
第三天 Java中的集合-Map
一: 我们都知道在java中,集合实现类很多 ,其中最底层的接口有两个 1:Collection 2:Map
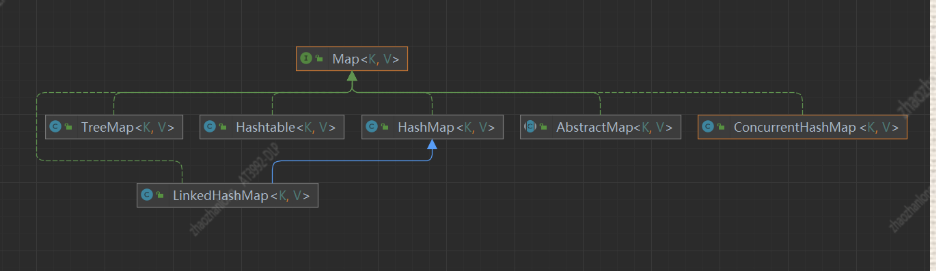
Map:我们通过一幅图来看一下 Map的主要实现类
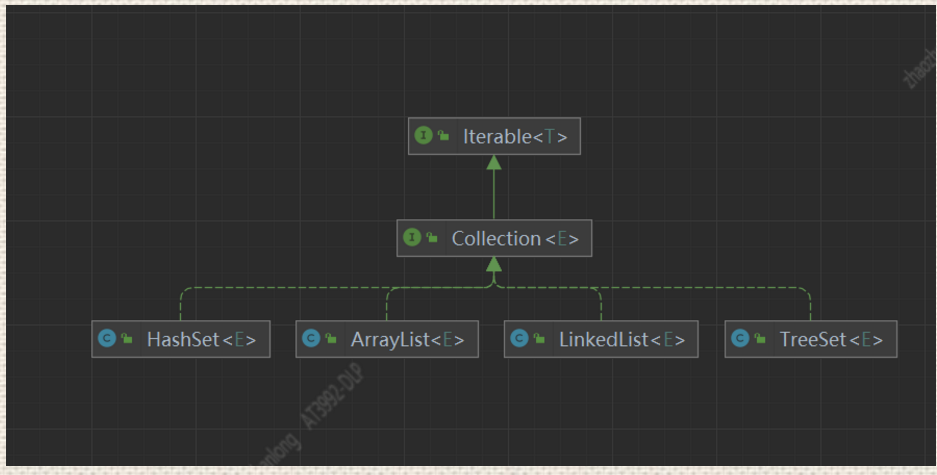
Collection :接口主要的实现类
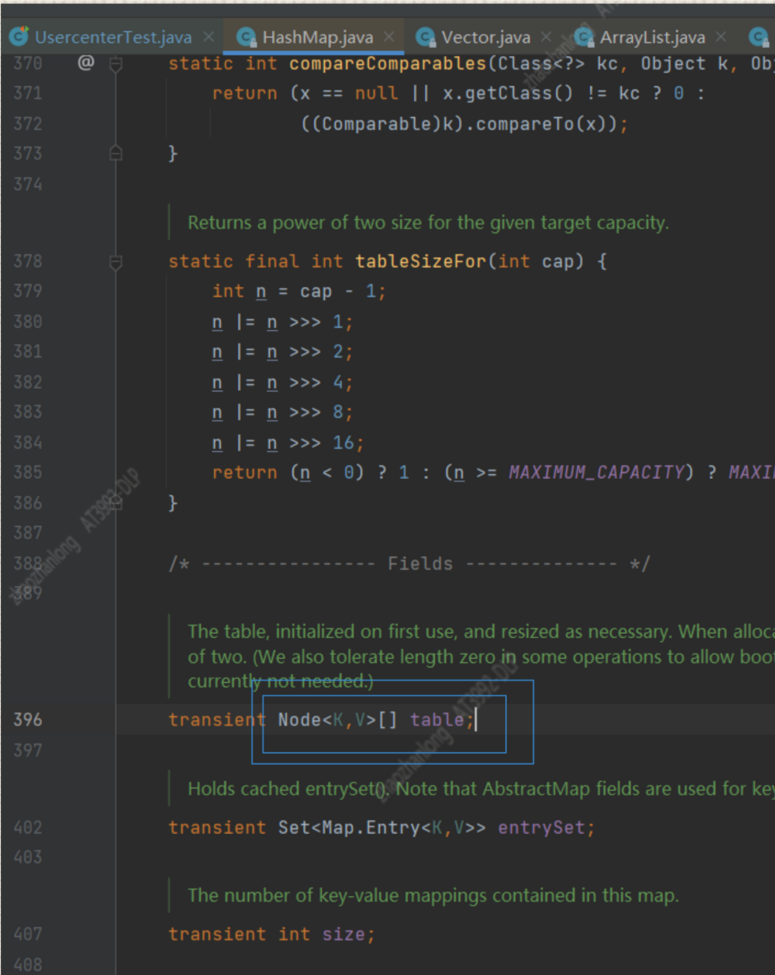
HashMap源码分析
下面我们来看一下 HashMap到底是一个什么
在HashMap源代码中我们可以看到 HashMap的本质就是一个transient Node<K,V>[] table;
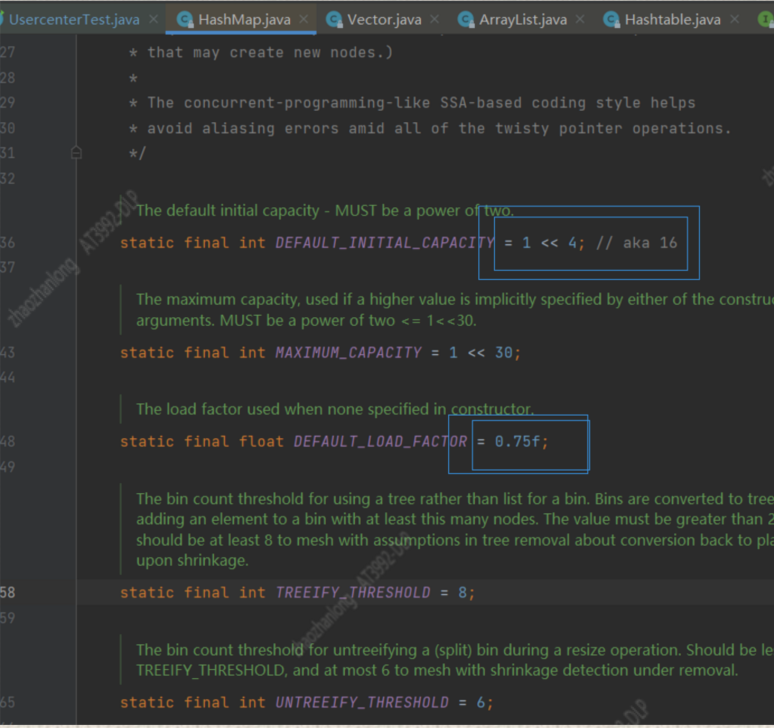
其中数组默认大小是16 ,扩容阈值是0.75
下面我们再来看一下 NodeM<K,V>是一个什么
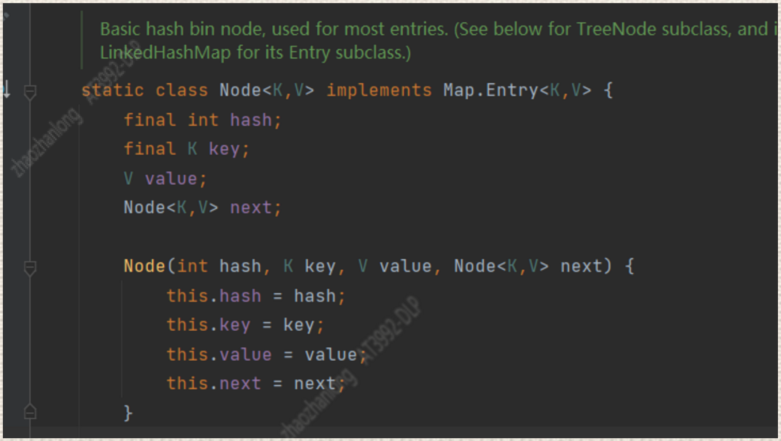
我们可以看到Node其实就是一个链表,单向的链表,所以说HashMap的本质就是一个链表的数组大致的存储结构就是这样的
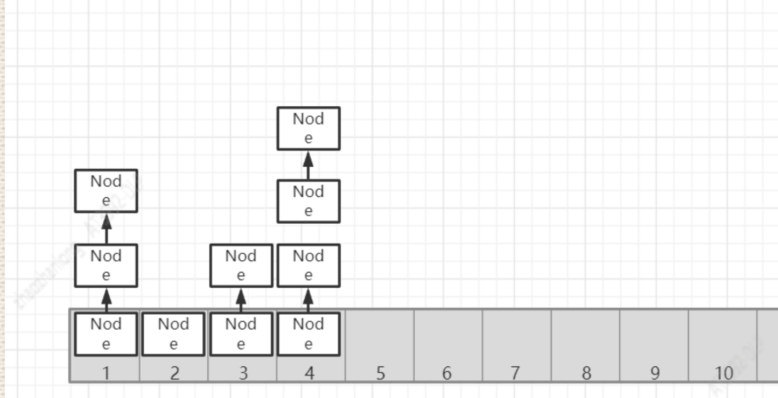
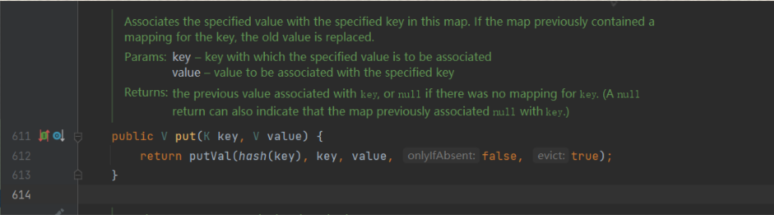
下面我们来看一下他的源码实现,主要是来看Put方法
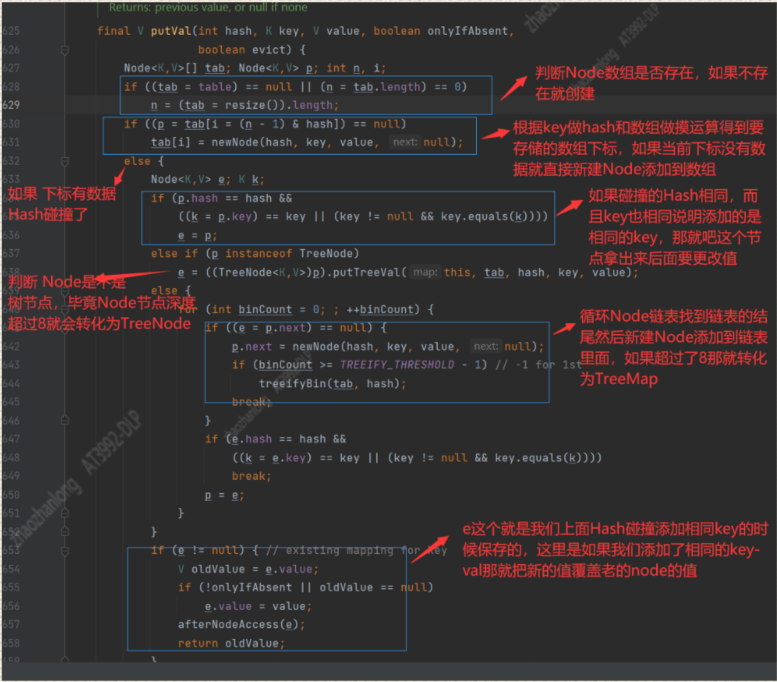
下面我们来主要分析一下 PutVal都做了什么
注意这里:我们可以看到在循环链表的时候 没有判断key和链表每个节点key做比对,而是直接找到链表最后添加了 ,所以这里理论上有有一个bug,
比如我们链表有一个key=“zzl” val=1的节点了 现在我们在添加一个key=“zzl” val=3的节点,因为没有做key的hash比对,
所以我们后添加的节点不会覆盖前面那个key="zzl" 的节点,这样在我们get取值的时候 就会值取到第一个key=“zzl” val=1后面添加的那个取不到
我们来看看 我们在HashMap中添加一个key-val都做了什么
第一步:我们先判断Node数组是不是存在【前面我们说了HashMap本质就是Node数组】,如果不存在就创建使用resize()【resize()这个方法不但是创建,扩容也归他管】
第二步:根据我们的Key做Hash然后在和数组长度取模,拿到要把这个key保存到数组的那个下标,然后查询这个下标是否有数据,如果没有数据,就新建Node然后
保存到拿到的那个下标
第三步:如果拿到的下标有数据【发生了hash碰撞】
第四步:判断key的hash值是否相同,key是否也相同,如果这两个值完全相同,说明我们添加了相同的key,那么就把这个node拿出来【我们后面处理】
第五步:判断Node节点是不是treeNode节点,因为我们在hash碰撞的时候 如果链表深度超过了8,就会转化为树
第六步:如果不是树,而且hash值相同,但是key不同,说明只是hash碰撞,但是不是同一个key,这个时候我们循环node链表,找到最后的节点,然后新建一个node节点
并且把这个节点插入到链表的尾部,但是如果链表深度超过了8,就吧链表转化成树treemap【HashMap链表到树的转化就在这里】
第七步:如果我们添加的key的hash相同,key也相同,上面第四步的判断在第四步我们拿到了那个节点,这个时候我们就把节点的值val覆盖为我们新的值,
第八步:if (++size > threshold) resize(); 判断数组的容量是否需要扩容。
这就是我们HashMap的本质操作,下面我们来看一下 resize();的功能
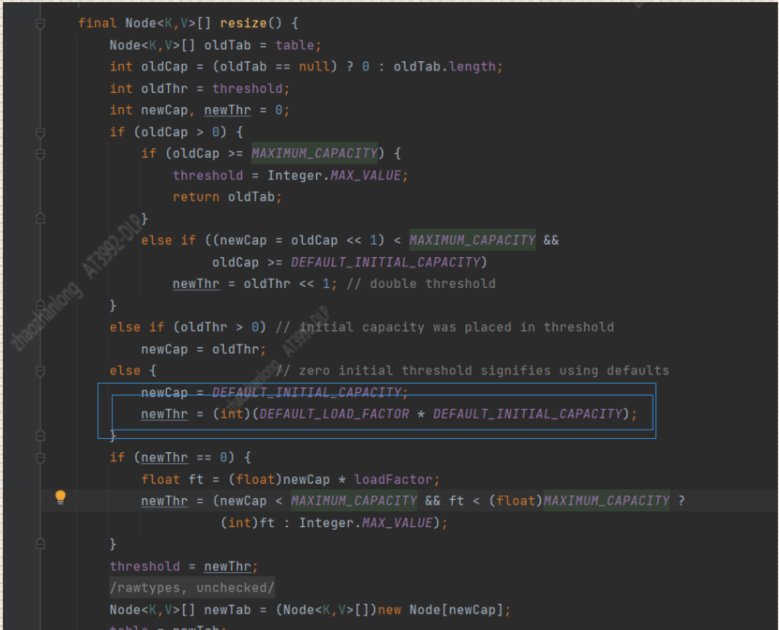
从这个 resize()中我们能看到,数据的扩容界限就是我们画主的哪一点 16*0.75 扩容是一倍,而且我们发现这个扩容resize()和添加put都是无锁操作
所以也说明HashMap不是线程安全的,在扩容的时候可能操作问题
HashTable源码分析
上面我们看到HashMap下面我们来看看HashTable本质是一个什么
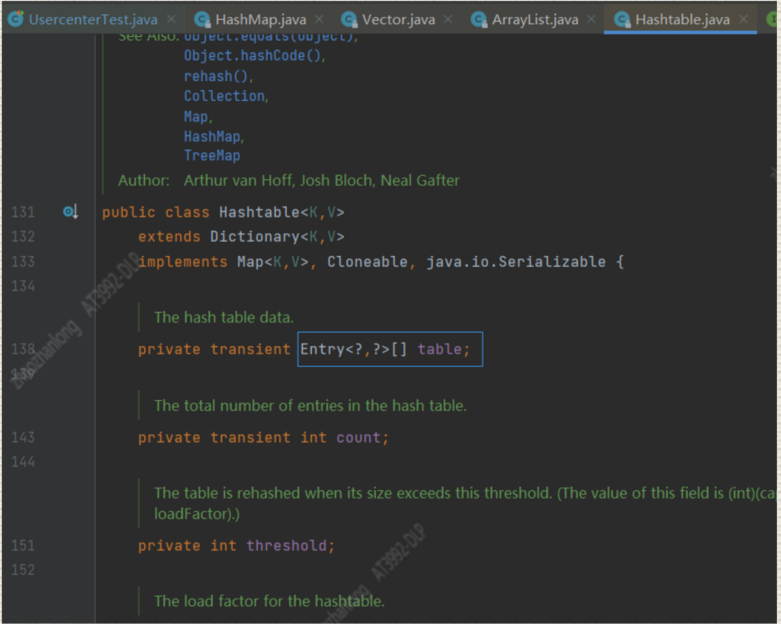
我们可以看到 HashTable本质是一个Entry数据,那么Entry又是一个什么那
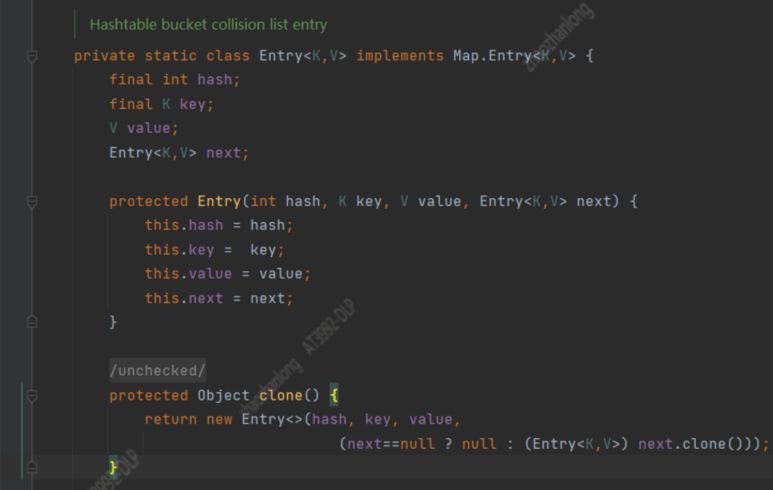
我们看到也是一个内部实现的链表,而且 这个链表和HashMap一样
在HashMap中 static class Node<K,V> implements Map.Entry<K,V>
在HashTable中private static class Entry<K,V> implements Map.Entry<K,V>
我们可以看到其实hashMap中的Node和HashTable中的Entry本质就是一个东西,就是在不同的类中的名称不一样【有可能不是一个人写的命名不同,或者是作者随意命名的】
既然他们本质一样那么我们也要看一下的容量默认值和扩容阈值

默认容量是11,扩容阈值是0.75
下面我们来看一下 HashTable的put方法
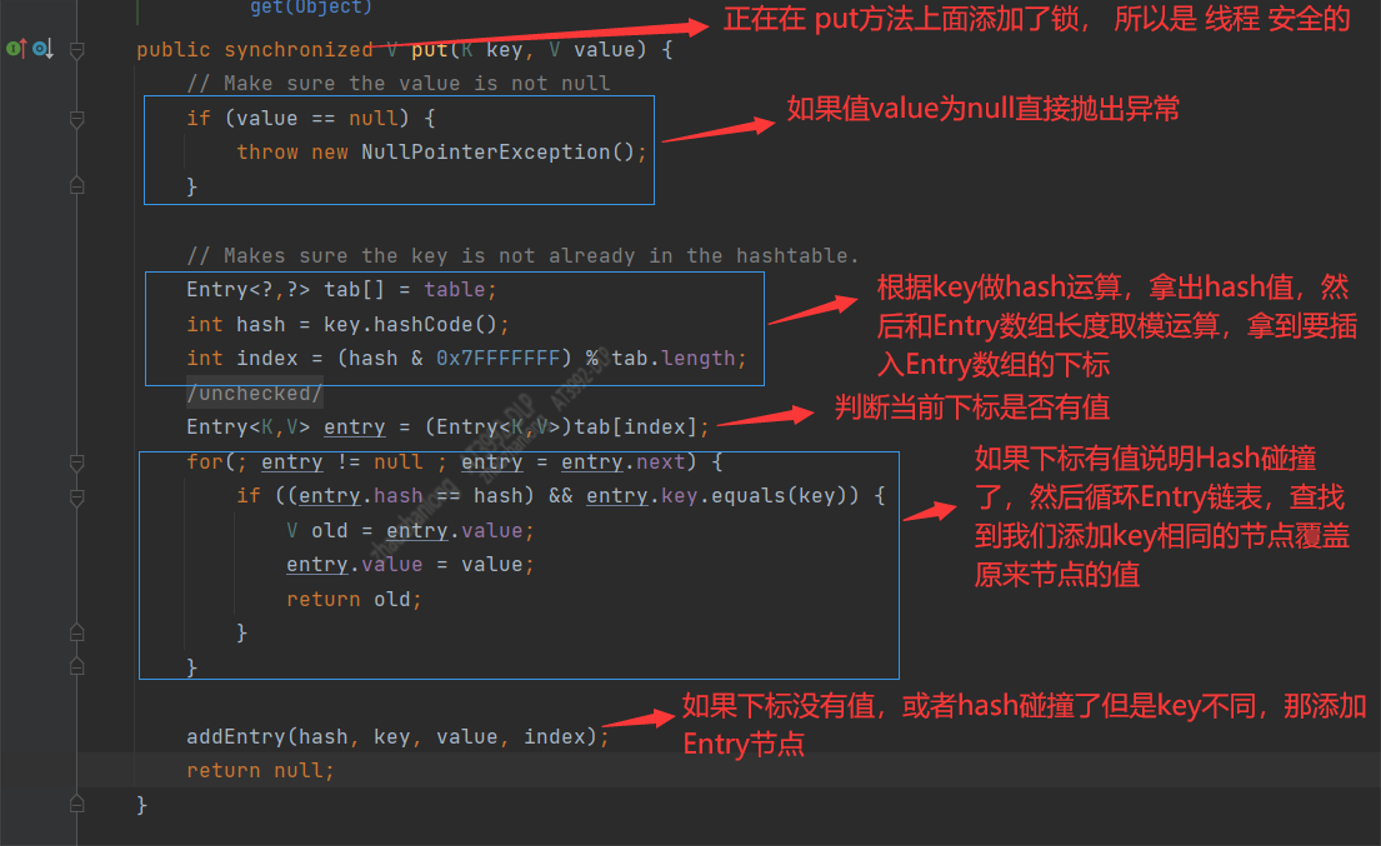
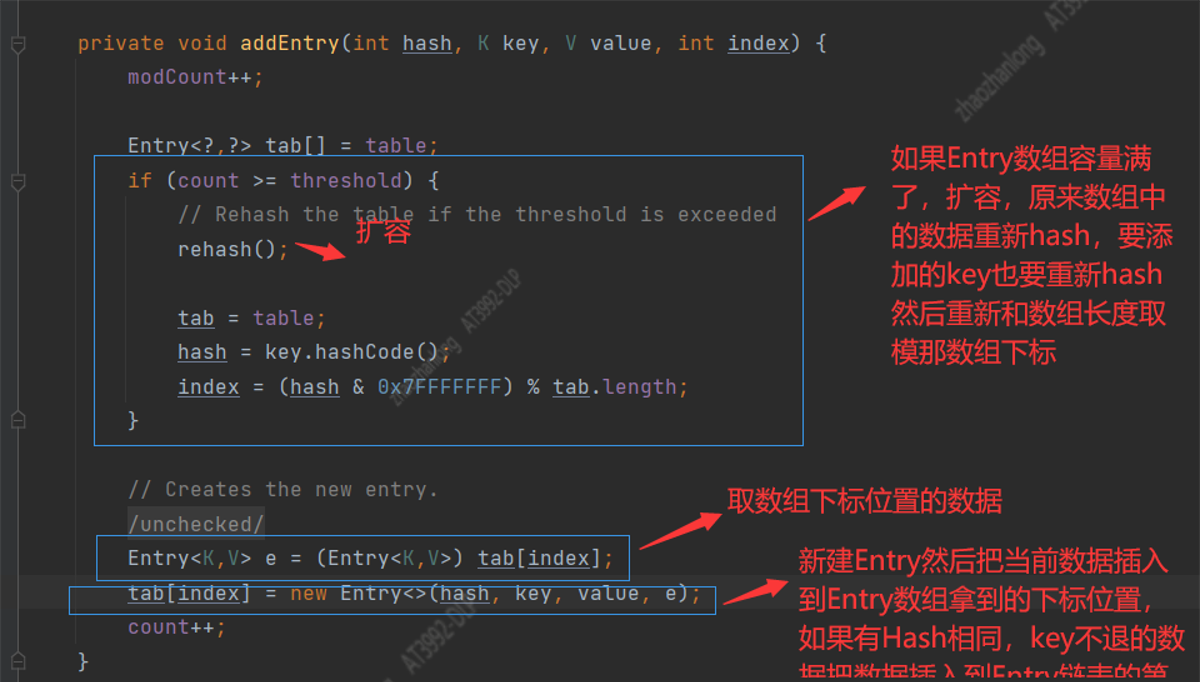
我们现在来分析一下 HashTable的put操作
第一步:我们看到put操作在整个方法上面添加了synchronized,这就说明HashTable是线程安全的【HashTable是非线程安全的】
第二部:判断值是否为空,如果为空就抛出异常【HashMap里面没有判断值是否为空】
第三步:根据key做hash运算然后和数组长度取模运算,拿到数组下标
第四步:获取当前下标的值
第五步:循环当前下标取出的Entry链表,判断有没有和当前要插入的key相同,而且key的hash也相同的节点,如果有就覆盖原来的值【说明我们添加了重复的key】
第六步:如果不满足上面的条件,那就执行添加节点addEntry(hash, key, value, index);
第七步:添加节点前判断Entry是否需要扩容,如果扩容了,需要对key重新做hash运算,重新和数组长度取模获取数组下标
第八步:根据数组下标拿到数组的数据
第九步:新创建Entry节点添加到数组下标位置,以新创建的Entry节点为链表开始节点吧原来的链表数据放入到新节点中【HashMap添加Niode链表是添加到链表尾部,HashTable添加Entry链表节点是添加到链表头部】
ConcurrentHashMap
ConcurrentHashMap和HashMap底层一样,保存数据都是Node数组,容量和扩容阈值也都一样
但是ConcurrentHashMap的Node数组是volatile的
但是ConcurrentHashMap是线程安全的
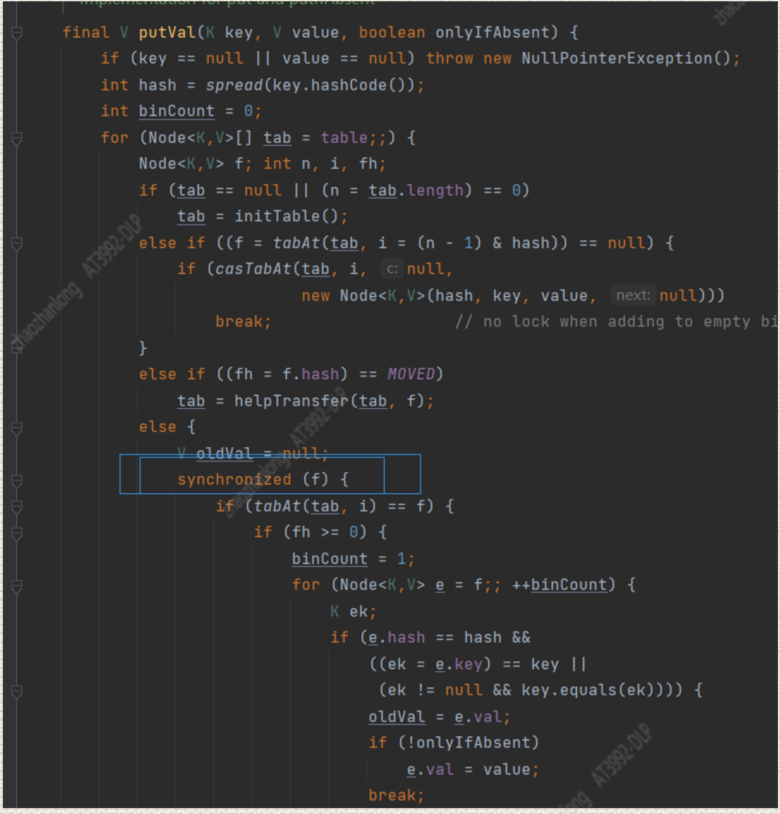
我们可以看到在 1.8中ConcurrentHashMap已经没有分段锁了 ,ConcurrentHashMap中put的实现是通过cas+synchronized来实现的
如果要插入的 key没有在Node数组中存在 ,那就使用cas插入,
如果出现了hash冲突那就用synchronized操作
并且ConcurrentHashMap的put判断了key和val是否为空,如果为空抛异常
TreeMap
TreeMap的本质是什么那,我们可以看一下 TreeMap存储本质是Entry<K,V> root;
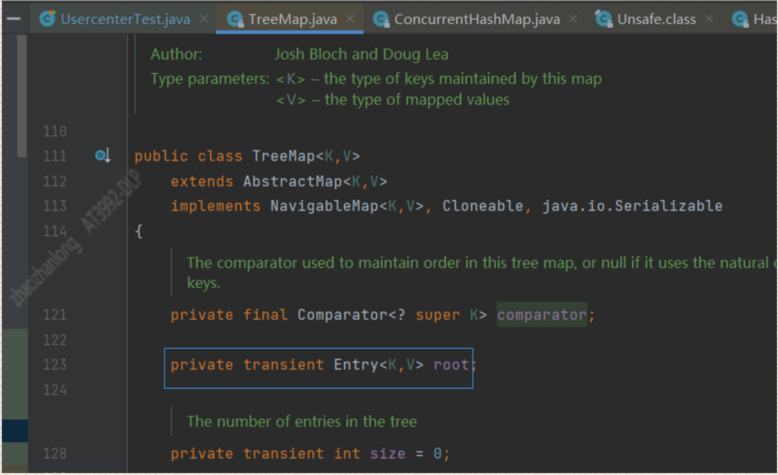
我们再来看看 在TreeMap中的Entry是什么
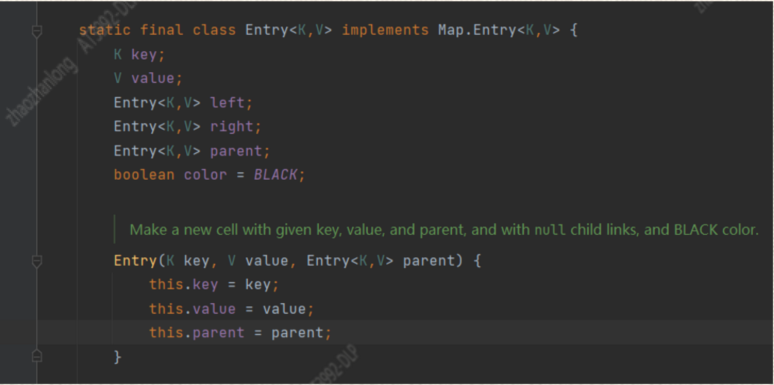
我们通过源码可以看到Entry是一个 树的链表【HashMap和HashTable和ConcurrentHashMap都是数组+单向链表】
我们来看一下 TreeMap的Put是怎么操作的
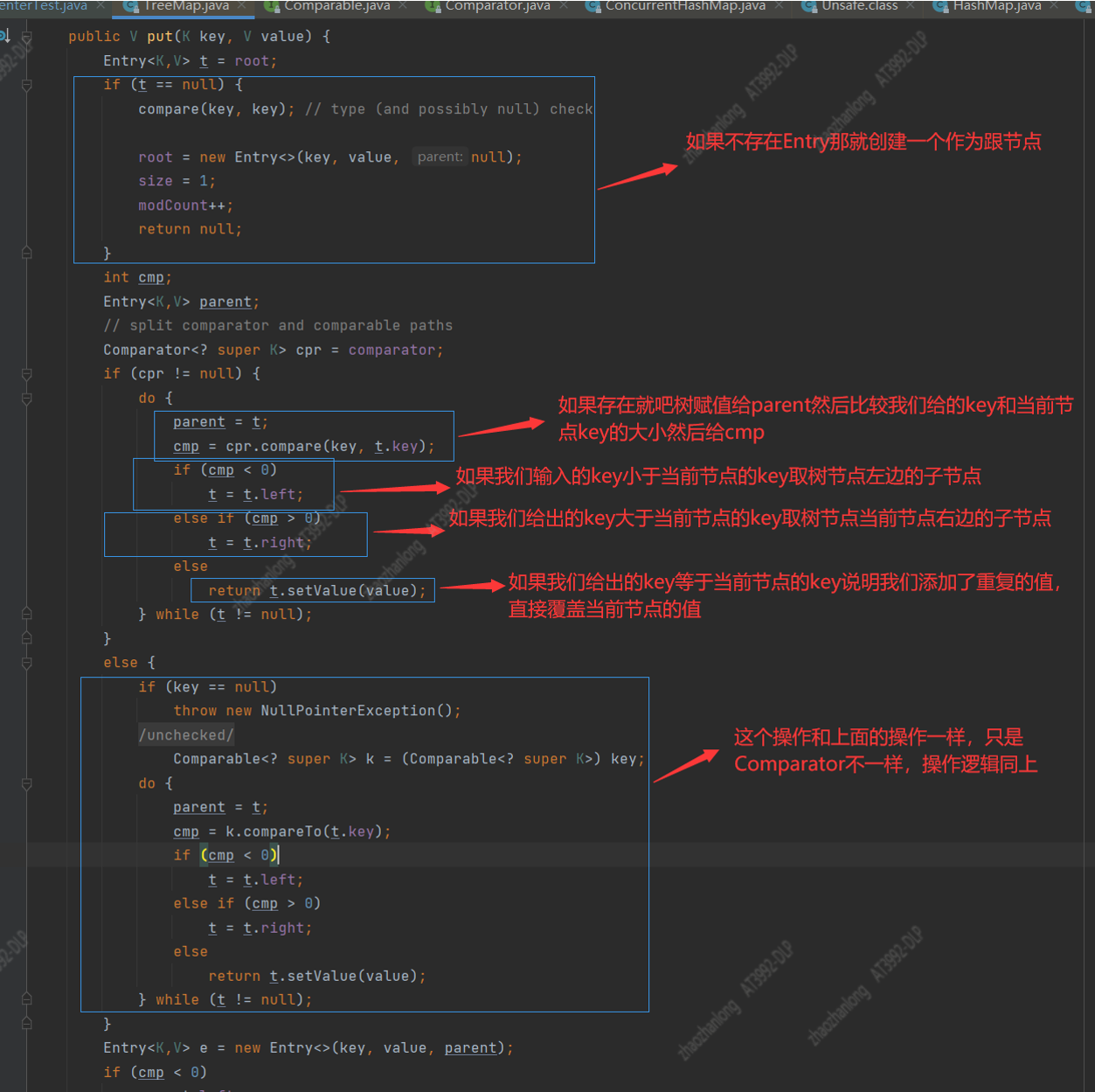
第一步:判断是否有根节点,如果没有根节点就根据key和val创建一个根节点然后返回
第二步:Comparator<? super K> cpr = comparator;判断比较器是否存在,其实分支里面的操作是一样的,我们下面值说一个分支
第三步:根据跟节点循环树,然后判断当前节点的key和我们要保存的key的大小
第四步:如果我们输入的key小于当前节点的key,那么取当前节点左边的子节点赋值给t用作下一次循环
第五步:如果我们输入的key大于当前节点的key,那么取当前节点右边子节点赋值给t作用下一次循环
第六步:如果我们输入的key等于当前节点说明我们的key重复了,直接用我们输入的值val覆盖当前节点的值
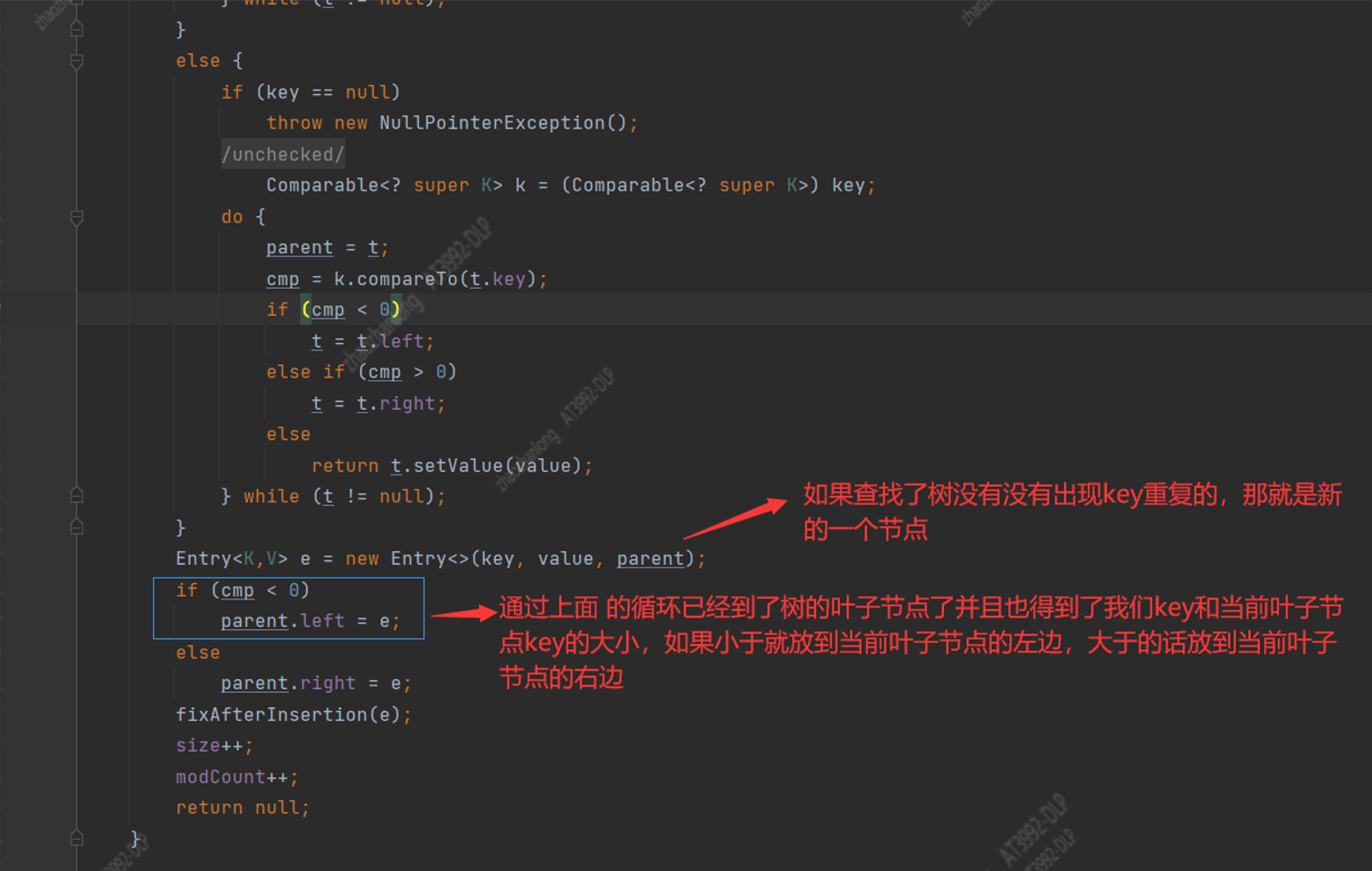
第七步:如果循环到了树的叶子节点还是没有key重复,说明我们添加的是一个新的值,然后重建一个Entry节点
第八步:根据上面循环最后判断的key和叶子节点key的大小来确认当前新创建的节点要插入到叶子节点的左边还是右边,如果输入key大于当前节点key就把新的Entry放到当前叶子节点的右边如果小于就放到左边
注意:TreeMap做个操作是没有锁的,所以不是线程安全的
LinkendHashMap
我们先来看一下 linkendHashMap的定义
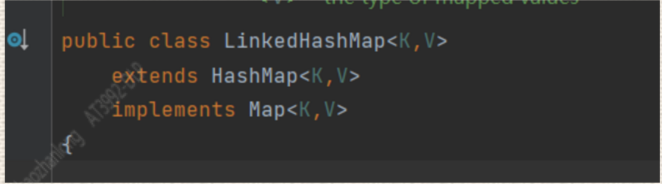
我们可以看到LinkendHashMap继承了HashMap类,只是重写了一些HashMap的方法
比如在LinkendHashMap中数据的存在变成了这样
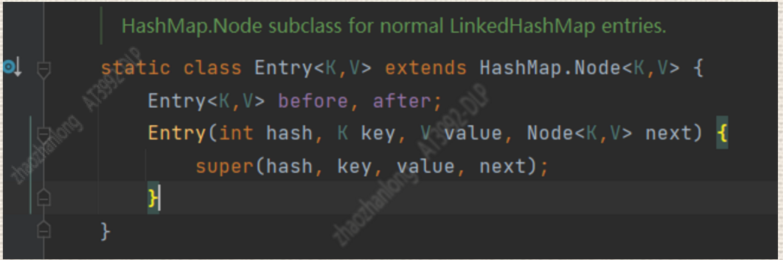
LinkendHashMap底层数据是“链表+HashMap
其中我们前面讲过了HashMap的底层数据结果和Put操作明白原理,那么LinkendHashMap就简单多了,他就是在HashMap上面添加了一个双向链表
为什么要这么做那 :我们前面讲解的时候知道HashMap在Put的时候是对Key做了hash操作然后在取模,所以数据插入数组的那个地方,我们是不知道的 ,也就是说后插入的数据可能在前面, 这个时候我们如果想按照顺序怎么来,HashMap就做不到了,所有有了LinkendHashMap,他每次插入会做一下链表,这样我们就知道插入的顺序了
大致数据存储就是这样的 ,实线部分还是原来HashMap,虚线部分就是LinkendHashMap的双向链表了
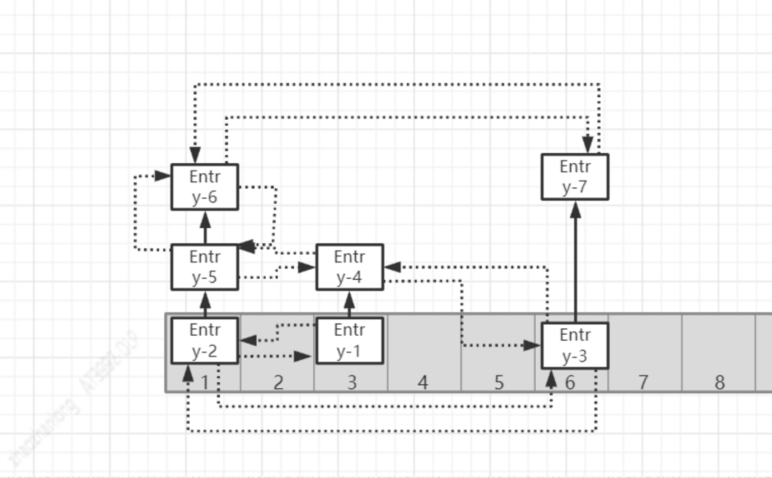
总结:
HashMap:底层是数组+链表而且不是线程安全的,当我们插入key出现hash冲突的时候会添加到链表中添加位置是链表的尾部,如果链表深度达到了8会把链表变成树
HashTable :底层是数组+链表是线程安全的使用synchronized来直接锁put,所以hashTable效率不会很高至少没有HashMap高,hashTable无论链表多深都不会转化成树
而且在发生key的hash冲突时吧数据添加到链表是添加到链表的头位置【HashMap是添加到尾部】,并且HashTable的值val不能为null+。
ConcurrentHashMap :这个底层也是数组+链表是线程安全的,而且实现和hashMap一样,但是为了实现线程安全他的底层存储是volatile的,而且 1.8里面是使用cas+synchronized来实 现的的线程安全放弃了以前的分段锁,如果是新节点新数据没有key的hash冲突那就使用cas插入,如果出现了hash冲突就使用synchronized来插入,ConcurrentHashMap 的key和val都不能为空
TreeMap :这个是树不是线程安全的,树的特征节点左边的子节点比节点小,节点右边的子节点比节点大,所有添加数据从根节点添加,遍历到叶子节点,如果中途有key相同的就覆盖 节点的值没有的话就添加到叶子节点,TreeMap 的key不能为null
LinkendHashMap :这个底层是双向链表+HashMap不是线程安全的,而且是继承了HashMap类,只是重写了一些HashMap方法,主要是为了实现使我们插入数据顺序有序,因为 HashMap我们插入数据是对key做hash运算然后和数组取模所以我们不能确定我们插入的数据就在我们要的位置,但是LinkendHashMap 在HashMap的基础上添加了双向链表来实现我们数据的顺序

 浙公网安备 33010602011771号
浙公网安备 33010602011771号