网络通信协议设计
《网络通信协议》
1. 背景
在计算机体系中,存在着很多的网络通信协议;通信协议的实际上就是一段数据,通信双方按照提前约定的规则去进行编码解码,达到传输数据的目的;例如,TCP/IP是目前计算机设备最常用的通信协议;TCP/IP实际上是一个协议族,包含一组协议,其中靠近应用层且最常用的协议是TCP和UDP。
TCP是流式协议,即协议的内容是流水一样的字节流,内容与内容之间没有明确的分解标志,需要人为的给这些内容划分边界;例如,A与B进行TCP通讯,A发送两个数据包给B,大小分别为100个字节,200个字节,对于A来说,作为发送方,是知道如何划分这两个数据包的界限的,但是对于B来说,可能一次,或者多次受到A发送的数据包,例如先收到50字节,后受到250字节,或者先收到200字节,后收到100字节,因此B是无法知道应该将受到的多少个字节的数据包作为一个有效的数据包;而规定每次将多少个字节作为有效的数据包,就是协议格式需要定义的内容;
一个简单的例子:
// 发送端发送数据
char buf[] = "the quick brown fox jump over a lazy dog";
int sendBytes = send(socket, buf, strlen(buf), 0);
char recvBuf[50] = {0};
int recvBytes = recv(socket, recvBuf, 50, 0);
printf("recevice content: %s\n", recvBuf);
上述的简单代码在本机上一般会执行的比较好,接收端会如期打印出发送端发送的内容;但是这样的代码在局域网或者公网环境下会出问题,接收端打印出的内容可能不完整,或者出现乱码,不完整是因为发送端可能分多次发送数据,导致接收端接收不完整的情况下进行数据打印;乱码出现的原因为,接收端不仅接收到了完整的字符串内容,还接受到了下一个字符串的部分内容;这就导致接收缓冲区被填满,在printf的时候知道碰到"\0"才结束,导致内存越界;
2. 粘包问题
在进行网络通信时,一般会出现粘包,丢包,和包乱序问题;TCP一般不会存在这种问题,因为TCP栈可以通过序列号和包重传确认机制,保证数据包的有序,和一定被发送到正确的目的地;但是UDP可能会存在上述问题,如果需要确保UDP传输数据的有序性和不丢包,就需要在UDP的基础上实现TCP类似的可靠传输机制;当解决数据传输的有序性以及可靠性之后,唯一剩下的就是数据粘包问题;
粘包:当连续向对端发送两个或者两个以上的数据包的时候,对端在一次收取中收到的数据包可能大于1个,从而造成粘包,粘包的示意图如下所示:
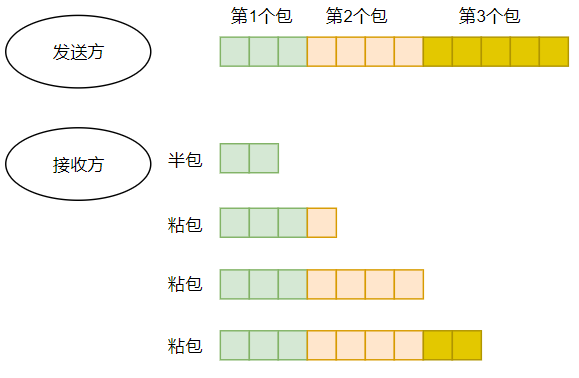
因为TCP是流式数据格式,因此无论是半包还是粘包问题,其解决思路还是从接收到的数据中将包与包的边界区分出来;区分的方法有下列几种:
- 采用固定包长的数据包
固定包长,即每个协议包的包长是固定的;例如包长为128字节,则每收够128字节的数据,就进行解析,如果不够,就暂时存储; 这种协议的特点是格式简单,解析简单,但是灵活性较差;如果报文内容过少,则需要对包中存储数据的区域进行部分填充,如果报文内容过长,则在发送端需要拆包,而在接收端有需要重新组包;
- 以指定的字符作为包的结束标志
这是一种较为常见的协议包,即在字节流中遇到指定的字符,则认为就到包的末尾了;例如遇到"\r\n"(即CRLF),则表示包结束;这种包协议的不足之处就是,如果包中数据包含"\r\n"等特殊字符时,则需要进行转码或者转义;
- 采用包头+包体的格式
此种格式一般包含两个部分,包头+包体,包头大小是固定的,且必须包含一个字段,能够表接下来的包体的长度;
3. 协议设计基础
假设需要设计一个基本的协议传递信息:
#pragma pack(push, 1)
struct userinfo
{
int m_cmd;
char m_gender;
char name[10];
};
#pragma pack(pop)
如果后续需要对协议进行升级,增加一个age字段,此时服务端协议就不能完全兼容就客户端的协议;因此一般在设计之前,需要增加一个version相关的字段,来表示协议的版本信息;服务端可以根据version字段来解析客户端的协议,达到较好的兼容性;
#pragma pack(push, 1)
struct userinfo
{
unsigned short m_version;
int m_cmd;
char m_gender;
char name[10];
};
#pragma pack(pop)
后续协议增加新的字段后:
#pragma pack(push, 1)
struct userinfo
{
unsigned short m_version;
int m_cmd;
char m_gender;
char name[10];
unsigned short age; // 新增字段
};
#pragma pack(pop)
对于客户端程序,可以对收到的报文,先解析一个unsigned short字节大小的数据,获取到verson的值,再根据version的值取解析数据包:
// buff 接受缓冲区
unsigned short version = parseBytes(buff, 2);
if (version == 1)
{
// 解析版本1数据包
}
else if (version == 2)
{
// 解析版本2数据包
}
...
这种方法的弊端是如果协议版本很多,会出现很多的处理分支;
struct and TLV
为了解决协议修改后的兼容性问题,可以设计在上述协议的每个字段前面增加一个新的字段type,来表示每个字段的类型:
| 类型 | type值 | 描述 |
|---|---|---|
| bool | 0 | 布尔类型 |
| char | 1 | char类型 |
| int | 2 | int类型 |
| float | 3 | float类型 |
| ... |
这种表示每个字段类型的协议,就具有自解释性了,这就是TLV(Type Length Value);
协议分类
根据协议的内容,协议可分为二进制协议和文本协议;文本协议是指人为可读的格式的协议(典型的如FTP,HTTP)
4. 协议设计工具(之所简单记录,了解)
TLV虽然简单,但是每设计一套协议,就要重新编写,调试,测试编码,解码程序,过程繁琐且耗时;介绍一种叫做IDL的语言规范;IDL表示Interface Description Language,IDL是一种描述接口的中间语言;IDL将协议的使用类型规范化,提供跨语言特性;用户可以预先定义一个描述协议格式的IDL文件,然后通过相应的IDL工具分析IDL文件,即可生成各种语言版本的协议代码;Google Protobuf自带的protoc就是一种IDL工具;
5. 协议数据压缩 (简单了解)
在设计协议的过程中,整形类型的数据(int32, int64)出现的频率很高;例如对于uint32类型的数据,其表示的范围为0-2^32-1; 在实际的应用中,int类型数据表示的值很少出现非常大的值(接近最大值的情况),因此可以根据一个int类型数据的实际值,将其进行适当的压缩,用1~n个字节来进行表示;
既然有压缩的方式,肯定有解压的方式,具体的算法可在POCO C++库中查找,int32,int64这些数据类型的压缩与解压算法 (参考书:《c++服务器开发》 Page:435)
6 通信协议设计注意事项
6.1 字节对齐
在协议设计基础中,报文结构体定义前面都有一组成对的指令#pragma pack(push, n)和#pragma pack(pop),用于告诉编译器将接下来的结构体定义中的每个字段都按照n字节进行对齐;这样做是为了使内存更加紧凑,以节省空间。
注:
push和pop一定需要成对使用,否则编译出来的代码会出现很多奇怪的运行结果;
6.2 显式的指定整形字段的长度
例如,对于int类型的字段,在将其作为协议传输的时候,应该显式指定该类型的长度。即应该使用int32_t, int64_t代替int, long等类型;因为在不同字长的机器上,int, long类型的长度是不同的;例如long在32位操作系统上的长度为4字节,在64位机器上的长度为8字节;如果不显式的指定这种长度,则会因为机器字长的不同,导致协议解析出错。
6.3 涉及浮点数时要考虑精度
计算机在表示浮点数的时候存在精度取舍不准确的问题,在设计协议的时候,如果浮点数字段对于精度的要求很高,则需要避免不同机器解析得到不同的结果。对浮点数进行传输时,可将其放大相应的倍数,将其转换为整数进行传输;或者将其转换为字符串进行传输;
6.4 大小端问题
通常在网络传输之前,将所有整型数据转换为大端序,避免不同机器在解析的时候得到不同的数据;如果明确的知道通讯双方使用的是相同的字节序,则就不需要转换;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号