
Spark DataFrame操作
DataFrame在Spark 1.3时加入,其前身是Spark 1中的SQL Context、Streaming Context、Hive Context等对象,它类似于关系数据库中的表,是行和列进行组织数据。
DataFrame相当是一张二维表,可以使用SparkSession中的各种函数来创建。
按照和上小节对Spark RDD的方式进行对Spark DataFrame进行说明,且由于Spark DataFrame是在Spark 2中添加的,
通过使用SparkSession进行创建,所以通过以下的步骤进行演示。
操作的对应的视频如下,在腾讯课堂可免费查看所有的视频与下载简介资料个人大数据平台的搭建与学习实践-PySpark-学习视频教程-腾讯课堂 (qq.com)
1-打开官方文档和JupyterLab
PySpark中SparkSession类的文档:https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.SparkSession.html
通过Jupyter-lab命令打开jupyter notebook。
2-创建SparkSession对象
在5-2节中已经对SparkSession的方式进行了简单的演示,它主要是通过类中Builder类型属性进行构建SparkSession实例的。
如果想深入的了解Builder,可以通过文档上的源码链接跳转到源码进行查看。
import findspark findspark.init() from pyspark.sql import SparkSession spark = SparkSession\ .builder\ .master('local')\ .appName("DataFrame")\ .getOrCreate() #getOrCreate获取或创建
关于Builder属性的源码
class Builder(object): """Builder for :class:`SparkSession`. """ _lock = RLock() _options = {} _sc = None def config(self, key=None, value=None, conf=None): """Sets a config option. Options set using this method are automatically propagated to both :class:`SparkConf` and :class:`SparkSession`'s own configuration. .. versionadded:: 2.0.0 Parameters ---------- key : str, optional a key name string for configuration property value : str, optional a value for configuration property conf : :class:`SparkConf`, optional an instance of :class:`SparkConf` .....
3-通过SparkSession对象读取数据生产DataFrame
通过上一步创建了SparkSession对象spark后,就可以它来创建Spark DataFrame数据类型了,通过函数是createDataFrame(data[, schema, …])。
文档中对函数中的data参数说明:可以是 RDD, list or pandas.DataFrame。或使用read属性进行读取数据,这部分知识点在Spark SQL小节中说明。
拷贝文档下载的实例代码进行执行,调用createDataFrame函数创建DataFrame数据的语句,注意语句中使用StructField定义表模型。
而StructType在函数说明中也提及了,可以调整到对应的文档中查看。StructType -- > StructType --> StructField
from pyspark.sql.types import * schema = StructType([ StructField("name", StringType(), True), StructField("age", IntegerType(), True)]) df3 = spark.createDataFrame(rdd, schema) df3.collect() [Row(name='Alice', age=1)]
4-对DataFrame数据对象操作
可以查看《Python大数据分析从入门到精通》中的PySpark DataFrame中的API示例。
打开DataFrame Python文档:https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.DataFrame.html
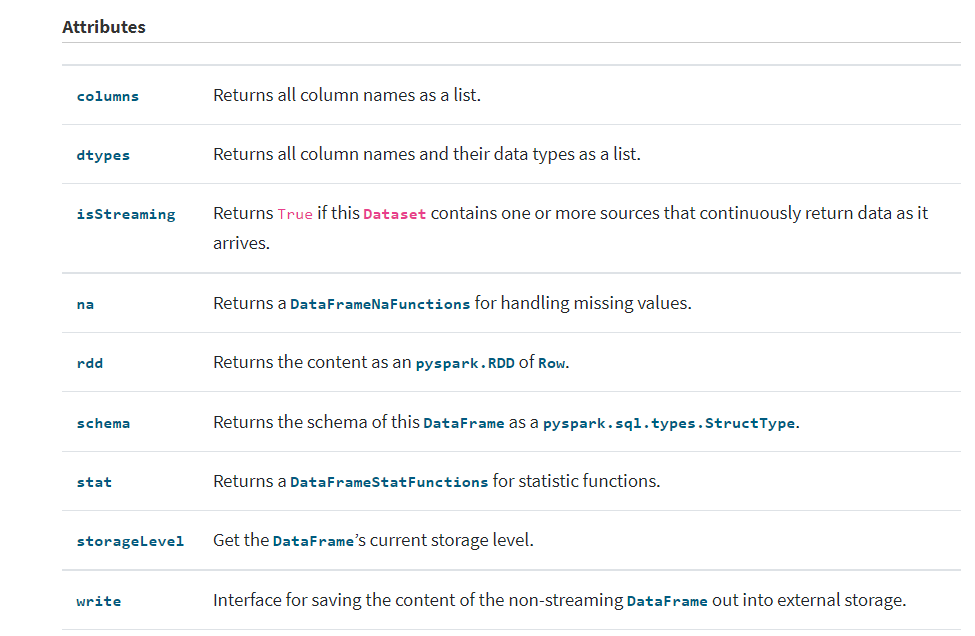
DataFrame的属性
功能函数分类
关联处理函数-将两个DataFrame进行连接。类似SQL中的关联操作

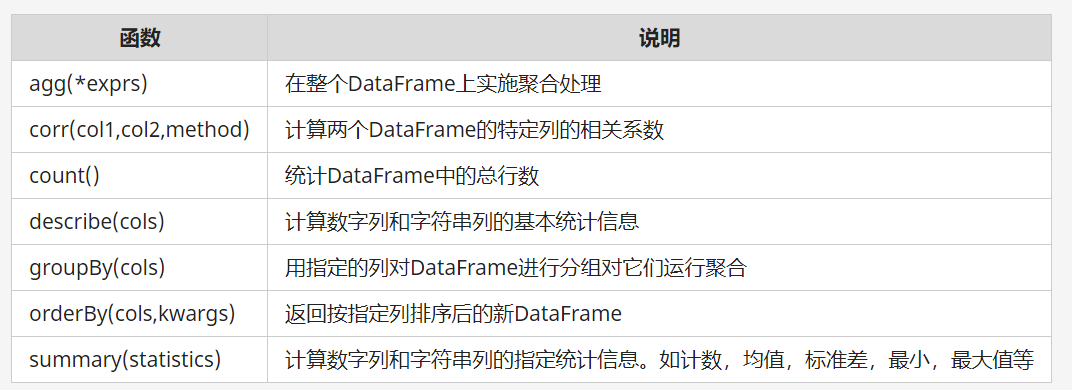
排序统计

 浙公网安备 33010602011771号
浙公网安备 33010602011771号