深度神经网络简述与Capsule介绍
本人最近初学Hinton大神的论文《Dynamic Routing Between Capsules 》,对深度神经网络的内容进行了简要总结,将观看“从传统神经网络的角度解读Capsule”视频的内容做了笔记。感谢网络资源,让我学习到很多知识。以后会有更新。
出处: http://www.cnblogs.com/nenya33/p/8079861.html
转载:欢迎转载,但须保留此段声明,并在文章中给出原文连接;否则必究法律责任
==============================================我是分割线==============================================
DNN = Deep Neural Network
1. 领军人物

2. 全连接神经网络

输入数据经过网络,执行一系列的操作后,找到输出类概率,与真实标签比较,计算出误差值,然后用误差计算梯度,之后梯度会告诉我们如何在反向传播过程中更新权重。
BP算法:

- 是一个用来求解目标函数关于多层网络权值梯度的反向传播算法。
- 求导的链式法则的具体应用。
- 指导机器如何从前一层获取误差而改变本层的内部参数,这些内部参数可以用于计算表示。
3. 深层结构的启发
(1)深度不够,对于大的输入,每个隐藏层的节点太多,泛化能力差
(2)人脑是深层结构
(3)认知过程似乎是深度的(人脑形成idea是层级的;人第一次学习简单的concepts后会将其组合形成更抽象的表征)
4.从深度上来看神经网络的进化史
CNN更易于训练并且比全连接的神经网络的泛化性能更好,被计算机视觉团队广泛使用。
关于卷积层形象化的解释:像一个方形手电筒,照亮图像上的每个像素,找到图像中最相关的部分,然后做乘积、加和运算,最终输出一个特征图,特征图表示的是从图像中学习到的特征。在得到了特征图后,会用到非线性激活函数,作用是使网络既能学习线性特征,又能学习非线性特征,用ReLU函数而不是其他函数的原因在于,能够解决BP过程中梯度消失的问题。
关于池化层的解释:假设有一个像素矩阵,有很多数字0-255,以max pooling为例,它做的就是把这些数字划分成小块,从每个小块中取出最大的像素值,向前传播,这样得到更小的新的像素矩阵,用于前向传播,加速,减少了训练的时间。
LeNet 1986

conv-pooling-conv-pooling
AlexNet 2012 8层
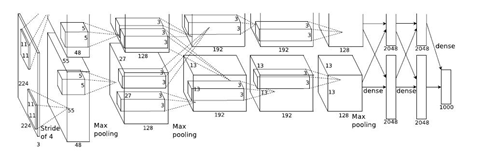
conv-pooling-conv-pooling-conv-conv-conv-pooling
VGG-Net 2014 16-19层
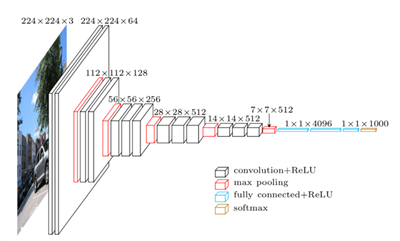
2convs- pooling-2convs-pooling-3convs-pooling-3convs-pooling-3convs-pooling
GoogLeNet 2014 22层
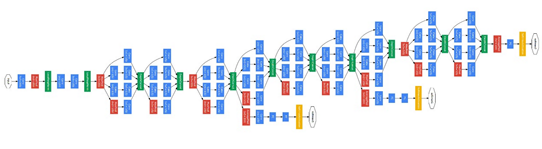
用更多的卷积,更深的网络可以得到更好的模型
ResNet 2015 152层

图中为34层
历届ILSVRC比赛代表性模型的成绩及其神经网络深度

参考
1. Deep learning. Yann LeCun, Yoshua Bengio& Geoffrey Hinton
2. http://blog.csdn.net/xbinworld/article/details/45619685
3. http://www.iqiyi.com/w_19rv08vrlp.html Siraj Raval(简洁直观)
4. https://www.leiphone.com/news/201702/dgpHuriVJHTPqqtT.html 把CNN总结得很好
Capsule
1. Who?
“神经网络之父”Geoffrey Hinton提出Capsule

2. Why?为什么要提出Capsule
2017年8月17日,“神经网络之父”Geoffrey Hinton加拿大多伦多菲尔兹研究所开讲,主题为《What is wrong with convolutional neural nets?》,指出了神经网络存在的问题。


在Hinton看来,标准神经网络存在如下问题:
(a)结构层次太少。只有神经元、层、网络三个层级;
(b)我们需要把每一层的神经元组成capsules,capsule可以做大量内部计算,然后输出压缩的结果。(灵感来自于大脑皮层中的微柱状体mini-coulumn)

Capsule表示什么呢?
(a)每个capsule表征检测类型的多维实体的实例化参数和存在性;
(b)例如,在视觉路径中,capsule检测物体或者部分物体的特定类型;
(c)一个capsule输出两部分:物体呈现出某种类型的概率;物体的广义姿态,包括位置、方向、大小、形变、速率和颜色等。

Capsule的作用是同步过滤:
(a)典型的capsule接收底层capsule的多维预测向量,寻找紧密的预测群(可以理解为类别);
(b)如果找到了一个紧密的群,capsule会输出:这个类型存在的实体在这个domain(领域)的较高概率,以及这个簇的中心,这个中心就是那个实体的广义姿态。
(c)善于过滤噪声,因为高维一致性不会偶然发生。capsule比通常的神经元更好。

Yann LeCun和绝大多数人做物体识别的现有方式分为以下几种:
(a)卷积网络使用多层的学习好的特征检测器(好);
(b)在卷积网络中,特征检测器是局部的,每种类型的检测器被复制到整个空间中(好);
(c)在卷积网络中,层次越高,特征检测器的空间域越大(好);
(d) 特征提取层与下采样层交叉存取,下采样层对同类型的相邻特征检测器的输出进行了池化(差)。

将复制的特征检测器的输出结合的动机和原因是什么?
(a)池化在每一层级带来了少量的平移不变性:舍去了最活跃的特征检测器的精确位置;如果pool之间重叠地更多或者特征对其他特征的相对位置进行了编码,可能没什么问题。
(b) 池化减少了特征提取的下一层的输入数量。这使得我们可以在下一层有更多特征类型。

池化存在四个主要的争论:
(a)池化与图形感知心理学不切合。它并没有解释为什么我们给物体安排内在的坐标框架,以及有效的原因。
(b)池化解决了错误的问题。我们想要的是均等性而不是不变性,是解开而不是丢弃。
(c)池化未能利用潜在的线性结构。它没有利用可完美处理图像中最大变动来源的自然线性流形。
(d)池化很不擅长处理动态路由。我们需要把输入的每一部分路由到知道如何处理它的神经元上去。发现最佳的选路等同于解析图像。
……
Hinton的这种精神也获得了同行的肯定:工具都不是永恒的。
3. When?
2017年10月26日
事实上,在2011年Hinton在论文Transforming auto-encoders中引入过Capsule单元。
(Geoffrey E Hinton, Alex Krizhevsky, and Sida D Wang. Transforming auto-encoders. In Artificial Neural Networks and Machine Learning–ICANN 2011, pp. 44–51. Springer, 2011.)
4. Where?
https://arxiv.org/abs/1710.09829
5. What?Capsule究竟是什么

来自论文摘要:
A capsule is a group of neurons whose activity vector represents the instantiation parameters of a specific type of entity such as an object or object part. We use the length of the activity vector to represent the probability that the entity exists and its orientation to represent the instantiation parameters. Active capsules at one level make predictions, via transformation matrices, for the instantiation parameters of higher-level capsules. When multiple predictions agree, a higher level capsule becomes active.
Capsule是一组神经元,它的激活向量表示物体或者物体部分的特定类型的实例参数。用激活向量的长度表示物体存在的概率,用方向表示实例参数。一个层级的激活capsule做预测,通过变换矩阵得到更高层级capsule的实例参数。当多个预测一致时,更高层级的capsule被激活。
6. How?从传统神经网络角度解读Capsule模型
(1)Capsule概念提出的背景

CNN可能会把右上方左图也当做人脸,因为容易在pooling过程中丢失空间上的相关性,目标是得到右下方的结果。想要详细了解capsule的提出背景,可以看Hinton的报告和论文。
实验发现深度神经网络的另外一个缺点

(2)Capsule模型与传统神经元的比较

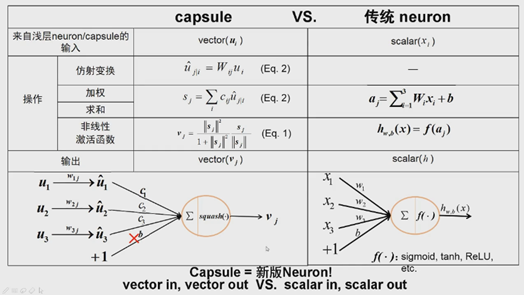
Capsule与传统神经元对比,相似处很多:
在传统神经元中,标量xi,加权求和得到aj。用非线性激活函数,转换得到神经元输出,是个标量值,激活函数可以选择sigmoid、tanh和ReLU等,最终得到标量。
在Capsule中,ui是向量,矩阵的乘就是一个简单的仿射变换,在传统神经元中没有,然后,对i维度做加权求和,传统是对标量加权求和,Capsule是对向量加权求和得到向量。Squash函数是个非线性的函数,与传统非线性对应,输出是向量。
在论文第二部分核心内容:将标量输入输出扩展到向量输入输出。
新的神经元的参数有哪些呢?W和c。传统方法中参数是用梯度方法更新,capsule中怎么更新?
(3)参数更新算法routing-by-agreement的分析
CNN用pooling做routing,capsule中则不同

实际上W用BP更新,Wij是8*16的矩阵,更新不多说;
C用另外一个原则更新,routing-by-agreement,cij是标量,重点看伪代码。
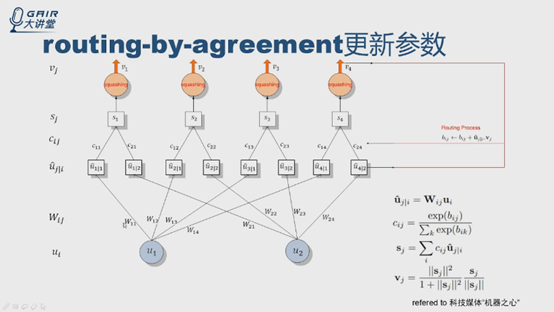
假设l层有两个神经元,u1,u2,输出是四个神经元v1v2v3v4。
从ui开始,用公式计算得到u4|1,u4|2.
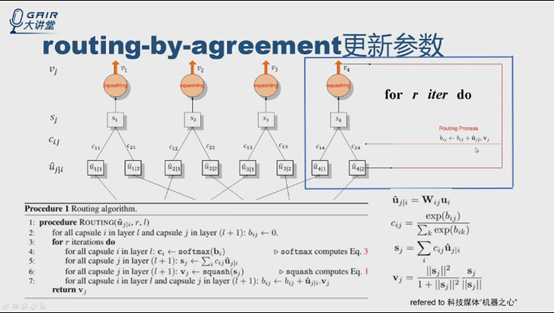
根据伪代码中第4步和公式3,计算c14和c24,第5步得到S4,得到v4,根据伪代码第7步,得到新的b值。进行多轮迭代(r轮),更新c值,确定连接权重,输出第r次迭代后的v4,输入到网络的下一层。bij的更新与ui|i和vj有关,是标量积,实际上是个投票的过程, bij初始化为0。
迭代轮数r是自己定义的,是个超参数,论文实验表明r为3时效果最好。

在实验中可以看到,routing还有很多相关的问题,效果还不是太理想。
实际上,总结起来,与简单地添加层不同,capsule是在层中加嵌套层,添加一组神经元。

|
Siraj Raval总结为两点: Layer-based squashing :不是简单地对每个神经元激活,而是将这些神经元组成一个capsule,然后对整个capsule内的所有神经元做非线性激活 Dynamic routing :通过routing-by-agreement原则替换pooling |
(4)CapNets模型
Capsule是个新的神经元,传统的神经元可以构建网络,论文中第四部分给出了CapNets的模型,主要三层,不包括后面的重构模型,一层一层地看。
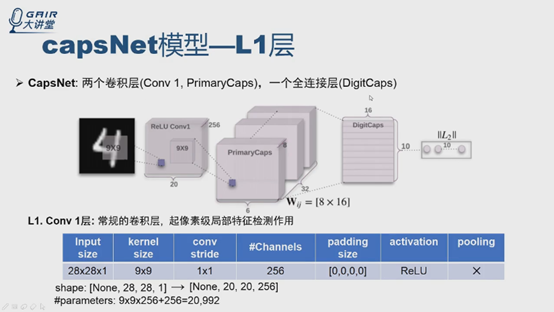
第一层是常规的卷积层,有什么作用呢?为什么不直接用capsule呢?(报告人认为可以扩展到capsule,需要实验证明)还有两层,PrimaryCaps层和DigitCaps层。
整个论文就是两个卷积层,一个全连接层,Hinton把PrimaryCaps看做capsule的卷积层,把DigitCaps看做capsule的全连接层
PrimaryCaps层(在论文第四部分第一行):

论文中说每个capsule是8D的,是8个卷积单元的结构,可以理解为8个通常意义上的卷积层。
整个L2层的输入是20*20*256特征图,PrimaryCaps层卷积核是9*9,stride是2*2,通道是32,非线性函数是squashing函数,没有用到routing算法。怎么理解呢?讲两种理解方式。
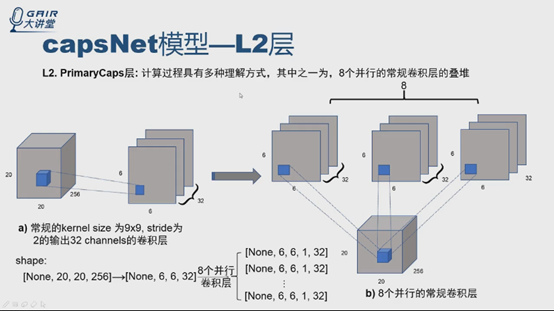
第一种:这一层可以看成8个并行的常规卷积层的叠堆,怎么理解呢?
先看下a图,从输入的20*20*256,如果做常规的卷积层,与论文中提到的一样,得到6*6*32,20-9=11,11/2=5.5,5.5+1=6.5,舍弃,最终得到6*6*32。维度的变化从20*20*256,得到6*6*32,并行地做8个卷积,扩展维度,加个1,就有8个张量了,怎么做呢?把8个张量合并。
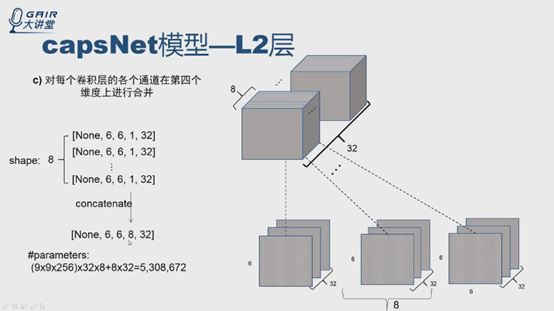
可视化结果什么样?现在有8个6*6*32的,就是8堆,每一次从每一堆取其中一张6*6的特征图,共32张,就得到32个6*6*8,就与论文中模型一样了。
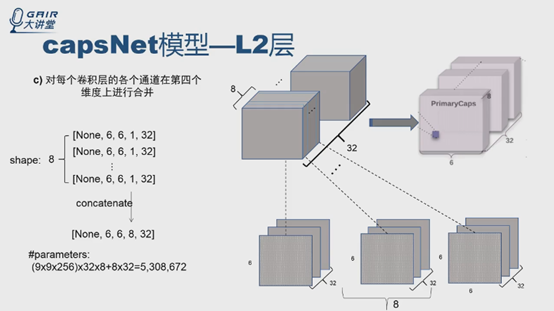
为什么是并行,不是串行呢?可以有多种理解方式,这里给出的是报告人最开始想到的一种方式,这种方式与论文中给出的PrimaryCaps层有32个通道,权重共享是6*6的描述对应起来了。
这种理解方式在计算时比较复杂,看另一种计算很简单的理解方式。
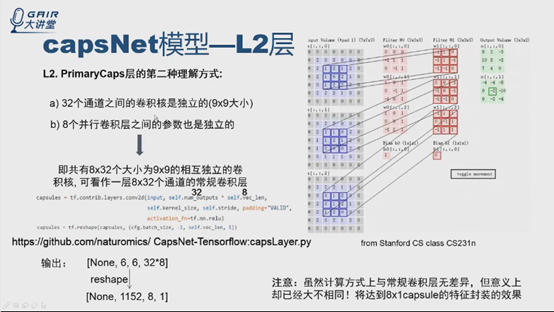
了解卷积概念的应该都清楚,32个通道就是有32个相互独立的卷积核,8个并行的卷积层的单元相互独立,就是说有8*32个相互独立的卷积核,计算过程可以看成有8*32个通道的卷积层。那么这一层的输入input只用普通卷积(TensorFlow中conv2d)来计算,通道数直接就是self.num_outputs*self.vec_len=32*8,就实现了这一层的计算过程,之后reshape就得到下面1152*8*1的张量。8*1对应一个capsule的输入,与论文一致。这个计算方式很简单,与传统卷积层无差别,但是意义已经不一样了,因为在reshape之后,还加了一些层,在后续层的作用上,达到对8*1的特征封装的效果。
DigitCaps层:
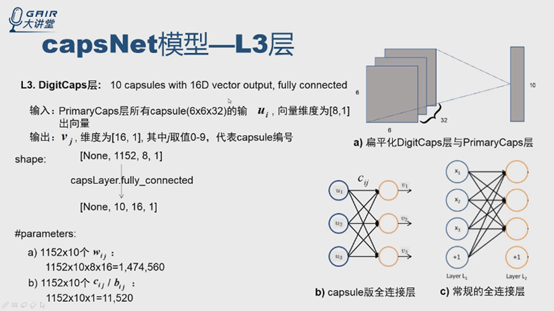
可以把每个capsule看成是神经元,输出是向量,论文中说DigitCaps层是16D的向量,那么可不可以把向量看成一个向量点?
理解方式就是,把向量扁平化,看成一个点,那么这层的输入PrimaryCaps实际上是6*6*32特征图,其中每个点是8*1的向量点,输出是10个capsule,每个是10*1,也可以看成,每个神经元输出一个向量点。下图只画了3个输入三个输出的图,可以看做全连接,权重cij,输出ui,是capsule版的全连接。与常规的区别在两处:一是输入输出是向量,二是没有偏置值。代码可以直接做capsLayer的fully_connected直接调用,从1152个capsule的输入,得到10个capsule的输出,每个capsule向量是16*1。参数个数计算方法,大家自己计算一下。
Q:有人问cij是矩阵吗?
A:从每一条边u1-v1来看cij是标量(公式2),对于整个过程可以写成矩阵的形式。
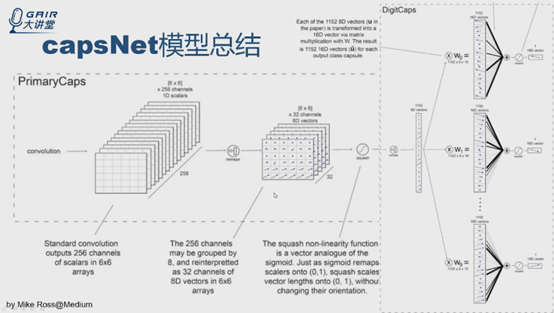
第一层就是常规卷积,就不说了。
PrimaryCaps层实际上就是一个卷积,就是一个32*8=256个通道,是个常规的卷积过程,直接做reshape,得到32个6*6*8,这个图非常好,把每个8*1的向量表示成向量点,用箭头表示,对特征图做非线性转换squashing。这层结束。
DigitCaps层实际上就是capsule版的全连接层,先把6*6*32张量直接reshape成1152capsule,每个输出是8D的向量点,后面输出是10个capsule,每个capsule是16D的向量,权重是c。总结来说,capsNet是常规卷积层与capsule版全连接层的结合体。
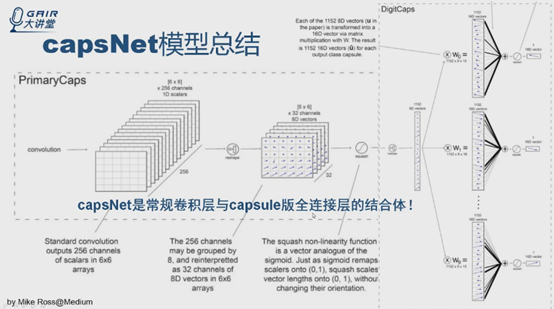
到这里介绍完了论文第四部分模型的结构。接下来与传统CNN /FC比较。
(5)CapsNet模型与卷积/全连接神经网络的比较
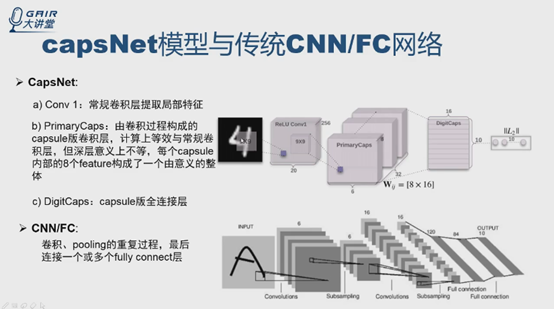
CapsNet共三层,先是常规卷积层,然后是capsule的卷积层,之后是capsule版的全连接层。
传统CNN 也是这么干的,先卷积-pooling,再卷积-pooling,最后全连接层。能够理解CNN中最后放全连接层的话,也能明白这里也加全连接层的原因。理解相似之处。
另一个重要的是损失函数,论文中给出margin loss和重建loss

先说下重构网络,论文中说重构的主要目的是正则化,用的网络很简单就是三层的全连接,不多说。
Margin loss函数才是主要的目的,这个函数在支持向量机中经常见到,自己查阅了解下。主要是限制vc长度的上下边界,详细内容自己查阅理解。
直接跳到实验部分,论文中做了几个有趣的实验,按照论文的顺序说
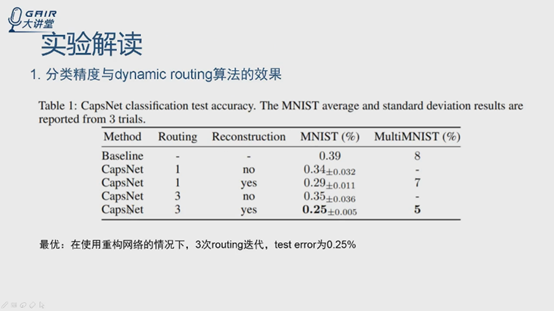
第一个做分类精度,验证dynamic routing的效果,从论文给出的数据结果来看,第一列是模型,第二列是迭代次数,1和3,附录有实验证明,自己看,实验表明3的时候效果最好,第三列表示是否加了重构网络,加了之后效果更好一点。但是事实上,自己做的实验,就是github上的代码
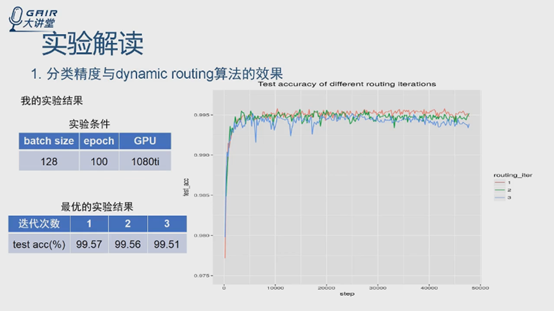
实验条件尽量一致,也是128个batchsize,epoch 100,验证routing迭代问题,取了1,2,3,下面是迭代次数,左侧是精度。不知道是不是代码实现的问题,还是routing不是很好,主要时间消耗也在routing迭代,论文中一个很重要的改进点可以在routing上下手。
另一个实验重构

说一个很有趣的问题,输入是上面的一行,下面一行是重构出的,前三列竟然有去噪效果,尤其是8,可以好好地利用这个特点吧
还有一个实验

之前说输出的每个capsule是个向量,意义是什么呢?实际上就是对实体的封装,实体有不同的属性,输出的向量每个维度是否能明确表明实体的一个属性,这个实验就是证明这点。16维,在第一维上随机加扰动,加0.05看结果,再加0.05,实验中结果很好,每个维度能很好地表示手写数字的一种属性。
第四个实验验证做图像分割的能力

很重要的实验,在一定程度上解决了CNN很难识别重叠图像的问题,输入是包含两个重叠数字的图,输出是能够把重叠的数字区别出来,实验结果表明具有非常强的像素级分割的能力。这个特点可以做什么问题呢?在处理公共场合的图像,行人多,有重叠,困难,CNN处理这个问题不是很理想,可以试试capsule
(6)讨论:论文的贡献及可改进之处
论文的主要贡献

报告者认为参数更新方法与注意力机制有相似性
(7)核心算法的代码剖析
核心代码是报告者自己实现的
地址在github上:https://github.com/naturomics/CapsNet-Tensorflow
论文出来当天就出来,2天就跑起来了。
Capsnet文件和capslayer
Q:训练过程是怎样的?BP和routing是交替进行的吗?
A:Cij是在数据前向传播更新的,看前面的图
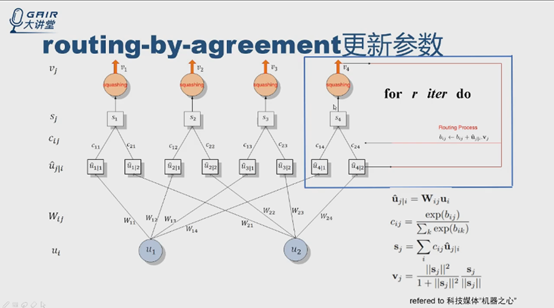
数据在前向计算时,在框内迭代更新cij,更新完才输出v4,直到loss function,然后计算梯度,梯度返回来更新w,即c是在前向过程中计算的,w是在反向的过程BP中更新的。
Q:softmax是对第l层的i还是l+1层的j做的
A:k对应的是j的位置,即对图中的这四个v做的
代码非常简洁,只有四页ppt




总结
正如Hinton在接受吴恩达采访时所说的:
如果你的直觉很准,那你就应该坚持,最终必能有所成就;反过来你直觉不好,那坚不坚持也就无所谓了。反正你从直觉里也找不到坚持它们的理由。

当Hinton在70岁时还在努力推翻自己积累了30年的学术成果时,我才知道什么叫做生命力。
参考:
1. http://www.sohu.com/a/200915041_697750 capsule提出的时间点
2. Hinton多伦多演讲
http://www.sohu.com/a/165989490_465975
http://www.sohu.com/a/166038358_464065 有Hinton讲pooling四个问题的详细示例
3. http://www.mooc.ai/open/course/288 从传统神经网络的角度解读Capsule
4. http://www.iqiyi.com/w_19rv08vrlp.html Siraj Raval
有些图片和内容是之前学习的时候记录的,已经找不到出处了,如有侵权,请告诉我。如有错误,也请大家指出,谢谢阅读。
2convs- pooling-2convs-pooling-3convs-pooling-3convs-pooling-3convs-pooling

 浙公网安备 33010602011771号
浙公网安备 33010602011771号