
第一天 MySql数据库总结
一:Group by 语句转化理解
我们知道在我们写Sql语句的时候,我们如果使用了Group by分组之后那么我们只能查询分组字段的数据,不能直接查询其他列,如果要查询只能使用“聚合函数”,为什么会这样,
下面我们来看一下 ,Group by具体怎么操作的
比如我们有一个表:
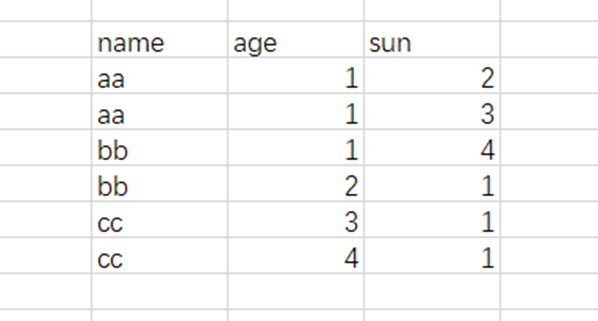
在我们执行select naem from xxx group by name 之后会发生什么 , 结果很简单只有一列,内容也只有 aa,bb,cc,但是为什么会出现这种结果下面我们来分解转化一下
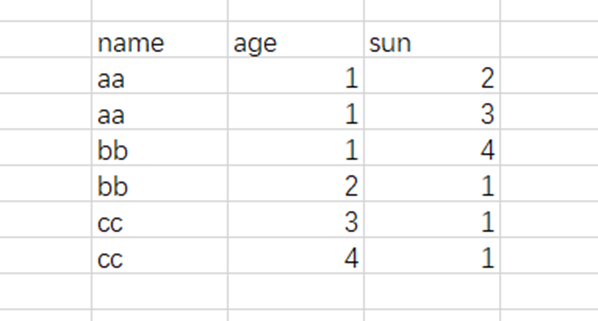
其实分组后数据变成了我们后面那个样子,深色部分是我们分组的字段,这一列是Group by之后我们能看到的数据,但是 age和sum这两列数据因为没有做分组所以我们在转化表里面是看不到的【或者理解为 数据存在但是他是在,但是age和sum 一个单元格包含了多行数据,有点类似我们的table套table】,这个是有我们使用select 要是来查找age和sum,因为 这两列在生成的临时表看不见 【或者理解为,age和sum包含了多行,不知道输出哪一行】,所以我们的Sql会报错【数据库处理机制不一样,也可能输出第一行,但是 sqlservice和mysql是报错】,但是聚合函数就不一样了,聚合函数本来做的就是就是输入多行数据返回一行,如果我们这 Select name,sum(age),count(sun) from xxx group by 这样就不会报错,
因为 聚合吧分组后没有分组的列,多行聚合城了一行,这样表就可以看到了【或者是没有分组的多行聚合成了一行,select 列没有组只有一行了,所以我们在输出就不会报错,可以输出了】
所以这样是为什么 Group by 的时候 如果要输出没有分组列要使用聚合语句的原因
二:Sql 语句执行顺序
例如我们有如下这个Sql
select DISTINCT a.userid from users as a LEFT JOIN member as b on a.UserId=b.UserId where a.userid=176194156 Group by a.UserId order by a.UserId desc LIMIT 1
第一步:from 首先对子句中的两个表 做一个笛卡尔乘积生成虚表v1(选着相对小的表做基础表)
第二步:On 做条件筛选,将上面表v1中满足条件的数据拿出来生成虚拟表v2
第三步:where执行条件筛选,找到所有符合条件的数据,生成虚拟表v3
第四步:Group by 对需要的分组的字段分组,生成虚拟表值v4【注意上面我们说的Group by分组原理】
第五步:Select 将虚拟表v4中我们想要的字段帅选出来【如果有Group by,要输出未分组列所有聚合函数】生成虚拟表v5
第六步:distinct把v5表中重复的数据删除,生成虚拟表v6
第七步:order by 按照条件排序v6这个时候返回的是一个游标,而不是虚拟表了,
第八步:limit 或者 top 返回给用户想要的行数数据。
Mysql数据存储结构
索引的数据结构主要有一下几种
1:二叉树:容易单边增长【因为树结果特点 ,节点左边的数据小于节点,接单右边的数据大于节点】
2:黑红树:大数据量的时候,树深度不可控
3:hash表:没有版本做范围查找
4:B-Tree:每个叶子节点保存了除当前索引外的所有数据,所以每个大节点保存的索引可以比较多【大节点值保存了索引数据,完整数据在叶子节点保存】
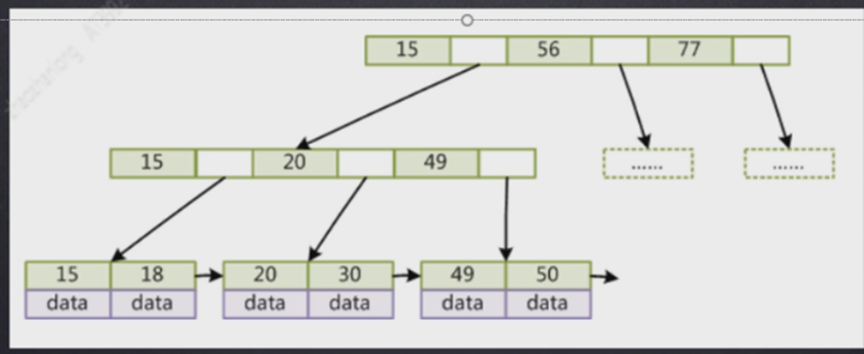
MyisAm存储引擎的数据结构如下
主键索引存储
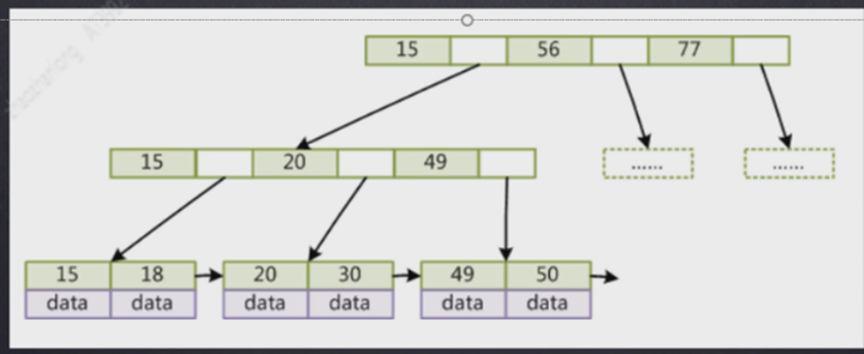
非主键索引存储
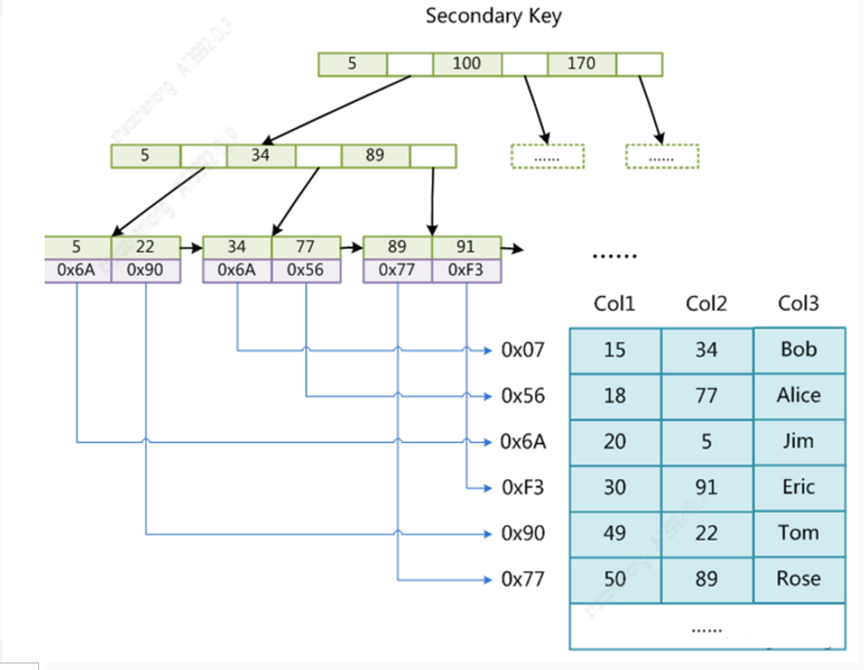
我们发现myisam存储引擎不管是主键索引还是非主键索引其实差别不大,叶子节点保存的都是数据的地址,所以查询都时候没有太大差别,只要你的字段被索引覆盖那就很快,如果要是没有做到覆盖索引那回表查询其实两种索引没有差别。
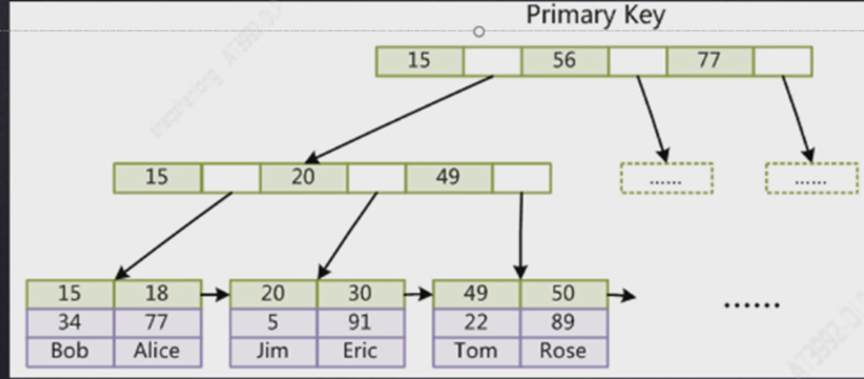
Innodb存储引擎
主键索引
非主键索引
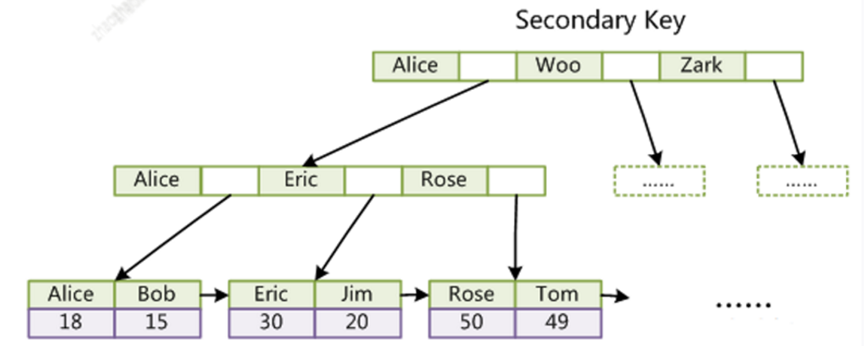
我们发现 要是innodb存储引擎,那么主键索引和非主键索引差别还是很大的,如果是主键索引,叶子节点直接保存的是所有完整数据,所以如果是主键查找就算有些字段没有被索引覆盖,查询也不会很慢,因为主键索引叶子节点有所有数据
但是如果不是主键查找,如果你查询的字段没有被索引覆盖,那么当查询到叶子节点的时候 发现没有找到你需要的字段,那就会根据叶子节点保存的主键的值,在走主键查找来找到你需要的数据,这个就比较慢了, 其实我们做sql优化很大部分就是根据这个原理来做的 ,
Innodb存储引擎主键推荐使用整数为什么
这个主要是和B-Tree数的结构有关系,B-Tree是会做数据平衡的
1:mysql一页数据是16k如果使用整数比使用字符串能放的索引更多
2:字符串比较是按照每一位比较的,索引整数比较更快
3:如果是字符串,我们插入的数据经过hash后不一定在树的最右边,有可能在树的中间或者在最左边,这样B-tree需要做树的再平衡,索引树会发生裂变,【不是说每次添加一定会裂变在平衡,而是说概率会很高】
联合索引的数据结构如图
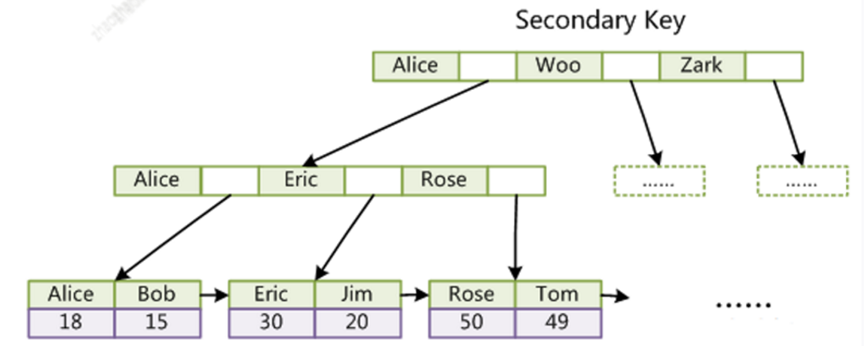
索引我们做 数据库优化就是根据上面的标结果特点做的, 做优化的手段就是让你查询的字段尽量被索引覆盖,不用回表或者在走一篇主键查找,或者尽量查询数据走主键查找, 添加索引规则就是 在能过滤更多数据的字段添加索引,这样可以节省更多的空间,起到更大的作用
三:数据库锁
锁从性能上面分:可以分为乐观锁【版本比对实现,每次拿数据都认为别人不会更改,只有在更新的时候判断一下版本看看有没有人更新这个数据】和悲观锁【每次去拿数据的时候都会认为别人会修改,所以每次拿数据都会上锁,这样其他事务想要拿数据只能等当前操作执行完】
锁从对数据库操作:可以分为读锁【共享锁,对同一个数据做个读操作不会想和影响】和写锁【排它锁,对同一个数据当前操作没有执行
完成会阻断其他操作对当前数据的操作】
锁从数据颗粒度:可以分为表锁【开销小,加锁快,颗粒度大,锁冲突发生的概率高,主要是myisam存储引擎】和行锁【开销大,加锁慢
,锁定颗粒度小,锁冲突发生的概率低,主要是innodb存储引擎】
共享锁:多个不同事务对同一个数据共享同一个锁【如读锁】
mysql的锁机制最为显著的特点就是不同的存储引擎支持不同的锁机制
比如myisam和memory存储引擎采用的是表级别的锁
innodb存储引擎支持的是行级别的锁,
表锁和行锁的应用场景
表锁:并发度不高,以查询为主,有少量更新【读是共享锁,写是排它锁】
行锁:高并发环境,对事务完整性要求比较高【行锁支持事务】
事务和ACID属性
原子性(Atomicity) :事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
一致性(Consistent) :在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
隔离性(Isolation) :数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然【数据库通过加锁来实现事务的隔离性】。
持久性(Durable) :事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
并发事务带来的问题
更新丢失:当多个事务同事更新同一行数据时,由于事务不知道其他事务的存在,就会覆盖了其他事务的更新,就是更新丢失
脏读:事务a读取到了事务b还没有提交的数据,并在此基础上做了操作,这个时候数据b回滚了,那事务a读取的数据就是脏读
不可重复读:事务a在读取数据后的某一个时刻,再次读取数据发现发现以前读取的数据已经改变,或者已经删除,就是事务a读取到了其他事务
提交的数据【注意和脏读的区别,脏读是读取了其他事务没有提交的数据,不可重复读是读取了其他数据已经提交的数据】
幻读:在一次事务中,事务按照相同的查询条件重新查询数据,发现了其他事务插入了 满足条件的数据,这就是幻读,事务a读取到了事务b新增
的数据【不符合隔离性】
所以数据库设计了 隔离级别来解决我们的问题
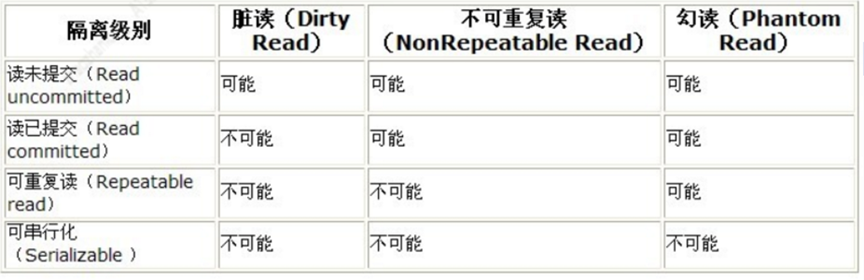
隔离级别越高,并发的副作用越小,但是付出的代价也越大,因为事务隔离实质上就是使事务在一定程度上串行化
查看innodb锁竞争情况
show status like'innodb_row_lock%';
对各个状态量的说明如下:
Innodb_row_lock_current_waits: 当前正在等待锁定的数量
Innodb_row_lock_time: 从系统启动到现在锁定总时间长度
Innodb_row_lock_time_avg: 每次等待所花平均时间
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花时间
Innodb_row_lock_waits:系统启动后到现在总共等待的次数
对于这5个状态变量,比较重要的主要是
Innodb_row_lock_time_avg (等待平均时长)
Innodb_row_lock_waits (等待总次数)
Innodb_row_lock_time(等待总时长)
查看近期死锁日志信息:show engine innodb status\G;
大多数情况mysql可以自动检测死锁并回滚产生死锁的那个事务
数据库事务问答
数据库事务的主要作用是什么:保证数据的一致性
数据库事务并发会引起什么问题:脏读,重复读,和幻读
数据库怎么解决事务并发问题:设置事务隔离级别【读未提交,读已提交,重复读,串行化】
数据库通过什么方式保证事务隔离:通过加锁来实现事务隔离性
频繁加锁会带来什么问题:读写要竞争锁资源,极大的降低了数据库的性能
数据库怎么解决加锁后数据库性能问题的:Mvcc多版本控制,读数据不用加锁,可以让读数据的同时修改数据,修改数据的同时读取数据
MySql数据库日志,binlog,redo log,undo log
首先我们要知道这三种日志做的目的不一样
binlog:作为mysql操作记录的归档日志,里面记录了对数据库的数据,表结构,索引等等的变更记录,binlog是server层的日志,在mysql里面binlog主要用来做归档,验证,恢复和同步数据的。
redo log和undo log是引擎层(Innodb)的日志,要是使用其他存储引擎就不一定有 redo log和undo log了。
binlog
binlog设计的目标是做数据的归档,验证,恢复和数据同步
binlog是mysql里面最核心的日志,它记录了除了查询语句(select,show)之外的所有ddl和dml语句,这也就意味着我们基本上对数据库的操作变更都会记录到binlog里面, binlog有三种记录方式, row,Statement,Mixed
Row:基于变更行的记录,比如我们执行一个update 语句这个语句更改了10条数据,那么在这种模式下,就会记录10条对应的更改日志
Statement:这个是基于sql级别的记录,比如我们还是执行一个 update这个语句更改了10条数据,但是这种模式只会记录这条语句,不会记录详细的10行数据的sql
Mixed:混合模式,这个是Row和Statement的混合体,一般语句使用Statement,但是如一些函数,Statement无法完成主从复制的,那就采用Row记录
binlog数据记录流程,在事务进行中,事务首先把binlog写入到binlog cache中,因为写入cache要比直接刷到磁盘要快得多,在事务最终提交的时写入磁盘,但是我们可以通过sync_binlog来设置,
sync_binlog=0:每次提交事务binlog不会马上写入磁盘,而是写到page cache中,但是这种模式有丢日志的风险
sync_binlog=1:每次提交事务都会执行fsync写入磁盘,性能损耗比较大
syn_binlog=N:n是大于1的值,每次提交事务,先把数据写入到page cache中,等累计到了n在fsync写入到磁盘,同样的这个也会有丢日志的风险
red log
red log里面记录的也是操作数据变更记录,但是他和binlog的记录颗粒度不一样,而且记录的时间点不一样
比如我们执行一条语句 update xxx set name=‘zzl’ where age=20,如果数据库里面有两条age=20的数据的话,很明显我们binlog里面的记录应该是
update 'xxx' 'xxx' where @1=1 @2='aaa' @3=20 set @1=1 @2='zzl' @3=20
update 'xxx' 'xxx' where @1=2 @2='aaa' @3=20 set @1=2 @2='zzl' @3=20
这就是binlog里面的记录影像了两条,所以两行记录,
但是redo log里面的记录是记录的磁盘数据室的变更,以磁盘的最小单位“页”来记录,所以redlog的日志记录应该是
把表空间1,页号3,偏移量10的值更新为zzl
把表空间9,页号20,偏移量3的值更新为zzl
当我们把数据保存到磁盘的过程中,mysql是以页单位进行刷盘的,这里的页指的是mysql的数据页 16kb,当我们吧mysql 一页的数据刷盘的时候,会把mysql的一页数据刷到磁盘的多个扇区里面,然后把一页16kb的数据刷到多个扇区这个过程是无法保证原子性的 ,比如数据库宕机,有可能一页16kb的数据,有的扇区刷成功了,有的扇区没有刷到,这个时候如我我们使用binlog这种级别的日志是没有办法做恢复的,所以这个时候我们需要使用redlog这种记录来做数据恢复
redlog占用的空间是一定的,不会无限增大,可以通过参数设置,redlog的数据写入是顺序写入,如果redlog满了,就从头开始覆盖写入,并且redlog也有一个 redo log buffer来确定日志什么时间刷盘
innodb_flush_log_at_trx_commit
0:表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ;
1:表示每次事务提交时都将 redo log 直接持久化到磁盘
2:表示每次事务提交时都只是把 redo log 写到 page cache。
undo log
redo log和undo log都是引擎层【Innodb】的日志,redo log主要是用来保证事务的持久性【保证操作成功】,undo log的核心就是保证事务的原子性,事务提交需要redlog来保证持久性,但是事务回滚需要undo log来保证原子性【undo log记录的是数据更变以前的原始数据】,而且undolog除了做事务回滚日志外,还有一个主要功能就是为数据库提供Mvcc多版本控制。
在mysql里面每次修改数据前,都会吧修改前的数据拷贝到undo log一份,拷贝的这份数据里面还会记录操作该数据的事务id,事务回滚就是通过这个id进行的。
比如我们有一下一个数据表

注意:Db_TRX_ID和Db_ROLL_PTR是数据库的隐藏字段,每个表都有这两列只是不显示,
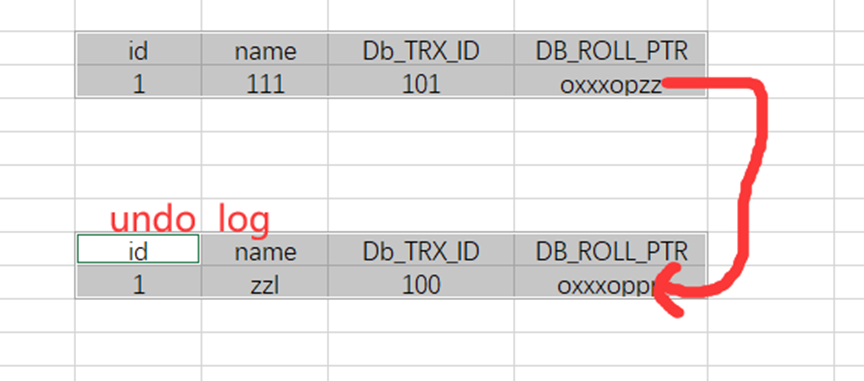
如果我们执行了 update user set name='aaa' where id=1
执行步骤大致如下
1:首先获取一个新的事务id 101
2:吧user表里面的数据拷贝到undo log里面
3:修改user表id=1的数据
4:把修改后的数据事务版本号改成当前事务,并且吧DB_ROLL_PTR回滚地址执行到undo log拷贝的
最后结果就是
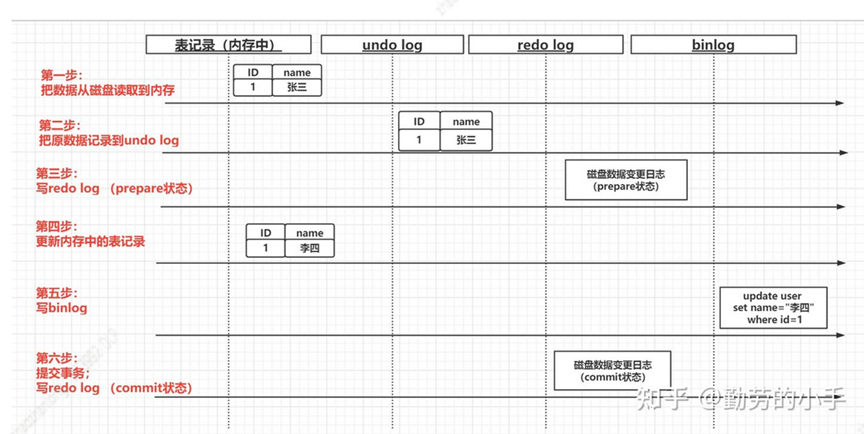
日志执行顺序:
1:从数据库读取数据到内存
2:记录undo log日志
3:记录red log日志【预提交状态】‘
4:修改读到内存的数据值
5:记录binlog日志
6:提交事务,写入redo log 【commit 状态】
借用一个网络图
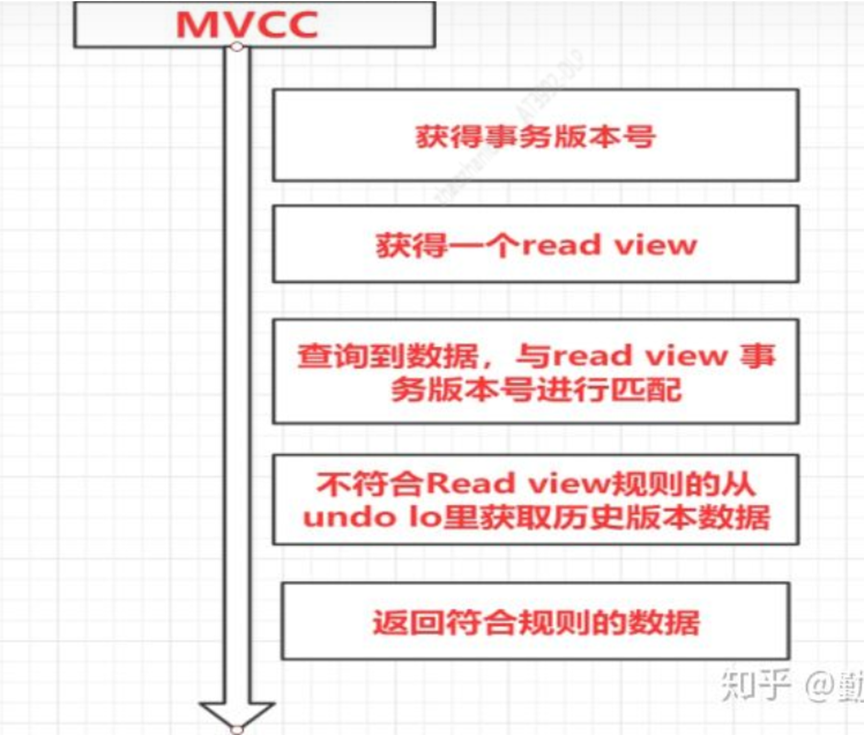
Mysql中的MVCC
MVcc通过保存历史版本,根据版本比较来处理数据是否显示,从而达到读取数据的时候不需要加锁就可以保证事务的隔离性
MVcc几个核心点
事务版本:每个事务开启前都会从数据库获取一个自增的id,我们可以通过这个id知道事务执行的先后顺序
表格隐藏列:
DB_TRX_ID:记录操作该数据事务的id
DB_ROLL_PTR:指向上一个版本数据在undo log里的指针
DB_ROW_ID:当创建表没有合适索引作为聚集索引时候,会用这一列做聚集索引
undo log: 这个前面我们已经说过了
Read View:Innodb中每次开启一个事务就会得到一个read_view主要用于保存当前数据库系统中正处于活跃(没有commit)的事务id号,也就是说read_view中保存的是系统中不应该被本事务看到的其他事务列表
read_view中几个主要的属性
trx_ids:当前系统未提交的事务id集合
low_limit_id:创建当前read_view时,当前系统最大事务id+1
up_limit_id:创建当前read_view时,系统活跃的最小事务id【未提交的最小事务id】
creator_trx_id:创建当前read_view的事务id
Read_View匹配条件【和undo log的配对】
1:undo log中当前事务<up_limit_id:当前事务id小于系统最小事务活跃id,可以肯定该数据是在当前事务开启之前就已经存在可以显示< div="">
2:undo log当前事务>Low_limit_id:说明该数据是在当前事务Read_View创建之后产生的,不能显示
3:up_limit_id
![]()
![]()
借用知乎上面一张图
执行流程如下【知乎截图】
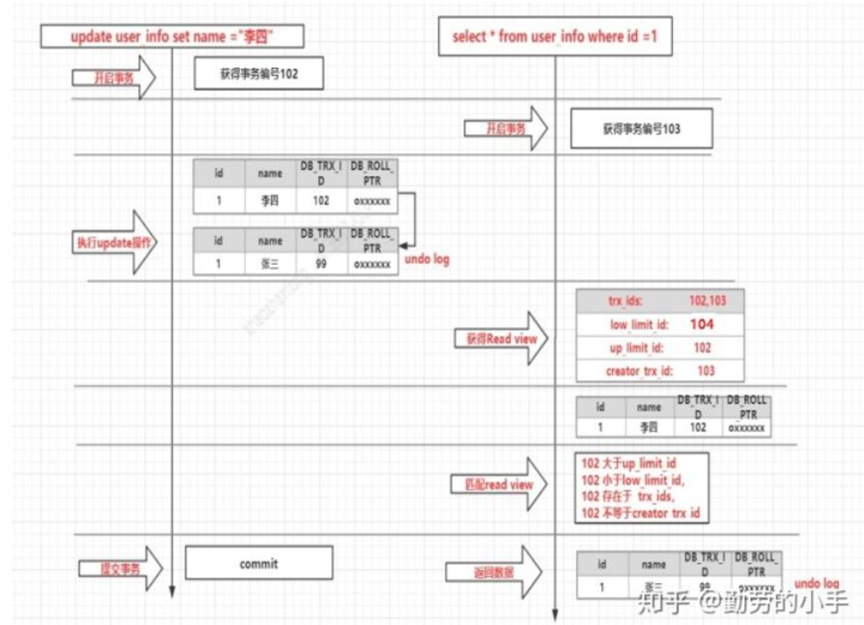
MVcc控制read_view查询数据会先查询读取到内存数据,如果发现不能展示那就去undo log,如果找到的第一个nudolog不能展示
那就继续向下查找undo log直到找到可以显示的undo log【其实就是undo log中事务版本和read_view中事务保本比对】
不同的事务隔离级别获取read_view不一样
Rc【read commit】级别下,同一个事务每次执行一次查询就会生成一个新的read_view,所以可能出现事务里面数据不一致的问题
RR【重复读】级别下,同一个事务不管执行多少次查询,只会获取一个read_view所以每次查询的数据都是一样的
当前读和快照读
快照读:读取的不是数据的最新版本而是基于历史版本的一个快照【undo log历史版本】,快照读可以使普通的select不用加锁。解决因为加锁写数据无法读,或者读数据无法写
当前读:读取数据库最新数据,因为读取的是数据库最新数据,而且要保证事务隔离性,所以需要对数据进行加锁 执行sql 需要添加
lock in share mode select for update 为当前读

 浙公网安备 33010602011771号
浙公网安备 33010602011771号