【K8S】深入讲解 Kubernetes Operator 设计模式
1. 简短定义与动机
Operator 本质上是把人类运行/维护某个复杂应用的知识(运维逻辑)编码成控制器——把复杂的操作(安装/升级/备份/恢复/扩容/回滚/拓扑调整)以声明式 API(CRD)暴露出来,由控制循环自动化执行。
动机包括:
- 把领域知识(DB bootstrap、数据迁移、leader 选举、滚动升级顺序等)自动化;
- 把操作暴露为 Kubernetes 原生 API(CRD),便于 GitOps / CI/CD;
- 把应用运维与集群运维统一成声明式流程,提升可重复性与可靠性。
2. Operator 的基本架构(Mermaid 图)
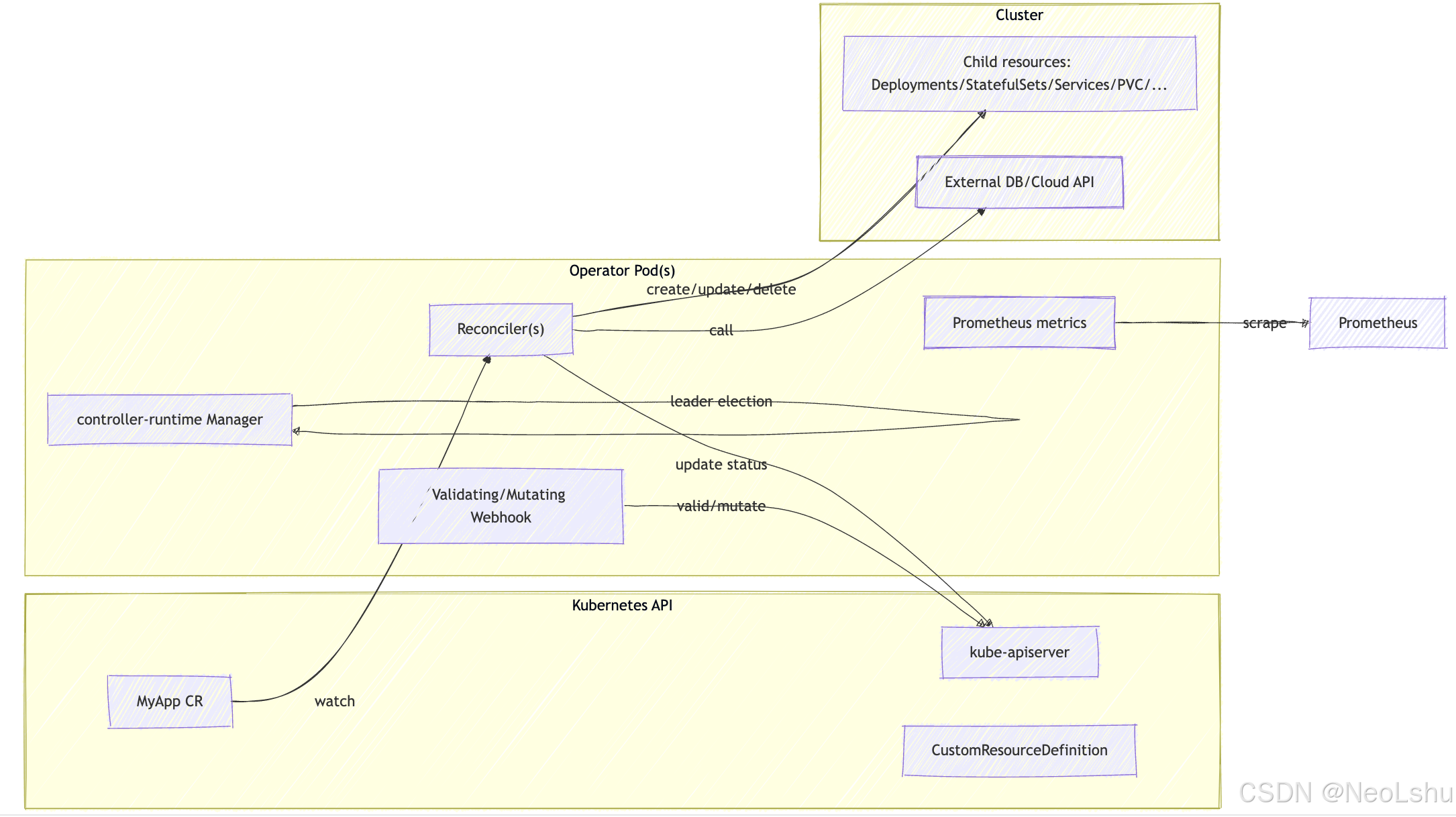
说明:Operator 通常包含:CRD(定义 API);Controller(s)(Reconciler 实现);可选 Webhook(校验/默认);metrics 与 health probes;并在 Manager 中运行(支持 leader election、多副本高可用)。
3. 核心概念(必须掌握)
- Reconciliation Loop(调和循环):Reconcile(ctx, req) 函数是核心。设计哲学:把期望状态(spec)和当前状态(cluster)对齐。关键是幂等且无副作用(即多次运行应可重复/安全)。
- CRD(CustomResourceDefinition)+ CR(CustomResource):自定义 API,对外暴露操作对象。
- 最终器(Finalizer):在 CR 被删除前拦截,做清理工作(如删除外部资源、备份、释放云盘),然后移除 finalizer 以允许删除完成。
- Status / Conditions:将运行时状态、进度、错误信息写入
.status(建议使用 Conditions 模式),避免把状态写到 spec。用 status subresource(CRD 的/status)和 RBAC 限制写权限。 - Controller pattern(ownerReference / garbage collection):通过
ownerReference使 Kubernetes 自动回收子资源;但注意跨-namespace 的限制(ownerRef 只能在同 namespace)。 - Leader Election:多副本 Operator 时要使用 leader election 避免重复工作或竞争。
- Webhook(Validating/Mutating):用于入参校验、字段默认化(defaulting)与复杂的转换(CRD schema 不能表达的约束)。
- Side effects & External calls:Operator 常与外部服务(云 API、存储后端)交互,需做重试、幂等和超时设计。
4. 常见设计模式(Patterns)与详细说明
下面是工程级常用模式(带目的与实现要点)。
4.1 控制器/协调器模式(Single Reconciler / Multi-Reconciler)
- Single Reconciler per CR(每种 CR 一个 Reconciler):清晰、直观,适合中等复杂度。
- Multi-Reconciler (subcontrollers):当某个 CR 很复杂(如多个独立子域:bootstrap、backup、metrics),把逻辑拆成多个小 Reconciler(或多个 controllers)分别处理 watch 的子集,降低单一 Reconciler 复杂性。
- 实现要点:使用事件/Condition 进行模块间协作,或使用
status字段作为协议(例如status.phase)。
4.2 资源管理(Create/Update/Ensure)– “Declarative child resource” 模式
- 目标:对 child resource 使用
CreateOrUpdate(或 controllerutil)确保期望字段被应用,同时不要覆盖用户自定义字段(比如 annotations)。 - 技巧:把“模板转化”为“期望状态”,并用
controllerutil.CreateOrUpdate(ctx, client, obj, mutateFunc)。注意 mutateFunc 内只设置 operator 管理的字段。 - 避免:用
Update全覆写时丢失用户变更。
4.3 Finalizer 模式(优雅清理)
- 流程:当 CR 被标记删除(DeletionTimestamp != nil)且存在 finalizer 时,在 reconcile 中执行清理逻辑(例如解绑外部资源、触发快照、记录状态)。清理完成后移除 finalizer 更新 CR。
- 实现细节:清理逻辑要幂等并可重试;如果清理失败,应设置 status condition 并 requeue。
4.4 Condition 模式(Status Conditions)
- 目的:把运行状态分拆成有意义的 condition(如
Ready,Progressing,Degraded),便于 UI/运维判断。Conditions 使用status.conditions数组并包含type,status,reason,message,lastTransitionTime。 - 库:controller-runtime/ kubebuilder 提供 condition helpers。
4.5 OwnerReference 与 Garbage Collection
- 目的:通过
SetControllerReference(parent, child)让 Kubernetes 在 parent 删除时回收 child。 - 限制:跨 namespace 不支持;OwnerRef 可能导致意外删除(审慎使用)。
- 替代:用自定义 finalizer 管理跨-namespace 或复杂依赖关系。
4.6 Leader-Election 与 Sharding
- 基本:Manager 设置 leader election,只有 leader 执行 reconcile 以避免重复操作。
- Sharding(分片):在超大规模场景,用 label-based 或 Lease-based 分片,把 CR 划分为不同 shard,每个 Operator 只处理一部分,提升吞吐与缩短 reconcile 延迟。
- 实现:在 controller 的
SetupWithManager使用Predicate限制 watch 或用自定义 queueKeyFunc。
4.7 Webhook(Defaulting/Validating/Conversion)
- Defaulting:补默认值比 CRD 的
default更灵活(支持复杂默认),但应尽量在 CRD schema 中使用default。 - Validating:阻止非法 spec 到 API Server,早期拦截,减轻 reconcile 复杂度。
- Conversion webhook:用于 CRD 版本转换(v1alpha1 ↔ v1beta1 ↔ v1),复杂变更需 conversion webhook。
4.8 Operator as State Machine(Phase 机)
- 思路:把复杂操作分阶段(
phase),例如Pending→Provisioning→Ready→Degraded→Deleting。每个阶段的 reconcile 负责推进下一阶段。 - 优点:清晰的执行路径,便于恢复和审计。
4.9 Delegation(Helm/Ansible Operators)
- Helm Operator:把管理交给 Helm 模板(operator 负责渲染/升级 Helm release)。
- Ansible Operator:把运维逻辑用 Ansible playbook 编写并由 operator 调用。
- 适用:当已有复杂 Helm chart 或 Ansible 流程,快速上手;缺点是调试/可观测性比 Go 控制器弱。
4.10 Observability & Eventing pattern
- 事件记录(Event):使用
recorder.Event(obj, eventType, reason, message)报告关键事件,便于排查。 - Metrics:导出 reconcile 时间、success/fail counts、queue depth、resource counts(Prometheus)。
- Tracing:在重试链中保留 trace ,用于跨组件问题追踪。
5. Reconcile 核心骨架(Go,controller-runtime)——示例与注释
下面是一个常见且完整的 Reconcile 骨架(含 finalizer、CreateOrUpdate、status 更新、错误/重试处理):
package controllers
import (
"context"
"time"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
"sigs.k8s.io/controller-runtime/pkg/controller/controllerutil"
corev1 "k8s.io/api/core/v1"
myv1 "example.com/api/v1"
)
const finalizerName = "myapp.example.com/finalizer"
type MyAppReconciler struct {
client.Client
Scheme *runtime.Scheme
}
func (r *MyAppReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
var instance myv1.MyApp
if err := r.Get(ctx, req.NamespacedName, &instance); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
// 1) Handle deletion via finalizer pattern
if instance.ObjectMeta.DeletionTimestamp.IsZero() {
// add finalizer if not present
if !containsString(instance.Finalizers, finalizerName) {
instance.Finalizers = append(instance.Finalizers, finalizerName)
if err := r.Update(ctx, &instance); err != nil {
return ctrl.Result{}, err
}
}
} else {
// object is being deleted
if containsString(instance.Finalizers, finalizerName) {
// perform cleanup (idempotent)
if err := r.cleanupExternalResources(ctx, &instance); err != nil {
// set status condition and requeue
r.setStatusCondition(ctx, &instance, "Deleting", false, "CleanupFailed", err.Error())
_ = r.Status().Update(ctx, &instance)
return ctrl.Result{RequeueAfter: time.Minute}, err
}
// remove finalizer
instance.Finalizers = removeString(instance.Finalizers, finalizerName)
if err := r.Update(ctx, &instance); err != nil {
return ctrl.Result{}, err
}
}
return ctrl.Result{}, nil
}
// 2) Ensure child resources (Deployment/Service/PVC etc); use CreateOrUpdate
dep := buildDeployment(&instance)
if err := controllerutil.SetControllerReference(&instance, dep, r.Scheme); err != nil {
return ctrl.Result{}, err
}
opResult, err := ctrl.CreateOrUpdate(ctx, r.Client, dep, func() error {
// mutate desired fields only (replicas, image, env, volumes)
dep.Spec.Replicas = pointer.Int32Ptr(instance.Spec.Replicas)
// ... other fields
return nil
})
if err != nil {
r.setStatusCondition(ctx, &instance, "Ready", false, "SyncFailed", err.Error())
_ = r.Status().Update(ctx, &instance)
return ctrl.Result{RequeueAfter: time.Minute}, err
}
// 3) Update status based on child resources (read-only path)
instance.Status.ReadyReplicas = dep.Status.ReadyReplicas
instance.Status.ObservedGeneration = instance.ObjectMeta.Generation
if err := r.Status().Update(ctx, &instance); err != nil {
return ctrl.Result{}, err
}
return ctrl.Result{}, nil
}
要点说明:
client.IgnoreNotFound(err):CR 被删除后忽略 404。- Finalizer 保证异步清理外部资源可完成(比如 cloud disk detach/delete)。
CreateOrUpdate或controllerutil.CreateOrPatch用于安全更新子资源,避免覆盖用户非 operator 管理字段。- 状态更新:使用
r.Status().Update()更新.status,避免修改.spec。 - 错误处理:失败时设置 status conditions 并适当
RequeueAfter而不是持续短循环重试。
6. CRD 设计最佳实践(Spec / Status / Versioning)
- 明确分工:
spec表示用户期望(不可随意写入),status表示实际运行时信息(operator 写入)。 - 使用 Conditions:细粒度状态(Ready/Progressing/Degraded)+ reason/message。
- Schema validation:利用
openAPIV3Schema(CRD v1)在 API Server 做基础校验,减少 webhook 工作量。 - Versioning & Conversion:若支持多个版本(v1alpha1 -> v1beta1 -> v1),实现 conversion webhook 或使用 CRD 的
conversionstrategy,保持向后兼容。 - Defaulting:在 CRD schema 中使用
default或通过 mutating webhook 做复杂 defaulting。 - Subresources:启用
statussubresource(spec与status的独立 RBAC),可启用scalesubresource(如果必要)。 - Avoid storing secrets in status:不要把敏感数据写入 Status(会被泄露)。
7. 测试、CI 与质量保证
- Unit tests:对业务逻辑进行单元测试(模拟 client)。
- envtest / Integration tests:controller-runtime 提供
envtest,可以在本地运行真实 API server + etcd 进行集成测试(推荐用于 CRD & controller 测试)。 - E2E tests:在真实 k8s 集群上跑 e2e(包含网络、storage、外部依赖)。
- Mutation/Validation webhook tests:测试 webhook,确保在各种 invalid/edge cases 拦截。
- Chaos tests:断网、API Server 暂停、节点重启等,用于验证 operator 的容错与回滚策略。
- CI pipeline:自动化 lint(yamllint、kubeval)、go vet、static analysis、以及镜像构建与镜像扫描。
8. Observability(监控/日志/追踪)与运维
- Metrics:export reconcile loop durations, counts, queue depth, last sync time; 用 Prometheus scrapping。
- Events:在关键操作上记录 Kubernetes Event,便于 kubectl describe 时看到人类可读信息。
- Logs:结构化日志(JSON),包含 trace-id、request uid、cr name/namespace。
- Tracing:支持分布式追踪(OpenTelemetry),尤其当 operator 调用外部 API 时保留 trace。
- Health / Readiness:expose
/healthz/readyzprobes,Manager 框架支持 probe 注册。 - Debug endpoints:可选地导出诊断信息(当前 queue 状态、last reconcile times)。
9. 安全性与 RBAC 最佳实践
- 最小权限原则:为 operator 创建单独 ServiceAccount,授予最小必要权限(只对 CRD 所需 operations + 子资源的操作)。
- Secret 管理:不要把 secrets 写入 status;对外部凭据使用 Kubernetes Secret,并在 operator 中以最小作用域挂载(只在需要的 Pod/Namespace)。
- Webhook TLS:validating/mutating webhook 需要 TLS,使用 cert-manager 或 operator 管理证书自动签发与轮换。
- Run as non-root:Operator Pod 运行用户非 root,设置 PodSecurityContext。
- Audit:审计关键操作(谁触发,何时变更 CR)。
10. 扩展性、性能与大规模部署策略
- 并发与限流:controller-runtime 的
MaxConcurrentReconciles控制并发。调整以适配外部后端吞吐与集群控制面压力。 - 缓存与 Indexer:使用 field/index 索引(
IndexField)加速查询,避免全量 list。切忌在 reconcile 中做大量List调用。 - Namespace-scoped Operator:如果仅需管理单命名空间,部署 namespace-scoped operator,降低 RBAC 范围和 watch 负载。
- Sharding:对极大量 CR ,使用 label-based 分片或 Lease 分片,使不同 operator 实例处理子集。
- QueueKeyFunc / Predicate Filters:通过 Predicates 和 QueueKeyFunc 限制不必要的 reconcile 触发(例如资源的 annotation 变更不触发重建)。
- OwnerRef vs Manual Garbage Collection:对于多 namespace 或复杂外部资源,使用 finalizer 而不是 ownerRef 来避免误删。
11. 常见反模式与陷阱(要避开的做法)
- 在 reconcile 中做长时间阻塞(比如等待外部操作完成而不回收资源/超时),应把长任务异步化并周期性更新 status。
- 直接 Patch spec of child resources blindly(覆盖 user 修改),应只控制 operator 管理的字段。
- 在 status 写入敏感信息,会造成泄露风险。
- 没有幂等设计:导致重复 reconcile 引发资源泄露或外部系统混乱。
- 忽略 error classification:临时错误(网络)与致命错误(invalid spec)处理应不同:前者 requeue,后者记录并不再重试直到 spec 更改。
- 把 too much logic 放在 webhook:webhook 用于校验与默认,而不是实现复杂业务流程(会影响 API Server 可用性)。
12. 真实世界 Operator 场景与模式总结
-
Stateful Application Operator(例如数据库 operator)
关键点:ordered rolling upgrades、leader-aware backup、PVC 激增管理、数据迁移脚本、 fencing/leader change handling、safety first(避免 split-brain)。 -
Cloud Resource Operator(例如 cloud SQL operator)
关键点:调用云商 API(幂等、限流、重试),CRD 状态同步(async),secret lifecycle 管理(credentials)。 -
Platform Operator(配套平台)
关键点:管理平台级别服务(ingress controller、vault、logging stack),需要集群级视图、租户隔离、RBAC 复杂性。 -
Helm-based Operator
适合有广泛 Helm charts 的场景,operator 管理 chart 的 release lifecycle,但需要处理 chart 的差异化升级策略。
13. 实战小贴士(Checklist)
- CRD:设计好 spec/status,enable
statussubresource,写 openAPI schema。 - Reconcile:保持幂等;短小且快速;把长任务异步化。
- Finalizer:实现且幂等;记录 cleanup 状态到 conditions。
- RBAC:只授予最小权限;单 ServiceAccount 用于 operator。
- Observability:记录 events、导出 metrics、结构化日志。
- Testing:使用 envtest 做集成测试;写 e2e 验证真实场景。
- Upgrade:支持 CRD 版本转换与迁移脚本;在升级中保守推进(canary)并备份关键数据。
- Fail-safe:在关键路径(删除/升级)保留人工可中断点(例如 require annotation 才触发 destructive 操作)。
本文来自博客园,作者:NeoLshu,转载请注明原文链接:https://www.cnblogs.com/neolshu/p/19513683

 浙公网安备 33010602011771号
浙公网安备 33010602011771号