
用 GPT-5.2 Vibe Coding,做了一个可以“玩”的人脸相似度应用
在做人脸相关的产品时,很多系统都会直接给出一个“是否同一人”的结论。但在不少场景下,这种二元判断其实有点无聊——我们更关心的往往是:到底有多像?
你可以把它当成一个小实验来玩:对比自己年轻时和现在的照片,看看变化有多大;把孩子的照片和父母分别比一比,看看更像谁;或者试试兄弟姐妹在不同年龄、不同光线下的相似程度。
Face Metric 就是这样一个尝试:
它不是做人脸验证(verification),而是返回一个连续的人脸相似度分数,把判断权交给使用者。
本文主要记录这个项目的设计思路、后端算法选择,以及一些工程上的取舍。
源代码:https://github.com/neozhu/face-metric
Demo: https://face-metric.blazorserver.com/
项目概览
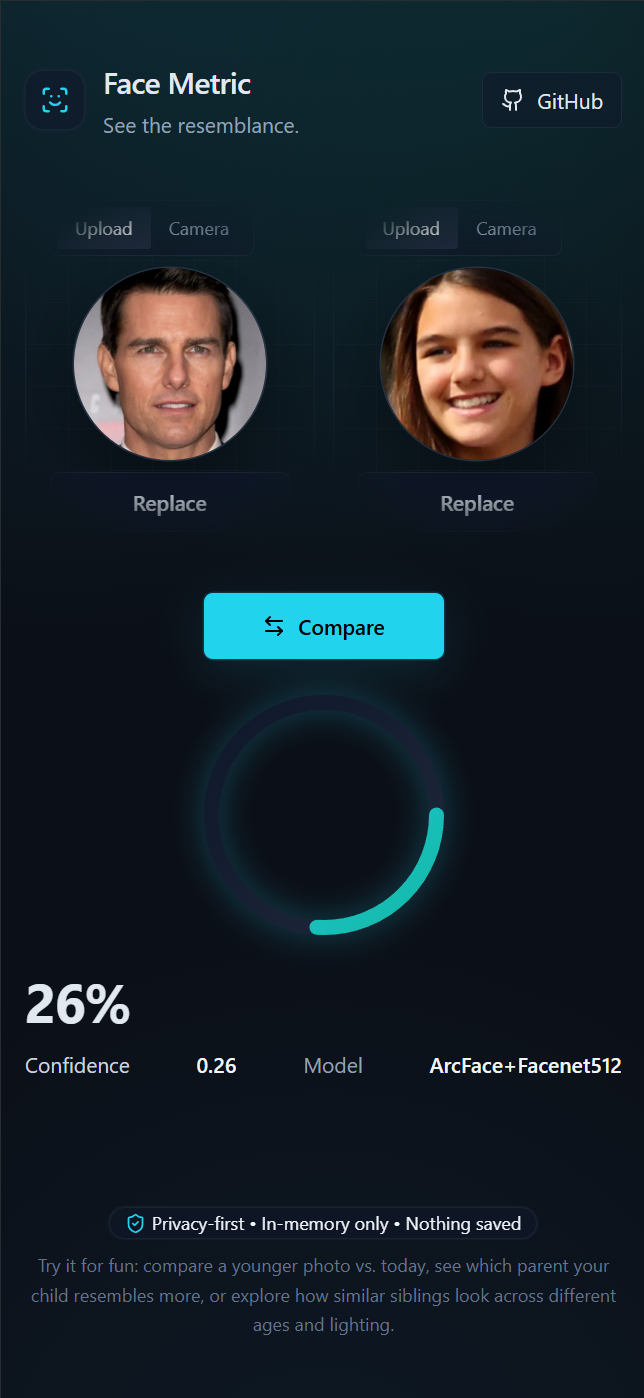
Face Metric 是一个暗色风格优先的 Web 应用,功能非常简单:
- 上传或拍摄两张人脸照片
- 点击 Compare
- 得到一个 0–100% 的相似度结果(动画圆环展示)
整体结构是典型的前后端分离:
apps/
web/ Next.js UI
api/ FastAPI service
specs/ 产品与工程规格说明
前端负责交互和展示,后端只做一件事:给两张图片算一个相似度。
为什么不直接用“是否同一人”?
在调研人脸识别库时会发现,大多数 API 都是围绕 verification 设计的,本质是:
embedding → distance → threshold → yes / no
但阈值本身是一个非常“上下文相关”的东西:
- 安防场景和娱乐应用的容忍度完全不同
- 不同模型、不同数据分布,阈值也不同
Face Metric 的选择是干脆不做阈值判断,只返回一个连续值,让上层系统自己决定怎么用。
后端算法流程
后端基于 DeepFace,但并不是“直接调一个函数返回结果”,而是把流程拆开,尽量让每一步都可控。
1. 图片解码与校验
- 校验类型和大小
- 只在内存中处理,不落盘
- 单次请求生命周期结束即释放
这一点主要是为了隐私和部署简单。
2. 人脸检测与对齐
使用 DeepFace 的检测与对齐能力:
- 默认检测器:RetinaFace
enforce_detection=Truealign=True
这里的策略很明确:
宁可失败,也不猜。
如果任意一张图里检测不到人脸,API 会直接返回错误,而不是给一个“看起来合理”的分数。
3. 特征向量(Embedding)
默认模型选择的是 ArcFace,原因很简单:
- 在人脸识别领域成熟
- embedding 判别性强
- 社区和工程实践都比较稳定
同时加了一个兜底模型:
- 主模型失败 → 回退到
Facenet512
这不是为了追求“更高精度”,而是提升工程稳定性。
4. 距离计算
对于每一个成功生成 embedding 的模型:
- 使用 cosine distance
- 得到一个
[0, +∞)的距离值
cosine 距离在高维 embedding 场景下表现比较稳定,也便于后续做线性映射。
5. 多模型融合(可选)
如果多个模型都成功:
- 对它们的 cosine distance 取平均
- 得到一个 fused distance
这一步的目标不是“集成学习”,而是降低单模型偶发波动。
6. 相似度映射
最后一步非常直接:
similarity = clamp(1 - fused_distance, 0..1)
- 不做 sigmoid
- 不做复杂归一化
- 不引入任何“经验阈值”
UI 端只负责把它渲染成百分比。
前端的一点取舍
前端用 Next.js,设计上刻意保持克制:
- 深色背景,减少对照片的干扰
- 动画只用在结果出现的一瞬间
- 不提示“是否同一人”,只展示数值
UI 的目标不是“显得智能”,而是让结果本身更容易被理解。
关于隐私
这个项目在设计时有几个明确原则:
- 图片只存在于内存
- 不写磁盘、不做缓存
- 不记录历史请求
Face Metric 更像一个“计算器”,而不是一个“系统”。
本地运行与部署
为了降低体验成本:
- Web + API 可以本地直接跑
- 也提供单镜像 Docker Compose
- 不需要额外环境变量
工程上尽量做到:clone → run → 用。
一点总结
Face Metric 本质上不是一个“新算法”,而是一次工程取向的整理:
- 把人脸相似度从二元判断中解放出来
- 把每一步处理过程显式化、可解释
- 在精度与稳定性之间偏向后者
如果你需要的不是“是否同一个人”,而是“看起来有多像”,这种设计思路可能会比直接套 verification API 更合适。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号