Redis 底层数据结构解析(四):Set 类型与 intset 的紧凑优化
1. 引言:Redis Set 的独特特性
Redis Set 类型是一个无序的字符串集合,它提供了高效的集合操作,如交集、并集、差集等。Set 的底层实现根据数据特征智能地选择两种编码方式:intset(整数集合)和 hashtable(哈希表)。这种双编码策略体现了 Redis 在内存效率与性能之间的精妙平衡。
Set 类型的使用场景非常广泛,包括标签系统、好友关系、唯一计数器、随机抽样等。理解其底层实现机制对于正确使用和优化 Set 类型至关重要。本文将深入剖析 Redis Set 的实现原理,重点关注 intset 的紧凑存储优化和 hashtable 的高效集合操作。
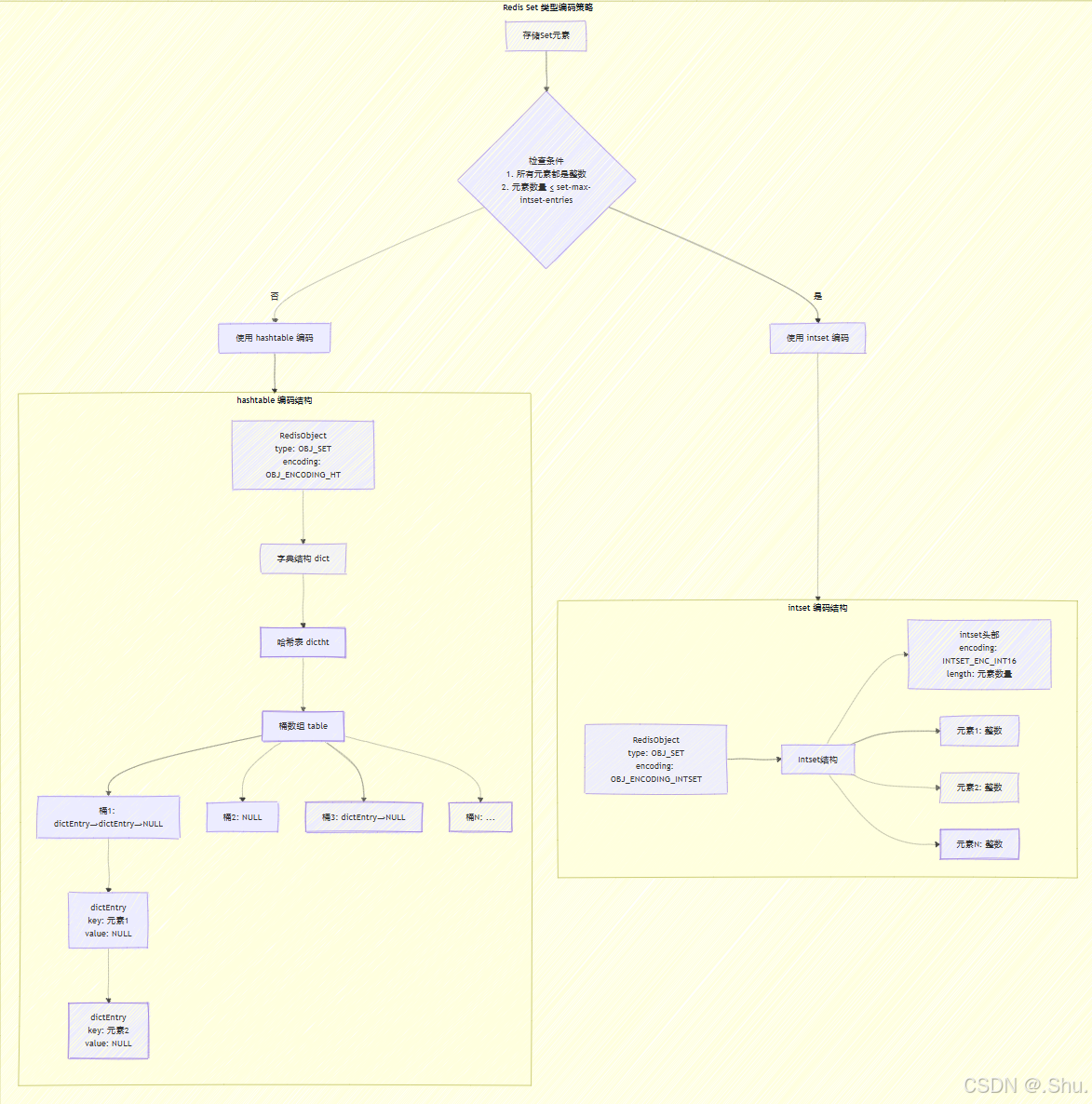
2. Set 类型的双编码策略
2.1 编码转换的配置阈值
Redis Set 根据以下配置参数决定使用哪种编码:
set-max-intset-entries 512 # 最大整数元素数量阈值
当同时满足以下两个条件时,使用 intset 编码:
- 所有元素都是整数值
- 元素数量 ≤
set-max-intset-entries
否则,使用 hashtable 编码。
2.2 intset 编码的紧凑存储
intset 是 Redis 为整数集合设计的紧凑数据结构,它通过有序数组的形式存储整数值,并根据元素大小自动升级内部编码。
intset 结构定义(intset.h):
typedef struct intset {
uint32_t encoding; // 编码方式:INTSET_ENC_INT16、INT32、INT64
uint32_t length; // 元素数量
int8_t contents[]; // 柔性数组,存储实际元素
} intset;
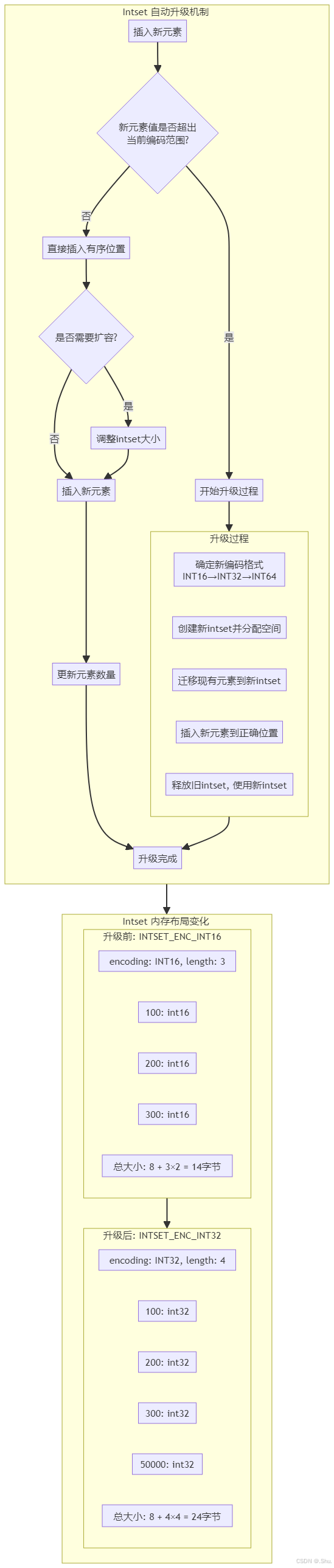
intset 的自动升级机制:
当新插入的整数超出当前编码范围时,intset 会自动升级到更大的编码:
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
uint8_t curenc = intrev32ifbe(is->encoding);
uint8_t newenc = _intsetValueEncoding(value);
int length = intrev32ifbe(is->length);
// 确定新值应该插入的位置(0=开头,1=末尾)
int prepend = value < 0 ? 1 : 0;
// 设置新编码
is->encoding = intrev32ifbe(newenc);
is = intsetResize(is, intrev32ifbe(is->length) + 1);
// 从后向前升级并移动元素
while(length--)
_intsetSet(is, length + prepend, _intsetGetEncoded(is, length, curenc));
// 插入新值
if (prepend)
_intsetSet(is, 0, value);
else
_intsetSet(is, intrev32ifbe(is->length), value);
is->length = intrev32ifbe(intrev32ifbe(is->length) + 1);
return is;
}
2.3 hashtable 编码的高效实现
当不满足 intset 条件时,Set 使用 hashtable 编码,其实现与 Hash 类型的 hashtable 类似,但有一个重要区别:Set 的 hashtable 中所有 value 都设置为 NULL,只有 key 用于存储集合元素。
Set 的 hashtable 内存布局:
[dict结构] -> [dictht] -> [dictEntry数组] -> [dictEntry链表]
每个 dictEntry 的 value 字段为 NULL,仅 key 字段存储集合元素。
3. intset 的深度解析
3.1 intset 的查找算法
intset 使用二分查找算法来定位元素,由于数组是有序的,查找时间复杂度为 O(log n)。
源码实现:
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length) - 1;
int64_t cur;
// 空集合处理
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0;
return 0;
}
// 检查是否超出范围
if (value > _intsetGet(is, max)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
}
if (value < _intsetGet(is, min)) {
if (pos) *pos = 0;
return 0;
}
// 二分查找
while(max >= min) {
int mid = (min + max) / 2;
cur = _intsetGet(is, mid);
if (value > cur) {
min = mid + 1;
} else if (value < cur) {
max = mid - 1;
} else {
break;
}
}
if (value == cur) {
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
}
3.2 intset 的插入与删除
插入操作:
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
// 需要升级编码
if (valenc > intrev32ifbe(is->encoding)) {
return intsetUpgradeAndAdd(is, value);
} else {
// 查找插入位置
if (intsetSearch(is, value, &pos)) {
if (success) *success = 0; // 元素已存在
return is;
}
// 调整大小并插入新元素
is = intsetResize(is, intrev32ifbe(is->length) + 1);
if (pos < intrev32ifbe(is->length)) {
// 移动元素腾出空间
memmove((int8_t*)is->contents + (pos+1)*intrev32ifbe(is->encoding),
(int8_t*)is->contents + pos*intrev32ifbe(is->encoding),
(intrev32ifbe(is->length) - pos)*intrev32ifbe(is->encoding));
}
}
// 插入新值
_intsetSet(is, pos, value);
is->length = intrev32ifbe(intrev32ifbe(is->length) + 1);
return is;
}
3.3 intset 的内存效率分析
intset 的内存效率体现在以下几个方面:
- 紧凑存储:连续内存布局,无指针开销
- 自适应编码:根据元素大小自动选择最小编码
- 有序性:支持二分查找,查询效率高
内存占用对比示例:
存储 100 个整数(范围 0-1000):
- intset(int16):100 × 2字节 = 200字节 + 8字节头部 = 208字节
- hashtable:100 × (16字节dictEntry + 8字节key) ≈ 2400字节
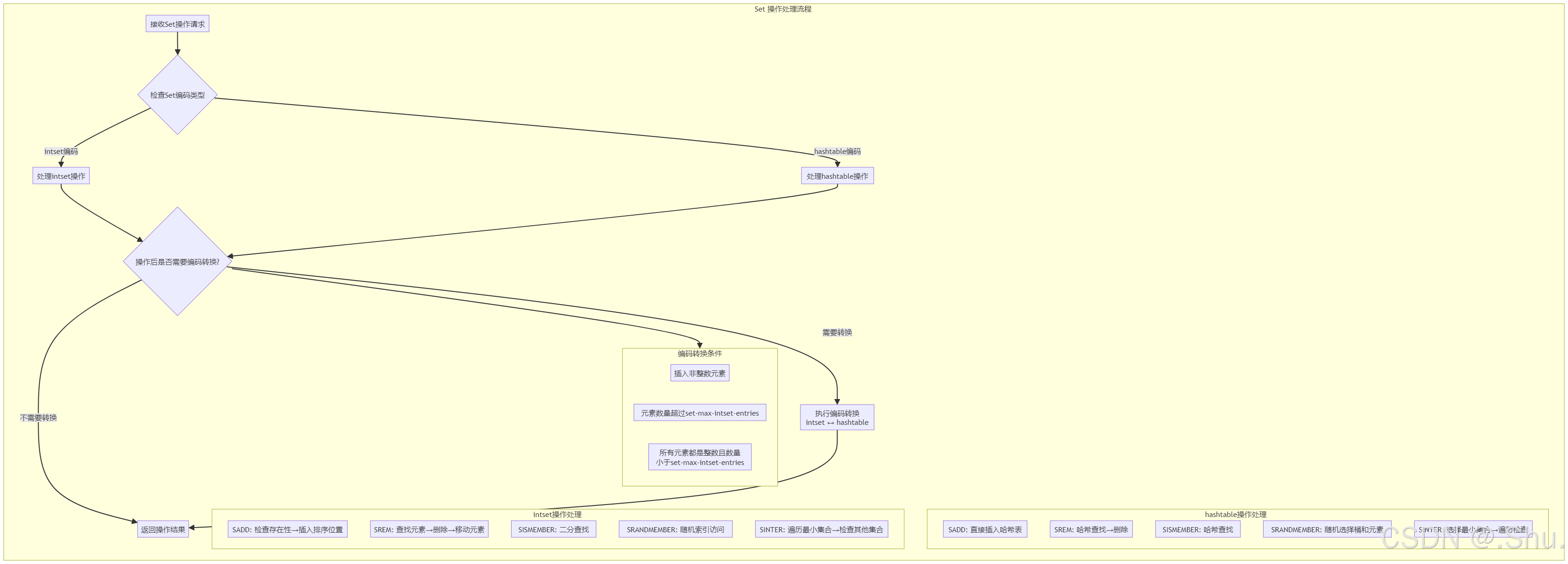
4. Set 操作的高级实现
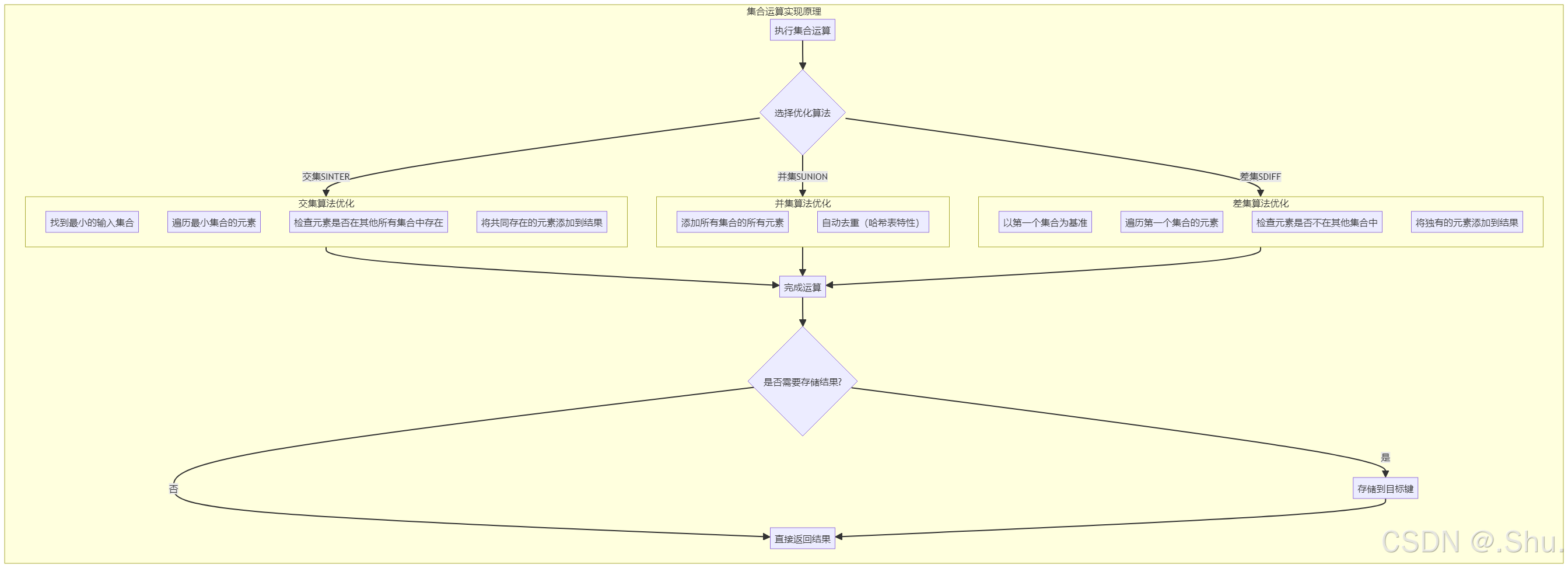
4.1 集合运算的实现
Redis Set 支持丰富的集合运算,这些操作针对不同的编码进行了优化。
交集运算(SINTER):
void sinterGenericCommand(client *c, robj **setkeys, unsigned long setnum, robj *dstkey) {
robj **sets = zmalloc(sizeof(robj*)*setnum);
int j, cardinality = 0;
// 获取所有集合对象
for (j = 0; j < setnum; j++) {
robj *setobj = lookupKeyRead(c->db, setkeys[j]);
if (!setobj) {
zfree(sets);
if (dstkey) {
if (dbDelete(c->db, dstkey)) {
signalModifiedKey(c, c->db, dstkey);
}
addReply(c, shared.czero);
} else {
addReply(c, shared.emptymultibulk);
}
return;
}
if (setobj->type != OBJ_SET) {
zfree(sets);
addReply(c, shared.wrongtypeerr);
return;
}
sets[j] = setobj;
}
// 选择最小的集合作为基准
robj *base = sets[0];
for (j = 1; j < setnum; j++) {
if (setTypeSize(sets[j]) < setTypeSize(base)) {
base = sets[j];
}
}
// 执行交集运算
dict *result = dictCreate(&setAccumulatorDictType, NULL);
setTypeIterator *si = setTypeInitIterator(base);
while (setTypeNext(si, &obj, &intobj) != -1) {
int exists = 1;
for (j = 0; j < setnum; j++) {
if (sets[j] == base) continue;
if (!setTypeExists(sets[j], obj)) {
exists = 0;
break;
}
}
if (exists) {
// 添加到结果集
setTypeAdd(result, obj);
cardinality++;
}
}
setTypeReleaseIterator(si);
// 输出或存储结果
// ...
zfree(sets);
}
4.2 随机元素获取
Set 类型支持随机获取元素(SRANDMEMBER),这对于抽样场景非常有用。
实现原理:
int setTypeRandomElement(robj *setobj, char **objele, int64_t *llele) {
if (setobj->encoding == OBJ_ENCODING_HT) {
// hashtable 编码:随机选择一个桶,然后随机选择链表中的元素
dict *d = setobj->ptr;
dictEntry *de = dictGetRandomKey(d);
*objele = dictGetKey(de);
return 1;
} else if (setobj->encoding == OBJ_ENCODING_INTSET) {
// intset 编码:随机选择索引
intset *is = setobj->ptr;
*llele = _intsetGet(is, rand() % intrev32ifbe(is->length));
return 0;
} else {
serverPanic("Unknown set encoding");
}
}
5. 性能分析与优化策略
5.1 内存使用对比
| 场景 | intset 编码 | hashtable 编码 | 内存节省 |
|---|---|---|---|
| 100个小整数 | ~208字节 | ~2400字节 | 91% |
| 500个整数 | ~1008字节 | ~12000字节 | 92% |
| 1000个整数 | ~2008字节 | ~24000字节 | 92% |
| 1000个字符串 | 不适用 | ~48000字节 | - |
5.2 操作性能对比
| 操作类型 | intset 编码 | hashtable 编码 |
|---|---|---|
| SADD | O(n) | O(1) |
| SREM | O(n) | O(1) |
| SISMEMBER | O(log n) | O(1) |
| SCARD | O(1) | O(1) |
| SMEMBERS | O(n) | O(n) |
| 集合运算 | O(n×m) | O(n×m) |
5.3 配置优化建议
针对整数集合的优化:
# 根据实际整数集合大小调整
set-max-intset-entries 1024 # 适当提高阈值
监控与诊断命令:
# 查看Set对象的编码信息
redis-cli object encoding myset
# 监控内存使用情况
redis-cli memory usage myset
# 获取集合基本信息
redis-cli scard myset
6. 实战应用场景
6.1 标签系统实现
class TagSystem:
def __init__(self):
self.r = redis.Redis()
def add_tags_to_item(self, item_id, tags):
# 为物品添加标签
for tag in tags:
# 将物品添加到标签集合
self.r.sadd(f"tag:{tag}", item_id)
# 将标签添加到物品集合
self.r.sadd(f"item:{item_id}:tags", tag)
def get_items_with_tags(self, tags, operation='intersect'):
# 根据标签获取物品
if operation == 'intersect':
# 求交集:同时拥有所有标签的物品
return self.r.sinter([f"tag:{tag}" for tag in tags])
elif operation == 'union':
# 求并集:拥有任一标签的物品
return self.r.sunion([f"tag:{tag}" for tag in tags])
def get_related_tags(self, tag):
# 获取相关标签(经常一起出现的标签)
items = self.r.smembers(f"tag:{tag}")
related_tags = defaultdict(int)
for item_id in items:
item_tags = self.r.smembers(f"item:{item_id}:tags")
for t in item_tags:
if t != tag:
related_tags[t] += 1
return sorted(related_tags.items(), key=lambda x: x[1], reverse=True)
6.2 唯一用户统计
class UniqueUserTracker:
def __init__(self):
self.r = redis.Redis()
def add_user_action(self, user_id, action_type, date=None):
# 记录用户行为
if date is None:
date = datetime.now().strftime("%Y-%m-%d")
# 添加到每日唯一用户集合
self.r.sadd(f"actions:{action_type}:{date}", user_id)
# 添加到全局用户集合
self.r.sadd(f"actions:{action_type}:all", user_id)
def get_daily_unique_users(self, action_type, date):
# 获取每日唯一用户数
return self.r.scard(f"actions:{action_type}:{date}")
def get_unique_users_over_period(self, action_type, start_date, end_date):
# 获取时间段内的唯一用户数
dates = self._generate_date_range(start_date, end_date)
keys = [f"actions:{action_type}:{date}" for date in dates]
# 使用SUNIONSTORE避免多次传输数据
temp_key = f"temp:union:{uuid4()}"
self.r.sunionstore(temp_key, keys)
count = self.r.scard(temp_key)
self.r.delete(temp_key)
return count
6.3 抽奖系统实现
class LotterySystem:
def __init__(self):
self.r = redis.Redis()
def join_lottery(self, user_id, lottery_id):
# 用户参与抽奖
key = f"lottery:{lottery_id}:participants"
return self.r.sadd(key, user_id)
def draw_winners(self, lottery_id, winner_count):
# 抽取获奖者
key = f"lottery:{lottery_id}:participants"
total_participants = self.r.scard(key)
if total_participants < winner_count:
raise ValueError("Not enough participants")
# 随机抽取获奖者
winners = []
for _ in range(winner_count):
# 使用SPOP随机移除并返回一个元素
winner = self.r.spop(key)
if winner:
winners.append(winner)
# 添加到获奖者集合
self.r.sadd(f"lottery:{lottery_id}:winners", winner)
return winners
def get_lottery_stats(self, lottery_id):
# 获取抽奖统计信息
stats = {
'participants': self.r.scard(f"lottery:{lottery_id}:participants"),
'winners': self.r.smembers(f"lottery:{lottery_id}:winners"),
'is_winner': None
}
return stats
7. 高级特性与最佳实践
7.1 大规模集合的优化策略
对于包含大量元素的 Set,可以考虑以下优化策略:
分片存储:
def get_sharded_key(base_key, value, num_shards=100):
# 根据值计算分片键
shard_id = hash(value) % num_shards
return f"{base_key}:shard:{shard_id}"
def sadd_sharded(key, value):
# 分片存储
sharded_key = get_sharded_key(key, value)
return r.sadd(sharded_key, value)
def smembers_sharded(key, num_shards=100):
# 收集所有分片的元素
all_members = set()
for i in range(num_shards):
sharded_key = f"{key}:shard:{i}"
members = r.smembers(sharded_key)
all_members.update(members)
return all_members
7.2 内存优化技巧
定期清理过期数据:
def cleanup_old_sets(pattern, max_age_days=30):
# 清理旧的集合数据
cursor = 0
while True:
cursor, keys = r.scan(cursor, match=pattern, count=100)
if not keys:
break
for key in keys:
# 检查最后访问时间
last_accessed = r.object('idletime', key)
if last_accessed > max_age_days * 24 * 3600:
r.delete(key)
7.3 监控与告警
Set 大小监控:
def monitor_set_sizes(threshold=100000):
# 监控大型集合
cursor = 0
large_sets = []
while True:
cursor, keys = r.scan(cursor, match="*", count=100)
if not keys:
break
for key in keys:
key_type = r.type(key)
if key_type == "set":
size = r.scard(key)
if size > threshold:
large_sets.append((key, size))
return large_sets
8. 总结
Redis Set 类型的底层实现通过 intset 和 hashtable 的双编码策略,在内存效率和操作性能之间取得了出色的平衡。intset 为整数集合提供了极致的内存优化,而 hashtable 则确保了大规模数据集的高效操作。
核心优势:
- 智能编码选择:根据数据特征自动选择最优存储格式
- 内存效率:intset 提供紧凑的整数存储,节省大量内存
- 操作丰富性:支持丰富的集合运算和随机操作
- 性能优异:大部分操作达到 O(1) 或 O(log n) 时间复杂度
最佳实践:
- 对于整数集合,适当调整
set-max-intset-entries参数 - 大规模集合考虑分片存储和定期清理
- 使用集合运算时注意时间复杂度,避免大规模集合的复杂运算
- 监控大型集合的内存使用和访问模式
理解 Set 类型的底层实现机制,有助于开发者在标签系统、唯一计数、抽奖场景等应用中做出更好的设计决策,充分发挥 Redis Set 的性能优势。
Redis Set 类型底层结构图示
1. Set 类型双编码策略图
2. Intset 自动升级机制图
3. Set 操作流程图
4. 集合运算实现图
这些图表从不同角度展示了 Redis Set 类型的底层实现,包括编码策略、intset 升级机制、操作处理和集合运算,希望能够帮助您更好地理解 Set 类型的设计精髓。
本文来自博客园,作者:NeoLshu,转载请注明原文链接:https://www.cnblogs.com/neolshu/p/19120649

 浙公网安备 33010602011771号
浙公网安备 33010602011771号