Python中的常用内置对象之map对象
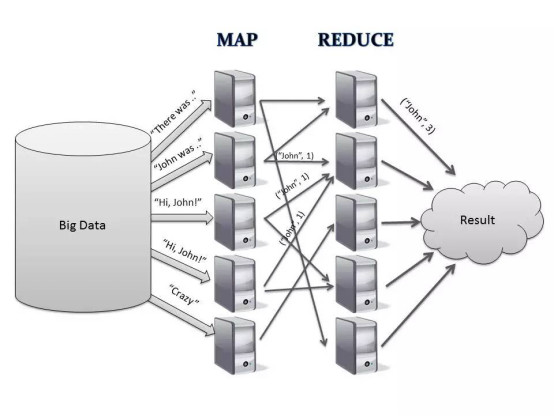
如果你了解云计算的最重要的计算框架Mapreduce,你就对Python提供的map和reduce对象有很好的理解,在大数据面前,单机计算愈加力不从心,分布式计算也就是后来的云计算的框架担当大任,它提高了效率、节省了时间,但是计算量并没有减少。有点类似分久必合,合久必分的趋势。map就是对任务分发,实现分布式计算,reduce就是把分布式计算的结果进行聚合。
Map和Reduce过程像是为控制新型肺炎而建设的火神山、雷神山医院的建设过程,如果建设承建集团用一个10人建设队竣工需要建设600天的话,理想情况下找来100个这样的建设队把工期就可缩短为6天。Map过程就是由承建方把任务分给100个建设队分好任务去建设,reduce就是把各自建设好的工程再整合起来统一交付给承建方。
谈到云计算的起源,就不得不提Google的三驾马车:Google FS、MapReduce、BigTable。虽然Google没有公布这三个产品的源码,但是他发布了这三个产品的详细设计论文,奠定了风靡全球的大数据算法的基础!
2004年公布的 MapReduce论文,论文描述了大数据的分布式计算方式,主要思想是将任务分解然后在多台处理能力较弱的计算节点中同时处理,然后将结果合并从而完成大数据处理。
map(function, iterable, ...)
返回一个将 function 应用于 iterable 中每一项并输出其结果的迭代器。如果传入了额外的 iterable 参数,function 必须接受相同个数的实参并被应用于从所有可迭代对象中并行获取的项。当有多个可迭代对象时,最短的可迭代对象耗尽则整个迭代就将结束。
它的第一个参数是一个函数的名字,后面是一个可迭代对象。
举例说明,比如我们有一个函数f(x)=x*x,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:现在,我们用Python代码实现:
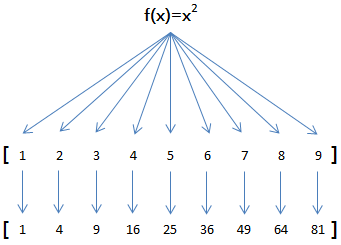
1 >>> def f(x): 2 return x * x 3 >>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) 4 >>> list(r) 5 [1, 4, 9, 16, 25, 36, 49, 64, 81]
map()传入的第一个参数是f,即函数对象本身。由于结果r是一个Iterator,Iterator是惰性序列,因此通过list()函数让它把整个序列都计算出来并返回一个list。
实战:请利用map()函数,把一个list(包含若干不规范的英文名字)变成一个包含规范英文名字的list
任务
假设用户输入的英文名字不规范,没有按照首字母大写,后续字母小写的规则,请利用map()函数,把一个list(包含若干不规范的英文名字)变成一个包含规范英文名字的list:
输入:['adam', 'LISA', 'barT']
输出:['Adam', 'Lisa', 'Bart’]
参考代码:
1 def f(s): 2 s1 = s[0:1].upper() +s[1:].lower() 3 return s1 4 print(list(map(f,['jake','JOE'])))
结果:
['Jake', 'Joe']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号