发送ACK确认,客户端在等待一定时间后结束当前连接周期
可以看出,由于服务端在接收到FIN时不一定结束了所有报文的发送,因此需要分为两次挥手:第一次发送ACK声明已经接收到客户端关闭的通知,第二次是等到所有报文发送完毕后发送FIN正式关闭传输。
IP
IP属于网络层协议,是TCP/IP协议族的动力,为上层协议提供无状态、无连接、不可靠的服务。可以说,IP协议是一个非常简陋的架构,同时也暗藏了无限潜力,我们可以在上面实现多种机制以提升其能力。
IP地址
IP地址根据版本分为IPv4和IPv6
IPv4有十进制和二进制两种表示方法,采用点分四组十进制时,每组范围为0到255,比如120.7.56.1
IPv6采用冒号分8组4位十六进制,前导零可忽略,IPv6的低32位字长采用点分四组的形式表示,使其同时可兼容IPv4(表示方式为块值为ffff,后紧跟点分四组格式,比如::ffff:123.123.123.123)。
IP地址可看做两部分:网络地址和主机地址,网络地址相当于某个网络系统的编号,主机地址则对应相同网络中的主机编号。相同网络地址内的两台主机才能相互通信,否则需要经过路由器。
以IPv4地址为例,分为四种:
- A类:左边第一位二进制位为0,使用第一个字段中剩余7位表示网络地址,第一个字段内数值从1到126
- B类:左边前两位二进制位为10,使用第一个字段和第二个字段表示网络地址,第一个字段内数值从128到191
- C类:左边前三位二进制位为110,使用前三个字段表示网络地址,第一个字段内数值从192到223
- D类:左边前四位二进制位为1110,表示剩下的所有IP地址,即224.0.0.0到239.255.255.255
CIDR前缀方案:CIDR是独立于上述4类存在的,采用前缀方式来指定用前多少位来表示网络号,比如223.70.23.123/13,就是指用前13位作为网络号。
子网
IP地址可以按字段进一步分为三级:网络号、子网ID、主机ID。子网ID占用了主机ID的几个位从而将网络划分为若干个子网,便于管理和减少IP浪费。
IP地址的前几位可以来判断其属于那种类型,进而判断网络号有几位。但是由于各个公司所拥有的主机数不同,子网ID占用的具体位数也不同,子网掩码就是为了说明哪些位用于网络号和子网ID,哪些是用于主机ID。
注意,IP协议规定每个子网的第一个地址和最后一个地址无效,其并不指向真实的主机。因为第一个地址不是主机地址而是“子网标识符”;最后一个地址特指当前子网下所有主机,这是为了广播机制所预留的。
子网广播:通过向某个子网中主机号为最后一个的主机发送报文,实际上指的是向子网内所有主机发送报文。
IP数据报
IP数据报是IP协议下控制传输的单元,目前广泛采用的是IPv4数据报规范。
IPv4数据报分为两个部分:首部和有效净荷(负载数据)。数据报的几乎所有相关信息都存在首部,有效净荷大小可变。
IPv4首部在无拓展字段的情况下共5个32位字。
| 字段 | 长度(bit) | 含义 |
|---|---|---|
| 版本号 | 4 | IP协议的版本号,分别为4和6 |
| 首部长度 | 4 | 指明首部的长度,以byte为单位 |
| 区分服务(TOS) | 8 | 规定本数据报的处理方式,包括优先级、延时、吞吐、可靠性等 |
| 总长度 | 16 | 首部加上有效净荷的总大小 |
| 标识 | 16 | IPv4维护的一个计数器,该字段会随着数据报的产生而递增 |
| 标志 | 3 | 最低一位为1,表示后面还有分片的数据报;中间1位为1,表示当前数据报不是分片的 |
| 片位移 | 13 | 当分组被分片后,当前数据报在原分组中的相对位置 |
| 生存时间(TTL) | 8 | 实际上指的是该数据报被传递时的跳转限制,超出后就会给发送者返回一个ICMP消息表示发送失败 |
| 协议 | 8 | 指出当前数据报携带的数据遵从的是什么协议 |
| 首部检验和 | 16 | 用于保护数据报首部数据完整性,每经过一个设备就会被重新计算和校验,只计算首部! |
| 源地址 | 32 | 报文发送方的IPv4地址 |
| 目标地址 | 32 | 报文接收方的IPv4地址 |
| 选项字段 | <40 | 拓展IPv4首部的功能,自定义 |
| 有效净荷 | var | 承载二进制报文信息 |
IP路由
IP协议的一个重要任务就是数据报的路由工作,即寻找发送到目标的路径。以下列出了一个IP实体对于IP数据报的处理流程。
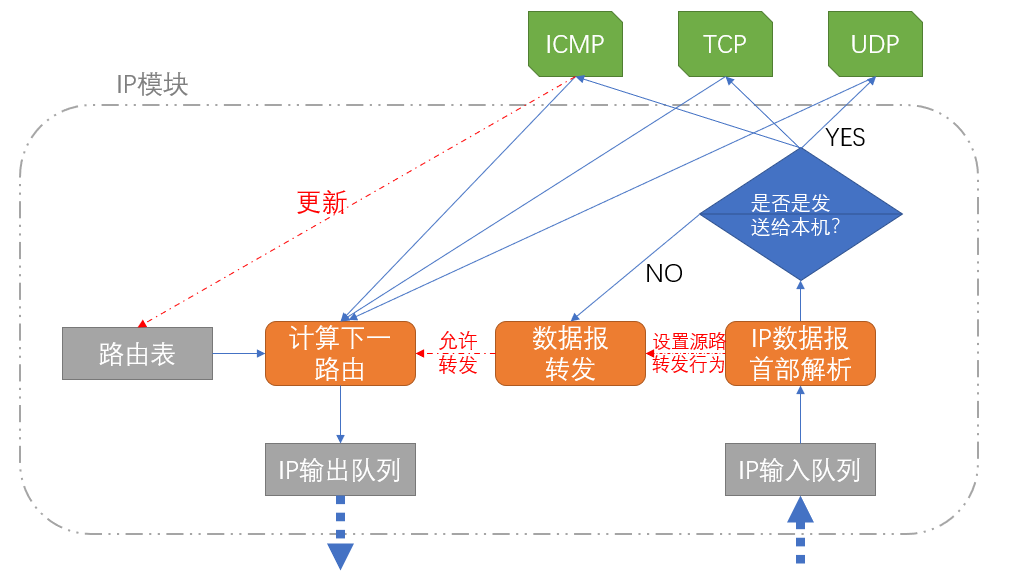
源路转发:分为严格源路由和松散源路由,严格源路由需要发送方给出所有的节点列表;松散下则只需要给出部分关键节点,路由路径只要途径这些节点即可。
ICMP重定向:一个ICMP重定向报文将告诉当前的IP实体,引发重定向的数据报信息以及应该使用的路由器的IP地址。于是当前IP实体就能以此更新路由表。通常在不改变内核参数的情况下,只有路由能发送ICMP报文,只有主机能够接受ICMP报文。
已知IP数据报的目标IP地址,它将匹配路由表中的哪一项呢?这就是IP的路由机制,分为3个步骤:
- 查找路由表中的数据报的目标IP地址完全匹配的主机IP地址。如果找到,就是用该路由项,没找到则转步骤2。
- 查找路由表中的数据报目标IP地址具有相同网络ID的网络IP地址。如果找到,就使用该路由项;没找到则转步骤3。
- 选择默认路由项,这通常意味着数据报的下一跳路由是网关。
网关 Gateway:网关有着很多的定义。在TCP/IP协议下,网关指一个网络通往其他网络的IP地址。当IP实体发现数据包无法在当前网络中转发,那么就会发送给网关,转到其他网络中。
IP转发
IP协议下,主机和路由器都能进行转发,但是主机不会转发不由自己生成的数据报(由内核参数决定)。每次转发,数据报中的生存时间TTL减一。对于允许IP数据报转发的系统,数据报转发子模块将对期望转发的数据报执行如下操作:
- 检查数据报头部的TTL值。如果TTL值已是0,则丢弃该数据报。
- 查看数据报头部的严格源路由选择选项。如果该选项被设置,则检查数据报的目标IP地址是否是本机的某个IP地址。如果不是,则发送一个ICMP源站选路失败报文给发送端。
- 如果有必要,则给源端发送一个ICMP重定向报文,以告诉它一个更合理的下一跳路由器。
- 将TTL值减1
- 处理IP头部选项。
- 如果有必要,则执行IP分片操作。
IP分片
IP分片的根本在于数据链路层的约束。在TCP/IP协议族中,采用MTU来限制一次传输的数据包的大小,当一个IP数据报的大小超出MTU的限制,就必须进行分片。IP是没有超时重传的,因此一个分片的丢失就需要整个分组重新进行传输,我们应尽量避免分片。
MTU是根据不同接口要求而变化的。IPv4下,当路由器接受到一个数据包时,会考察下一次跳转地址的接口,如果MTU进一步缩小,则会进行二次分片。接收机收到所有的片段后能够通过其IP数据报首部的字段按一定顺序重组信息。
参考目录:
[1] IP协议详解 - Red_Code - 博客园 (cnblogs.com)
[2] HTTP/TCP协议基础 - 小嘉欣 - 博客园 (cnblogs.com)
[2] IP协议详解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号