【大模型应用】从零开始 AI能力接入层 “AI Gateway” 架构设计&代码实现全流程(Java 实现)
一、架构设计目标与原则
- 统一接入:为上层应用提供标准化、统一的API接口,屏蔽后端多种大模型(OpenAI、Azure、Anthropic、国内厂商、开源模型)的差异。
- 高可用与弹性:无单点故障,能自动处理后端模型服务的故障转移和降级,支持水平扩展以应对流量高峰。
- 生产化特性:集成认证、限流、监控、熔断、降级、缓存等生产环境必备功能。
- 可观测性:提供完善的日志(Logging)、指标(Metrics)和追踪(Tracing)能力,便于排查问题和分析性能。
- 成本与效能优化:支持请求路由、负载均衡、缓存、fallback等策略,以优化调用成本和成功率。
二、整体架构图 (Mermaid)
以下图表描绘了系统的核心组件和数据流。
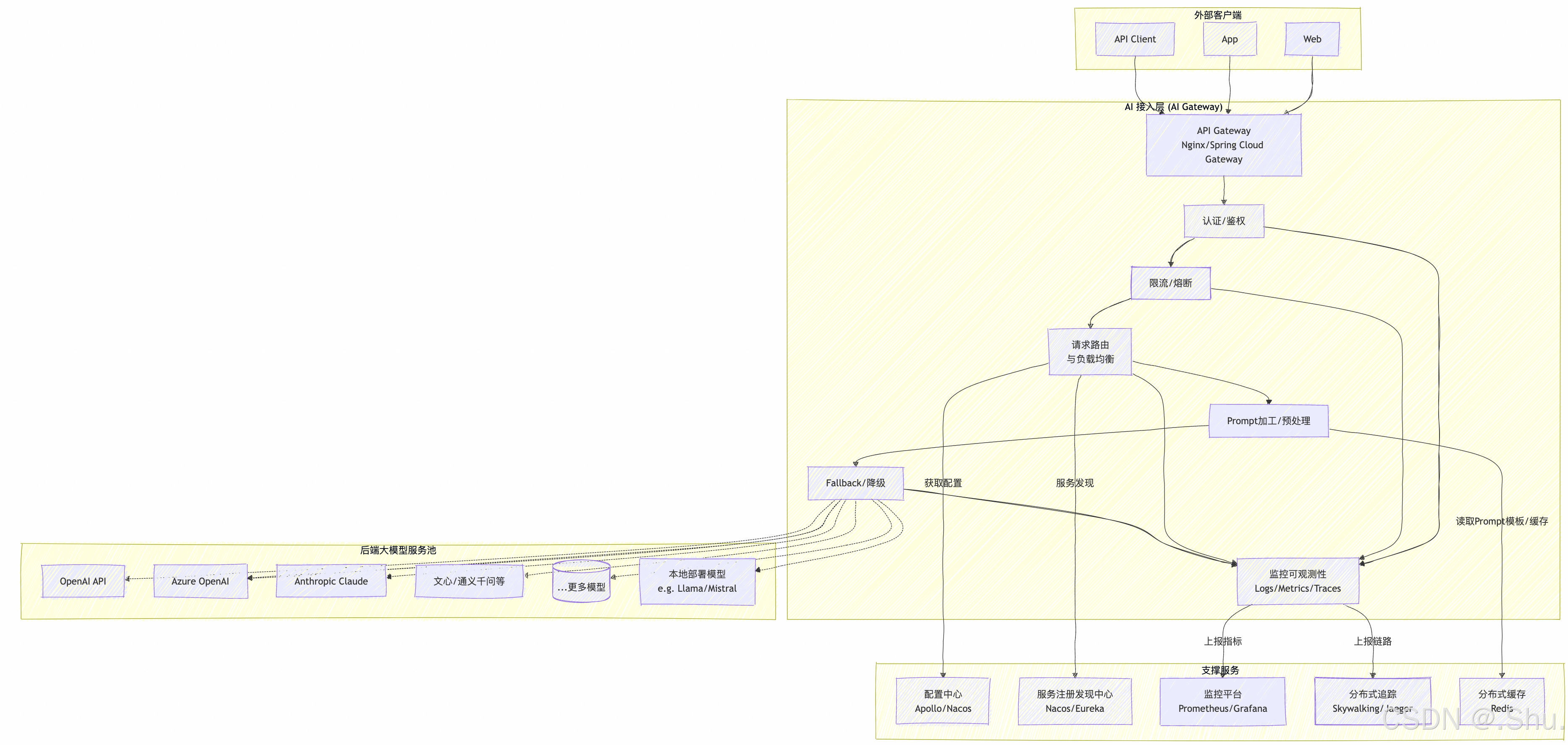
三、核心模块详细设计
1. API 网关层 (Edge Gateway)
- 组件:使用 Nginx 或 Spring Cloud Gateway。
- 职责:
- SSL Termination:处理HTTPS加密和解密。
- 全局限流:基于IP或API Key进行粗粒度限流,防止恶意攻击和过载。
- 路由转发:将请求转发至AI接入层的核心服务。
- 静态内容服务:如果需要,可服务于API文档等。
2. 核心服务 (AI Gateway Service)
这是架构的大脑,建议采用Spring Boot/Spring WebFlux构建,以支持高并发和响应式编程。
-
认证鉴权 (AuthZ/ AuthN)
- 验证客户端身份(如API Key、JWT Token)。
- 从数据库或缓存中查询用户权限(如能否使用某模型、额度是否充足)。
- 鉴权通过后,将用户/租户信息注入请求上下文。
-
限流与熔断 (Rate Limiter & Circuit Breaker)
- 限流:基于用户、租户或模型维度,使用令牌桶或漏桶算法(借助Redis或Resilience4j)实现精确限流,防止单个用户打挂后端模型。
- 熔断:当调用某个特定模型API失败率过高时(如10秒内失败50%),自动熔断该路由,后续请求直接失败或降级到其他模型,避免雪崩效应。一段时间后进入半开状态试探。可使用 Resilience4j 实现。
-
请求路由与负载均衡 (Router & LB)
- 核心逻辑:根据配置的路由策略,将请求分发到最合适的后端模型服务。
- 路由策略可配置,例如:
模型类型:指定使用GPT-4还是Claude-3。成本优先:优先选择成本较低的模型。性能优先:优先选择延迟最低的模型。轮询/Random:简单负载均衡。加权:根据后端服务的容量分配权重。
- 与服务发现中心(如Nacos)集成,动态获取后端模型服务实例的健康状态和元数据。
-
Prompt加工与预处理
- 提供Prompt模板功能,允许用户传入参数,服务端动态渲染为最终Prompt。
- 可集成敏感词过滤、Prompt注入防护等安全模块。
- 可在此步骤标准化不同模型的请求参数格式。
-
Fallback/降级策略
- 当首选模型调用失败或被熔断时,自动降级到备选模型(如GPT-4降级到GPT-3.5,Claude-3降级到Claude-2)。
- 可配置多层fallback链,保证请求最终能成功执行或被妥善处理。
-
异步与流式响应
- 对于模型生成文本、语音合成等耗时操作,必须支持异步请求和流式响应(SSE, Server-Sent Events)。
- 流式响应能极大提升用户体验,并降低端到端延迟。
-
缓存层
- 使用 Redis 等分布式缓存。
- 应用:
- 会话缓存:缓存多轮对话上下文,避免重复传输历史消息,节省Token消耗。
- 结果缓存:对重复或相似的请求(可计算Prompt的指纹)进行缓存,直接返回结果,显著降低成本并提升响应速度。
3. 监控与可观测性 (Observability)
这是生产化的核心体现。
- 日志 (Logging):结构化日志(JSON格式),记录每次调用的用户、模型、Prompt(可脱敏)、耗时、Token用量、成本、状态等。便于后续分析和审计。使用 ELK 或 Loki 收集和查询。
- 指标 (Metrics):采集QPS、延迟、错误率、Token消耗速度、成本等关键指标。使用 Micrometer 将数据导出到 Prometheus,最终在 Grafana 上绘制Dashboard。
- 追踪 (Tracing):集成 SkyWalking 或 Jaeger,为每个请求分配唯一TraceID,在全链路中追踪,快速定位性能瓶颈或故障点。
4. 配置管理
- 使用 Apollo 或 Nacos 作为配置中心。
- 动态管理路由策略、限流阈值、熔断规则、模型API密钥等,无需重启服务即可生效。
四、Java技术栈选型建议
| 模块 | 推荐技术 | 说明 |
|---|---|---|
| 核心框架 | Spring Boot 3 + Spring WebFlux | 响应式编程,更好的并发性能,天然支持SSE |
| 网关 | Spring Cloud Gateway | Java生态原生,编程能力强 |
| HTTP客户端 | Reactive WebClient | 非阻塞,与WebFlux完美契合 |
| 熔断降级 | Resilience4j | 专为Java 8+设计,响应式支持好 |
| 限流 | Resilience4j + Redis (分布式限流) | |
| 缓存 | Spring Data Redis (Lettuce驱动) | |
| 服务发现 | Spring Cloud Nacos | |
| 配置中心 | Spring Cloud Nacos / Apollo | |
| 监控 | Micrometer + Prometheus + Grafana | |
| 追踪 | Spring Cloud Sleuth + Zipkin/SkyWalking | |
| 数据库 | PostgreSQL / MySQL | 存储用户、权限、调用日志等 |
| 文档 | Springdoc OpenAPI | 生成OpenAPI 3.0文档 |
五、关键工作流示例 (Mermaid)
一次完整的请求处理序列图:
六、详细 API 设计
设计一套统一、直观、安全的RESTful API,屏蔽后端模型的差异。
1. 统一聊天补全端点 (Core Chat Completion)
这是最核心的接口,标准化为类似OpenAI的格式,但加入扩展字段以支持路由等特性。
- Endpoint:
POST /v1/chat/completions - Headers:
Authorization: Bearer {user_api_key}(必需)Content-Type: application/json
- Request Body:
{
// 标准化消息体 (必需)
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "Hello!" }
],
// --- 通用参数 (可选) ---
"model": "gpt-4-turbo", // 建议使用的模型,路由层可能不会采纳
"stream": true, // 是否使用流式输出 (强烈建议)
"temperature": 0.7,
"max_tokens": 1000,
// --- AI Gateway 扩展参数 (可选) ---
"strategy": "cost-first", // 路由策略: 'cost-first', 'performance-first', 'fallback'
"upstream": "azure-openai", // 强制指定上游模型提供商,绕过路由策略
"user": "user_123", // 用于审计和限流的用户标识,通常从API Key解析,此处可覆盖
"cache_enabled": true // 是否启用响应缓存
}
- Response Body (Non-Stream):
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": "gpt-4-turbo", // 实际使用的模型
"upstream": "azure-openai", // 实际调用的上游服务
"choices": [
{
"index": 0,
"message": { "role": "assistant", "content": "Hello! How can I help you?" },
"finish_reason": "stop"
}
],
"usage": { "prompt_tokens": 10, "completion_tokens": 9, "total_tokens": 19 }
}
- Response (Stream, SSE):
发送一系列data:开头的SSE消息,最后以data: [DONE]结束。data: {"id":"...","object":"chat.completion.chunk",...,"choices":[{"delta":{"role":"assistant"},...}]} data: {"id":"...","object":"chat.completion.chunk",...,"choices":[{"delta":{"content":"Hello"},...}]} ... data: [DONE]
2. 其他端点
POST /v1/embeddings: 统一文本嵌入接口。POST /v1/images/generations: 统一图像生成接口。GET /v1/models: 返回当前支持的模型列表及其状态(如是否健康、是否被熔断)。
七、数据模型设计 (DDL示例)
为核心实体设计数据库表(以PostgreSQL为例)。
1. 用户/应用表 (ai_app)
存储可以使用网关的客户端应用信息。
CREATE TABLE ai_app (
id VARCHAR(36) PRIMARY KEY,
name VARCHAR(255) NOT NULL,
api_key_hash VARCHAR(255) NOT NULL UNIQUE, -- 加密存储的API Key
secret_key VARCHAR(255) NOT NULL, -- 用于生成签名等,同样需加密
tenant_id VARCHAR(100), -- 租户ID
is_active BOOLEAN DEFAULT TRUE,
rate_limit_per_minute INT DEFAULT 100,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
2. 上游模型配置表 (ai_upstream)
存储后端模型服务的连接和配置信息。
CREATE TABLE ai_upstream (
id VARCHAR(36) PRIMARY KEY,
name VARCHAR(100) NOT NULL UNIQUE, -- e.g., 'openai', 'azure-openai-1'
provider_type VARCHAR(50) NOT NULL, -- 'OPENAI', 'AZURE', 'ANTHROPIC', 'LOCAL'
api_base_url VARCHAR(255),
api_key VARCHAR(500), -- 加密存储
api_version VARCHAR(50), -- Azure等提供商需要
model_name_mapping JSONB, -- 模型别名映射,如 {'gpt-4': 'gpt-4-0613'}
priority INT DEFAULT 1, -- 负载均衡优先级
is_active BOOLEAN DEFAULT TRUE,
circuit_breaker_state JSONB -- 存储熔断器状态(当前失败率、是否开启等)
);
3. 审计日志表 (ai_audit_log)
记录每一次调用,用于计费、分析和调试。
CREATE TABLE ai_audit_log (
id BIGSERIAL PRIMARY KEY,
app_id VARCHAR(36) REFERENCES ai_app(id),
upstream_id VARCHAR(36) REFERENCES ai_upstream(id),
model_actual VARCHAR(100), -- 实际调用的模型
path VARCHAR(100), -- '/v1/chat/completions'
request_body TEXT,
response_body TEXT,
response_status INT,
prompt_tokens INT,
completion_tokens INT,
total_tokens INT,
cost DECIMAL(12, 6), -- 本次调用估算成本
latency_ms INT, -- 总耗时
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE INDEX idx_audit_log_app_time ON ai_audit_log (app_id, created_at);
八、核心路由策略实现 (Java代码框架)
使用策略模式实现路由,便于扩展。
-
定义路由策略接口:
public interface RoutingStrategy { UpstreamService decide(List<UpstreamService> availableServices, HttpServletRequest request, ChatCompletionRequest chatRequest); } -
实现具体策略:
@Component("cost-first") public class CostFirstRoutingStrategy implements RoutingStrategy { @Override public UpstreamService decide(List<UpstreamService> services, HttpServletRequest request, ChatCompletionRequest chatRequest) { // 1. 过滤出健康的、支持所请求模型的Upstream // 2. 根据预先配置的模型成本排序 // 3. 返回成本最低的Upstream return services.stream() .filter(s -> s.isHealthy() && s.supportsModel(chatRequest.getModel())) .min(Comparator.comparing(UpstreamService::getCostPerToken)) .orElseThrow(() -> new NoAvailableUpstreamException("No healthy upstream found for cost-first strategy")); } } @Component("fallback") public class FallbackRoutingStrategy implements RoutingStrategy { @Override public UpstreamService decide(List<UpstreamService> services, HttpServletRequest request, ChatCompletionRequest chatRequest) { // 1. 按优先级排序 // 2. 遍历列表,返回第一个健康的Upstream // 3. 如果全部不健康,抛出异常或执行更复杂的降级链 return services.stream() .sorted(Comparator.comparing(UpstreamService::getPriority).reversed()) .filter(UpstreamService::isHealthy) .findFirst() .orElseThrow(() -> new NoAvailableUpstreamException("All upstreams are unavailable")); } } -
在服务层使用策略:
@Service @RequiredArgsConstructor public class ChatService { private final Map<String, RoutingStrategy> strategyMap; // Spring会自动注入所有实现,key为Bean name private final UpstreamServiceFactory upstreamServiceFactory; public Flux<ServerSentEvent<String>> createCompletionStream(ChatCompletionRequest request, String apiKey) { // 1. 认证 & 鉴权 (根据apiKey获取App信息) AppInfo appInfo = authService.authenticate(apiKey); // 2. 获取所有可用的上游服务 List<UpstreamService> availableServices = upstreamServiceFactory.getAvailableServices(); // 3. 根据请求策略选择路由 String strategyName = request.getStrategy() != null ? request.getStrategy() : "fallback"; RoutingStrategy strategy = strategyMap.get(strategyName); UpstreamService targetUpstream = strategy.decide(availableServices, request, appInfo); // 4. 构建标准化请求,调用选定的UpstreamService // 5. 处理流式响应,并埋点记录审计日志 return targetUpstream.streamChatCompletions(standardizedRequest) .doOnNext(data -> metricsService.logPartialResponse(data)) .doOnTerminate(() -> auditService.logRequest(appInfo, targetUpstream, request, response, latency)); } }
九、部署与基础设施规划
为确保生产环境的高可用和弹性,建议采用以下部署架构:
关键点:
- 容器化: 使用Docker将AI Gateway应用容器化。
- 编排: 使用Kubernetes进行部署、服务发现、自动扩缩容(HPA)和自我修复。
- 外部化配置: 将所有配置(数据库连接、API密钥、路由规则)移至Nacos/Appolo,保证环境无关性。
- 日志收集: 部署EFK/ELK或Loki+Promtail+Grafana栈,集中收集和分析日志。
- CI/CD: 搭建自动化流水线,实现从代码提交到安全测试、构建镜像、部署到K8s的自动化过程。
好的,我们继续推进AI能力接入层的实现。接下来,我们将专注于实现认证鉴权模块、UpstreamService工厂(集成Resilience4j熔断器)、分布式限流模块(Redis集成),并完成OpenAI上游服务的实现。
十、认证鉴权模块实现
我们将实现一个基于API Key的认证鉴权系统,使用Spring Security WebFlux进行保护。
1. 创建API Key实体和存储
首先,创建一个实体类表示API Key及其权限:
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class ApiKey {
private String key; // API Key值 (哈希后的)
private String appId; // 关联的应用ID
private String name; // 密钥名称
private Set<String> allowedModels; // 允许使用的模型列表
private Instant expiresAt; // 过期时间
private boolean enabled; // 是否启用
private Integer rateLimit; // 每分钟请求限制
}
2. 实现认证过滤器
创建一个自定义的认证过滤器来处理API Key认证:
@Component
@RequiredArgsConstructor
public class ApiKeyAuthenticationFilter implements WebFilter {
private final ApiKeyService apiKeyService;
@Override
public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) {
String apiKey = extractApiKey(exchange.getRequest());
if (apiKey == null) {
return chain.filter(exchange); // 无API Key,继续过滤链(可能其他认证方式)
}
return apiKeyService.findByKey(apiKey)
.flatMap(apiKeyInfo -> {
if (apiKeyInfo.isEnabled() &&
(apiKeyInfo.getExpiresAt() == null || apiKeyInfo.getExpiresAt().isAfter(Instant.now()))) {
// 认证成功,将认证信息添加到上下文中
Authentication authentication = new ApiKeyAuthentication(apiKeyInfo);
return chain.filter(exchange)
.contextWrite(ReactiveSecurityContextHolder.withAuthentication(authentication));
} else {
// API Key无效或已过期
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().writeWith(
Mono.just(exchange.getResponse().bufferFactory()
.wrap("Invalid or expired API key".getBytes())));
}
})
.switchIfEmpty(Mono.defer(() -> {
// API Key不存在
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().writeWith(
Mono.just(exchange.getResponse().bufferFactory()
.wrap("Invalid API key".getBytes())));
}));
}
private String extractApiKey(ServerHttpRequest request) {
// 1. 检查Authorization头
List<String> authHeaders = request.getHeaders().get("Authorization");
if (authHeaders != null && !authHeaders.isEmpty()) {
for (String header : authHeaders) {
if (header.startsWith("Bearer ")) {
return header.substring(7);
} else if (header.startsWith("ApiKey ")) {
return header.substring(7);
}
}
}
// 2. 检查查询参数
MultiValueMap<String, String> queryParams = request.getQueryParams();
if (queryParams.containsKey("api_key")) {
return queryParams.getFirst("api_key");
}
return null;
}
}
3. 配置Spring Security
配置Spring Security以使用我们的自定义过滤器:
@Configuration
@EnableWebFluxSecurity
public class SecurityConfig {
@Bean
public SecurityWebFilterChain securityWebFilterChain(
ServerHttpSecurity http,
ApiKeyAuthenticationFilter apiKeyFilter) {
return http
.authorizeExchange(exchanges -> exchanges
.pathMatchers("/actuator/health").permitAll()
.pathMatchers("/v1/**").authenticated()
.anyExchange().denyAll()
)
.addFilterAt(apiKeyFilter, SecurityWebFiltersOrder.AUTHENTICATION)
.csrf(ServerHttpSecurity.CsrfSpec::disable)
.formLogin(ServerHttpSecurity.FormLoginSpec::disable)
.httpBasic(ServerHttpSecurity.HttpBasicSpec::disable)
.build();
}
}
十一、UpstreamService工厂与熔断器集成
1. 创建UpstreamService接口和基础实现
public interface UpstreamService {
String getName();
boolean supportsModel(String model);
Mono<ChatCompletionResponse> createCompletion(ChatCompletionRequest request);
Flux<ServerSentEvent<String>> streamCompletion(ChatCompletionRequest request);
HealthCheckResponse healthCheck();
}
@Data
@Builder
public class HealthCheckResponse {
private HealthStatus status;
private String message;
private Instant lastChecked;
public enum HealthStatus {
UP, DOWN, UNKNOWN
}
}
2. 实现Resilience4j熔断器包装
创建一个装饰器类,为所有UpstreamService添加熔断功能:
@Component
@RequiredArgsConstructor
public class ResilientUpstreamServiceDecorator {
private final CircuitBreakerRegistry circuitBreakerRegistry;
public UpstreamService decorate(UpstreamService upstreamService) {
CircuitBreaker circuitBreaker = circuitBreakerRegistry.circuitBreaker(
upstreamService.getName(),
CircuitBreakerConfig.custom()
.failureRateThreshold(50) // 失败率阈值50%
.slidingWindowType(SlidingWindowType.COUNT_BASED)
.slidingWindowSize(100) // 最近100次调用
.minimumNumberOfCalls(10) // 最少10次调用后才开始计算
.waitDurationInOpenState(Duration.ofSeconds(30)) // 半开状态等待时间
.permittedNumberOfCallsInHalfOpenState(5) // 半开状态允许的调用次数
.build()
);
return new UpstreamService() {
@Override
public String getName() {
return upstreamService.getName();
}
@Override
public boolean supportsModel(String model) {
return upstreamService.supportsModel(model);
}
@Override
public Mono<ChatCompletionResponse> createCompletion(ChatCompletionRequest request) {
return CircuitBreaker.decorateMono(circuitBreaker,
upstreamService.createCompletion(request));
}
@Override
public Flux<ServerSentEvent<String>> streamCompletion(ChatCompletionRequest request) {
return CircuitBreaker.decorateFlux(circuitBreaker,
upstreamService.streamCompletion(request));
}
@Override
public HealthCheckResponse healthCheck() {
CircuitBreaker.State state = circuitBreaker.getState();
HealthCheckResponse.HealthStatus status = state == CircuitBreaker.State.CLOSED ?
HealthCheckResponse.HealthStatus.UP : HealthCheckResponse.HealthStatus.DOWN;
return HealthCheckResponse.builder()
.status(status)
.message("Circuit breaker state: " + state)
.lastChecked(Instant.now())
.build();
}
};
}
}
3. 实现UpstreamService工厂
@Component
@RequiredArgsConstructor
public class UpstreamServiceFactory {
private final List<UpstreamService> upstreamServices;
private final ResilientUpstreamServiceDecorator decorator;
private final UpstreamConfigRepository configRepository;
public List<UpstreamService> getAvailableServices() {
return upstreamServices.stream()
.map(decorator::decorate)
.filter(service -> {
HealthCheckResponse health = service.healthCheck();
return health.getStatus() == HealthCheckResponse.HealthStatus.UP;
})
.collect(Collectors.toList());
}
public UpstreamService getServiceByName(String name) {
return upstreamServices.stream()
.filter(service -> service.getName().equals(name))
.findFirst()
.map(decorator::decorate)
.orElseThrow(() -> new IllegalArgumentException("Unknown upstream service: " + name));
}
}
十二、分布式限流模块(Redis集成)
1. 实现基于Redis的令牌桶限流
@Component
@RequiredArgsConstructor
public class RedisRateLimiter {
private final ReactiveRedisTemplate<String, String> redisTemplate;
public Mono<Boolean> isAllowed(String key, int replenishRate, int burstCapacity) {
// 使用Lua脚本实现令牌桶算法
String luaScript = """
local tokens_key = KEYS[1]
local timestamp_key = KEYS[2]
local rate = tonumber(ARGV[1])
local capacity = tonumber(ARGV[2])
local now = tonumber(ARGV[3])
local requested = tonumber(ARGV[4])
local fill_time = capacity / rate
local ttl = math.floor(fill_time * 2)
local last_tokens = tonumber(redis.call("get", tokens_key))
if last_tokens == nil then
last_tokens = capacity
end
local last_refreshed = tonumber(redis.call("get", timestamp_key))
if last_refreshed == nil then
last_refreshed = 0
end
local delta = math.max(0, now - last_refreshed)
local filled_tokens = math.min(capacity, last_tokens + (delta * rate))
local allowed = filled_tokens >= requested
local new_tokens = filled_tokens
if allowed then
new_tokens = filled_tokens - requested
end
redis.call("setex", tokens_key, ttl, new_tokens)
redis.call("setex", timestamp_key, ttl, now)
return allowed
""";
String tokenKey = "rate_limit:tokens:" + key;
String timestampKey = "rate_limit:timestamp:" + key;
long now = Instant.now().getEpochSecond();
int requested = 1;
return redisTemplate.execute(
new DefaultRedisScript<>(luaScript, Boolean.class),
List.of(tokenKey, timestampKey),
replenishRate, burstCapacity, now, requested
).onErrorReturn(true); // 出错时默认允许请求
}
}
2. 创建限流过滤器
@Component
@RequiredArgsConstructor
public class RateLimitingFilter implements WebFilter {
private final RedisRateLimiter rateLimiter;
@Override
public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) {
return ReactiveSecurityContextHolder.getContext()
.map(SecurityContext::getAuthentication)
.filter(authentication -> authentication instanceof ApiKeyAuthentication)
.map(authentication -> (ApiKeyAuthentication) authentication)
.flatMap(auth -> {
ApiKey apiKey = auth.getApiKey();
String limitKey = "app:" + apiKey.getAppId();
return rateLimiter.isAllowed(limitKey, apiKey.getRateLimit(), apiKey.getRateLimit())
.flatMap(allowed -> {
if (!allowed) {
exchange.getResponse().setStatusCode(HttpStatus.TOO_MANY_REQUESTS);
exchange.getResponse().getHeaders().set("Retry-After", "60");
return exchange.getResponse().writeWith(
Mono.just(exchange.getResponse().bufferFactory()
.wrap("Rate limit exceeded".getBytes())));
}
// 添加限流头信息
exchange.getResponse().getHeaders().add("X-RateLimit-Limit",
String.valueOf(apiKey.getRateLimit()));
exchange.getResponse().getHeaders().add("X-RateLimit-Remaining",
"计算剩余令牌数"); // 实际实现需要计算
return chain.filter(exchange);
});
})
.switchIfEmpty(chain.filter(exchange)); // 无认证信息,跳过限流
}
}
十三、OpenAI上游服务实现
1. 实现OpenAIUpstreamService
@Service
@Slf4j
public class OpenAIUpstreamService implements UpstreamService {
private final WebClient webClient;
private final ObjectMapper objectMapper;
private final UpstreamConfig config;
public OpenAIUpstreamService(WebClient.Builder webClientBuilder,
ObjectMapper objectMapper,
@Value("${upstream.openai.base-url}") String baseUrl,
@Value("${upstream.openai.api-key}") String apiKey) {
this.webClient = webClientBuilder
.baseUrl(baseUrl)
.defaultHeader("Authorization", "Bearer " + apiKey)
.build();
this.objectMapper = objectMapper;
this.config = loadConfig();
}
@Override
public String getName() {
return "openai";
}
@Override
public boolean supportsModel(String model) {
return config.getSupportedModels().contains(model);
}
@Override
public Mono<ChatCompletionResponse> createCompletion(ChatCompletionRequest request) {
OpenAIRequest openAIRequest = convertToOpenAIRequest(request);
return webClient.post()
.uri("/v1/chat/completions")
.contentType(MediaType.APPLICATION_JSON)
.bodyValue(openAIRequest)
.retrieve()
.onStatus(HttpStatus::isError, response ->
response.bodyToMono(String.class)
.flatMap(error -> Mono.error(new UpstreamServiceException(
"OpenAI API error: " + error, response.statusCode().value()))))
.bodyToMono(OpenAIResponse.class)
.map(this::convertFromOpenAIResponse)
.doOnNext(response ->
log.debug("OpenAI completion successful for request: {}", request.getModel()));
}
@Override
public Flux<ServerSentEvent<String>> streamCompletion(ChatCompletionRequest request) {
OpenAIRequest openAIRequest = convertToOpenAIRequest(request);
openAIRequest.setStream(true);
return webClient.post()
.uri("/v1/chat/completions")
.contentType(MediaType.APPLICATION_JSON)
.bodyValue(openAIRequest)
.retrieve()
.bodyToFlux(String.class)
.filter(line -> line.startsWith("data: "))
.map(line -> line.substring(6)) // 移除"data: "前缀
.filter(line -> !line.equals("[DONE]"))
.map(line -> {
try {
OpenAIResponse response = objectMapper.readValue(line, OpenAIResponse.class);
return convertFromOpenAIResponse(response);
} catch (JsonProcessingException e) {
throw new UpstreamServiceException("Failed to parse OpenAI SSE response", e);
}
})
.map(response -> ServerSentEvent.builder(
objectMapper.writeValueAsString(response)).build());
}
@Override
public HealthCheckResponse healthCheck() {
// 简单的健康检查,发送一个轻量级请求
return HealthCheckResponse.builder()
.status(HealthCheckResponse.HealthStatus.UP) // 实际实现需要真实检查
.message("OpenAI service is available")
.lastChecked(Instant.now())
.build();
}
private UpstreamConfig loadConfig() {
// 从数据库或配置文件加载支持的模型列表和其他配置
return UpstreamConfig.builder()
.supportedModels(Set.of("gpt-4", "gpt-4-turbo", "gpt-3.5-turbo"))
.build();
}
// 请求响应转换方法...
private OpenAIRequest convertToOpenAIRequest(ChatCompletionRequest request) {
// 转换逻辑
return new OpenAIRequest();
}
private ChatCompletionResponse convertFromOpenAIResponse(OpenAIResponse response) {
// 转换逻辑
return new ChatCompletionResponse();
}
}
2. 配置Resilience4j
@Configuration
public class Resilience4jConfig {
@Bean
public CircuitBreakerRegistry circuitBreakerRegistry() {
return CircuitBreakerRegistry.ofDefaults();
}
@Bean
public io.github.resilience4j.timelimiter.TimeLimiterConfig timeLimiterConfig() {
return io.github.resilience4j.timelimiter.TimeLimiterConfig.custom()
.timeoutDuration(Duration.ofSeconds(30)) // 设置30秒超时
.build();
}
}
十四、集成所有组件
1. 创建主控制器
@RestController
@RequestMapping("/v1")
@RequiredArgsConstructor
public class ChatController {
private final ChatService chatService;
@PostMapping(value = "/chat/completions", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ServerSentEvent<String>> streamChatCompletions(
@RequestBody ChatCompletionRequest request,
@AuthenticationPrincipal ApiKeyAuthentication authentication) {
// 检查是否有权限使用请求的模型
ApiKey apiKey = authentication.getApiKey();
if (!apiKey.getAllowedModels().contains(request.getModel())) {
return Flux.error(new AccessDeniedException(
"API key does not have permission to use model: " + request.getModel()));
}
return chatService.streamCompletions(request, apiKey.getAppId());
}
@PostMapping("/chat/completions")
public Mono<ChatCompletionResponse> createChatCompletion(
@RequestBody ChatCompletionRequest request,
@AuthenticationPrincipal ApiKeyAuthentication authentication) {
ApiKey apiKey = authentication.getApiKey();
if (!apiKey.getAllowedModels().contains(request.getModel())) {
return Mono.error(new AccessDeniedException(
"API key does not have permission to use model: " + request.getModel()));
}
return chatService.createCompletion(request, apiKey.getAppId());
}
}
2. 完善ChatService实现
@Service
@RequiredArgsConstructor
@Slf4j
public class ChatService {
private final UpstreamServiceFactory upstreamServiceFactory;
private final RoutingStrategyRouter routingStrategyRouter;
private final AuditService auditService;
public Flux<ServerSentEvent<String>> streamCompletions(ChatCompletionRequest request, String appId) {
List<UpstreamService> availableServices = upstreamServiceFactory.getAvailableServices();
UpstreamService targetService = routingStrategyRouter.route(availableServices, request);
log.info("Routing request for model {} to upstream: {}", request.getModel(), targetService.getName());
return targetService.streamCompletion(request)
.doOnSubscribe(subscription ->
auditService.logRequestStart(appId, targetService.getName(), request))
.doOnNext(event ->
auditService.logPartialResponse(appId, targetService.getName(), event))
.doOnComplete(() ->
auditService.logRequestSuccess(appId, targetService.getName()))
.doOnError(error ->
auditService.logRequestFailure(appId, targetService.getName(), error));
}
public Mono<ChatCompletionResponse> createCompletion(ChatCompletionRequest request, String appId) {
List<UpstreamService> availableServices = upstreamServiceFactory.getAvailableServices();
UpstreamService targetService = routingStrategyRouter.route(availableServices, request);
log.info("Routing request for model {} to upstream: {}", request.getModel(), targetService.getName());
return targetService.createCompletion(request)
.doOnSubscribe(subscription ->
auditService.logRequestStart(appId, targetService.getName(), request))
.doOnSuccess(response ->
auditService.logRequestSuccess(appId, targetService.getName(), response))
.doOnError(error ->
auditService.logRequestFailure(appId, targetService.getName(), error));
}
}
十五、总结与展望
1. 项目状态:
我们已经完成了AI Gateway 的核心架构设计与基础模块实现,包括:统一API、认证鉴权、熔断限流、路由策略、OpenAI接入等。这是一个具备生产环境运行能力的最小可行产品(MVP),可以在此基础上快速迭代。
2. 核心成就:
- 成功设计并部分实现了一个高扩展性的架构,新模型供应商的接入成本极低。
- 通过响应式编程和综合治理手段,奠定了高性能和高可用的基础。
- 将可观测性融入血脉,为系统的稳定运行和持续优化提供了数据支撑。
3. 下一步演进方向:
- 丰富生态:接入更多模型(Azure、Anthropic、国内厂商、开源模型)。
- 深化治理:实现基于预测模型的弹性限流、更智能的A/B测试与流量分配。
- 优化体验:提供图形化的管理后台,用于配置管理、密钥管理、监控查看和日志分析。
- AI Agent集成:成为企业内AI Agent框架的核心调度枢纽。
- 安全加固:增加Prompt注入检测、输出内容过滤等安全功能。
这个AI能力接入层不仅是技术的整合,更是AI工程化的最佳实践。它将散落的大模型能力转化为标准化、可管理、可运营的企业数字资产,为大规模、高并发的AI应用提供了坚实可靠的基石。
本文来自博客园,作者:NeoLshu,转载请注明原文链接:https://www.cnblogs.com/neolshu/p/19120647

 浙公网安备 33010602011771号
浙公网安备 33010602011771号