HadoopHA集群搭建
一、 准备工作
服务器
|
服务器 |
IP |
说明 |
|
hadoop01 |
192.168.110.121 |
节点1 |
|
hadoop02 |
192.168.110.122 |
节点2 |
|
hadoop03 |
192.168.110.123 |
节点3 |
软件版本
|
项 |
说明 |
|
Linux Server |
CentOS 7 |
|
hadoop-2.7.3 |
2.7.3 |
|
zookeeper |
3.5.9 |
|
JDK |
1.8-202 |
Linux操作用户:tom
二、 免密登录
l 通用操作(3台服务器均要操作)
#生成公钥(连续4次回车)
ssh-keygen -t rsa -m PEM
#配置本机免密ssh登录
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
#手动ssh登录本机一次,第一次需要输入密码,以后就不用了
ssh hadoop01
l 配置hadoop01节点ssh免密码登录其余节点
#在hadoop01节点执行如下命令(如果用不了如下命令,可以直接复制id_rsa.pub里的密钥到其余几台设备的authorized_keys文件里也可)
ssh-copy-id hadoop02
ssh-copy-id hadoop03
# 授权
chmod 600 authorized_keys
#在hadoop01节点分别ssh登录其他节点一次,第一次需要输入密码,以后就不用了
ssh hadoop02
ssh hadoop03
#在hadoop02、hadoop03上执行相同操作,免密登录其他节点
三、 Hadoop集群搭建
l 依赖环境
JDK1.8、zookeeper3.5.9,搭建方式见本人其他随笔
l 防火墙配置
#开放端口(3台服务器均开放)端口:50070、8080、8485
firewall-cmd --add-port=50070/tcp –permanent
firewall-cmd --add-port=8080/tcp --permanent
firewall-cmd --add-port=8485/tcp --permanent
#重新加载防火墙配置
firewall-cmd --reload
#查看开发端口:
firewall-cmd --list-ports
l 安装步骤
#创建目录
mkdir -p /home/tom/app/hadoop/data
mkdir -p /home/tom/app/hadoop/logs
#解压到app目录
tar -zxvf hadoop-2.6.0-cdh5.16.2.tar.gz -C /home/tom/app/hadoop
#设置系统环境变量
vim ~/.bash_profile
#新增如下环境变量
export HADOOP_HOME=/home/tom/app/hadoop/hadoop-2.6.0-cdh5.16.2
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/sbin:$PATH
# 刷新文件
source ~/.bash_profile
#校验命令
hadoop version
yarn version
l 修改配置文件
配置文件路径:$HADOOP_HOME/etc/hadoop
主要的修改的配置文件包括:core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves、hadoop-env.sh等
- hadoop-env.sh
# 修改如下
export JAVA_HOME= /home/tom/app/jdk1.8.0_202
# 日志路径,方便在集群启动失败时查看日志,查找原因
export HADOOP_LOG_DIR=/home/tom/app/hadoop/logs
- core-site.xml
#修改如下
<configuration>
<property>
<!-- 指定namenode的hdfs协议文件系统的通信地址 -->
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
<description>注意:myhadoop为集群的逻辑名,需与hdfs-site.xml中的dfs.nameservices一致!</description>
</property>
<property>
<!-- 指定hadoop集群存储临时文件的目录 -->
<name>hadoop.tmp.dir</name>
<value>/home/tom/app/hadoop/data/tmp</value>
</property>
<property>
<!-- ZooKeeper集群的地址 -->
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<!-- ZKFC连接到ZooKeeper超时时长 -->
<name>ha.zookeeper.session-timeout.ms</name>
<value>10000</value>
</property>
</configuration>
- hdfs-site.xml
# 修改如下
<configuration>
<property>
<!-- 指定HDFS副本的数量 -->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!-- namenode节点数据(即元数据)的存放位置,可以指定多个目录实现容错,多个目录用逗号分隔 -->
<name>dfs.namenode.name.dir</name>
<value>/home/tom/app/hadoop/data/namenode/data</value>
</property>
<property>
<!-- datanode节点数据(即数据块)的存放位置 -->
<name>dfs.datanode.data.dir</name>
<value>/home/tom/app/hadoop/data/datanode/data</value>
</property>
<property>
<!-- 集群服务的逻辑名称 -->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- NameNode ID列表-->
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- nn1的RPC通信地址 -->
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop01:8020</value>
</property>
<property>
<!-- nn2的RPC通信地址 -->
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop02:8020</value>
</property>
<property>
<!-- nn1的http通信地址 -->
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop01:50070</value>
</property>
<property>
<!-- nn2的http通信地址 -->
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<!-- NameNode元数据在JournalNode上的共享存储目录 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/mycluster</value>
</property>
<property>
<!-- Journal Edit Files的存储目录 -->
<name>dfs.journalnode.edits.dir</name>
<value>/home/tom/app/hadoop/data/journalnode/data</value>
</property>
<property>
<!-- 配置隔离机制,确保在任何给定时间只有一个NameNode处于活动状态 -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<!-- 使用sshfence机制时需要ssh免密登录,注意此处填写绝对路径,特别重要 -->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/tom/.ssh/id_rsa</value>
</property>
<property>
<!-- SSH超时时间 -->
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<!-- 访问代理类,用于确定当前处于Active状态的NameNode -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 开启故障自动转移 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
#去掉权限验证,防止其他地方调用hdfs的时候出现用户权限问题,该属性可根据实际情况选择是否增加
<property>
<name>dfs. permissions</name>
<value>false</value>
</property>
- mapred-site.xml
#修改资源调度
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- yarn-site.xml
# 设置 yarn 上支持运行的服务和环境变量白名单
<configuration>
<property>
<!--配置NodeManager上运行的附属服务。需要配置成mapreduce_shuffle后才可以在Yarn上运行MapReduce程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 是否启用日志聚合(可选) -->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!-- 聚合日志的保存时间(可选) -->
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<!-- 启用RM HA -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- RM集群标识 -->
<name>yarn.resourcemanager.cluster-id</name>
<value>my-yarn-cluster</value>
</property>
<property>
<!-- RM的逻辑ID列表 -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- RM1的服务地址 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop02</value>
</property>
<property>
<!-- RM2的服务地址 -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop03</value>
</property>
<property>
<!-- RM1 Web应用程序的地址 -->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop02:8088</value>
</property>
<property>
<!-- RM2 Web应用程序的地址 -->
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop03:8088</value>
</property>
<property>
<!-- ZooKeeper集群的地址 -->
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<!-- 启用自动恢复 -->
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<!-- 用于进行持久化存储的类 -->
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
</configuration>
- slaves
vi slaves
#配置子节点,增加如下
hadoop01
hadoop02
hadoop03
# hadoop01在这里既是主节点,又是从节点
l 另外两台服务器上搭建Hadoop环境
用scp命令直接将改好的文件拷贝过去
scp -r hadoop/ @hadoop02:/home/tom/app/
scp -r hadoop/ @hadoop03:/home/tom/app/
scp -r ~/.bash_profile @kakfa02:~/
scp -r ~/.bash_profile @kakfa03:~/
另外两台服务器刷新环境变量
source ~/.bash_profile
四、 启动Hdfs集群
l 前置条件
先启动zookeeper
l 启动Journalnode
启动用于主备NN之间同步元数据信息的共享存储系统JournalNode
分别到三台服务器的的${HADOOP_HOME}/sbin目录下,启动journalnode进程:
hadoop-daemon.sh start journalnode
l 格式化namenode
#hadoop01上执行格式化命令
hdfs namenode -format
# 注意有如下信息则格式化成功
has been successfully formatted.
执行初始化命令后,需要将NameNode元数据目录的内容,复制到其他未格式化的NameNode上。元数据存储目录就是我们在hdfs-site.xml中使用dfs.namenode.name.dir属性指定的目录。这里我们需要将其复制到hadoop02/hadoop03上:
scp -r /home/tom/app/hadoop/data/namenode/data @hadoop02:/home/tom/app/hadoop/data/namenode
scp -r /home/tom/app/hadoop/data/namenode/data @hadoop03:/home/tom/app/hadoop/data/namenode
l 初始化HA状态
ZookeeperFailoverController是用来监控NN状态,协助实现主备NN切换的,所以仅仅在主备NN节点上启动就行:
在任意一台NameNode(本次配置的是hadoop01/hadoop02)上使用以下命令来初始化ZooKeeper中的HA状态:
hdfs zkfc -formatZK
注意成功信息:
Successfully created /hadoop-ha/mycluster in ZK.
l 启动HDFS
进入到hadoop01的${HADOOP_HOME}/sbin目录下,启动HDFS。此时hadoop01和hadoop02上的NameNode服务,和三台服务器上的DataNode服务都会被启动:
start-dfs.sh
l 启动YARN
进入到hadoop02的${HADOOP_HOME}/sbin目录下,启动YARN。此时hadoop02上的ResourceManager服务,和三台服务器上的NodeManager服务都会被启动:
start-yarn.sh
需要注意的是,这个时候hadoop03上的ResourceManager服务通常是没有启动的,需要手动启动:
yarn-daemon.sh start resourcemanager
l 通过jps命令查看
[root@hadoop01 sbin]# jps
4512 DFSZKFailoverController
3714 JournalNode
4114 NameNode
3668 QuorumPeerMain
5012 DataNode
4639 NodeManager
[root@ hadoop02 sbin]# jps
4499 ResourceManager
4595 NodeManager
3465 QuorumPeerMain
3705 NameNode
3915 DFSZKFailoverController
5211 DataNode
3533 JournalNode
[root@ hadoop03 sbin]# jps
3491 JournalNode
3942 NodeManager
4102 ResourceManager
4201 DataNode
3435 QuorumPeerMain
五、 查看Web UI
HDFS和YARN的端口号分别为50070和8080
这时,我们也可以在通过浏览器来查看集群的情况:
此时hadoop01上的NameNode处于可用状态
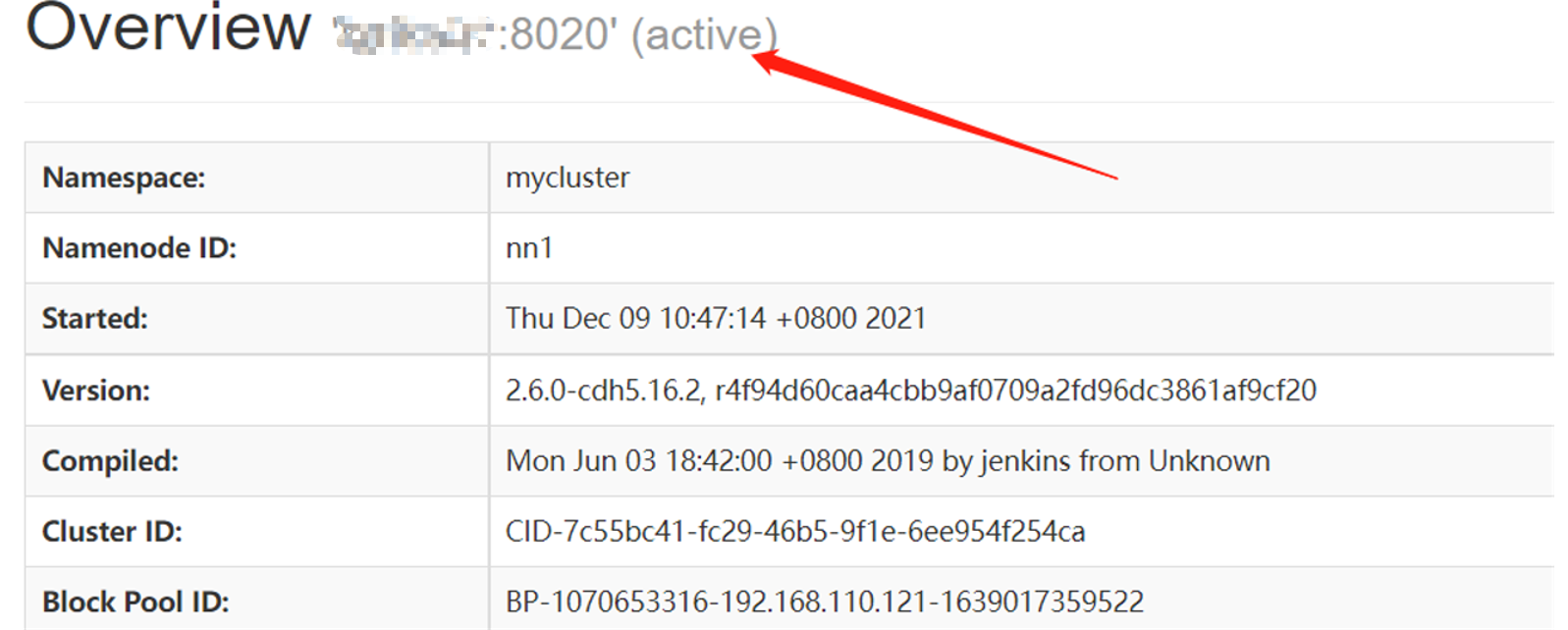
而hadoop02上的NameNode则处于备用状态:
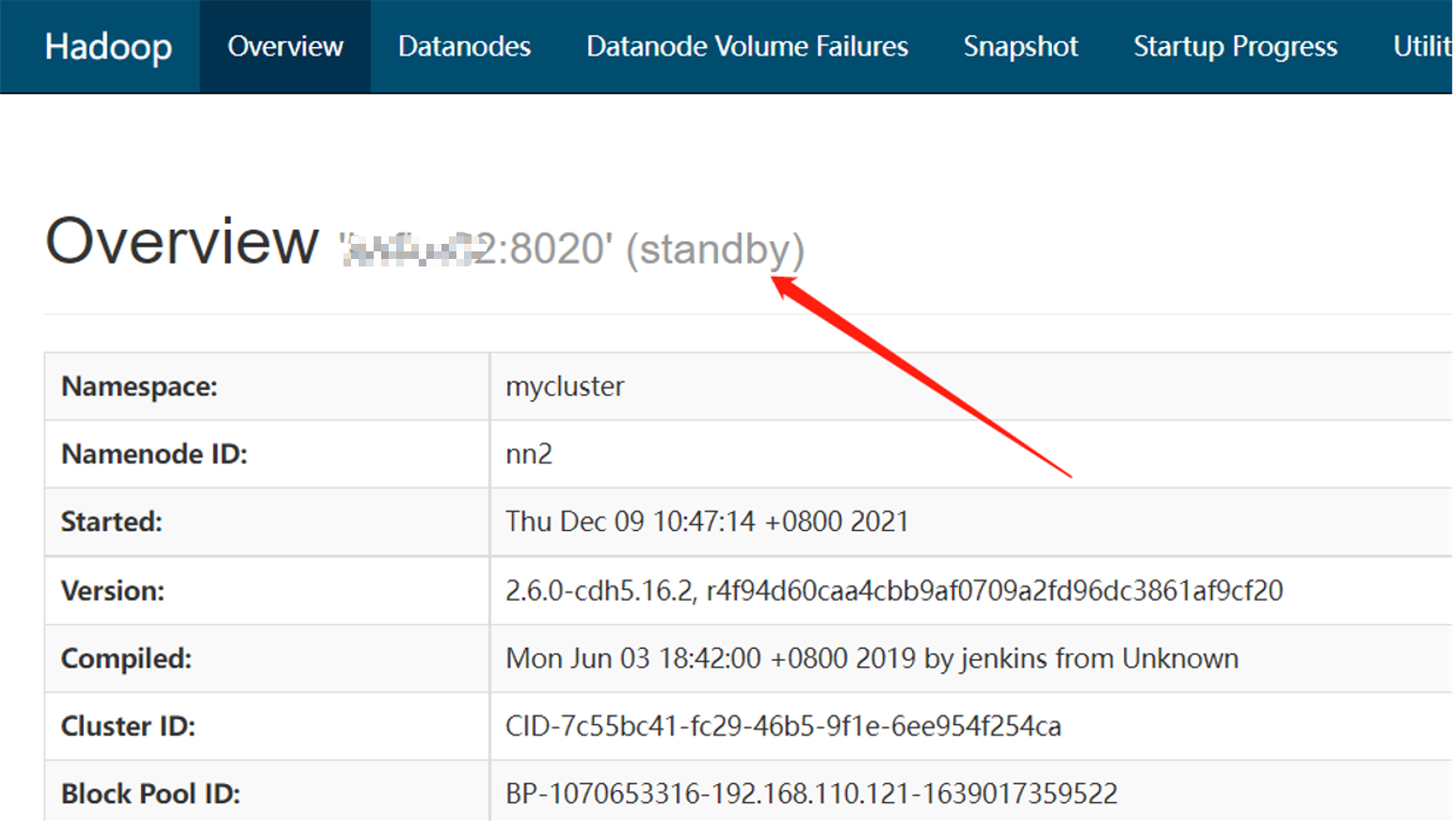
hadoop02上的ResourceManager处于可用状态:
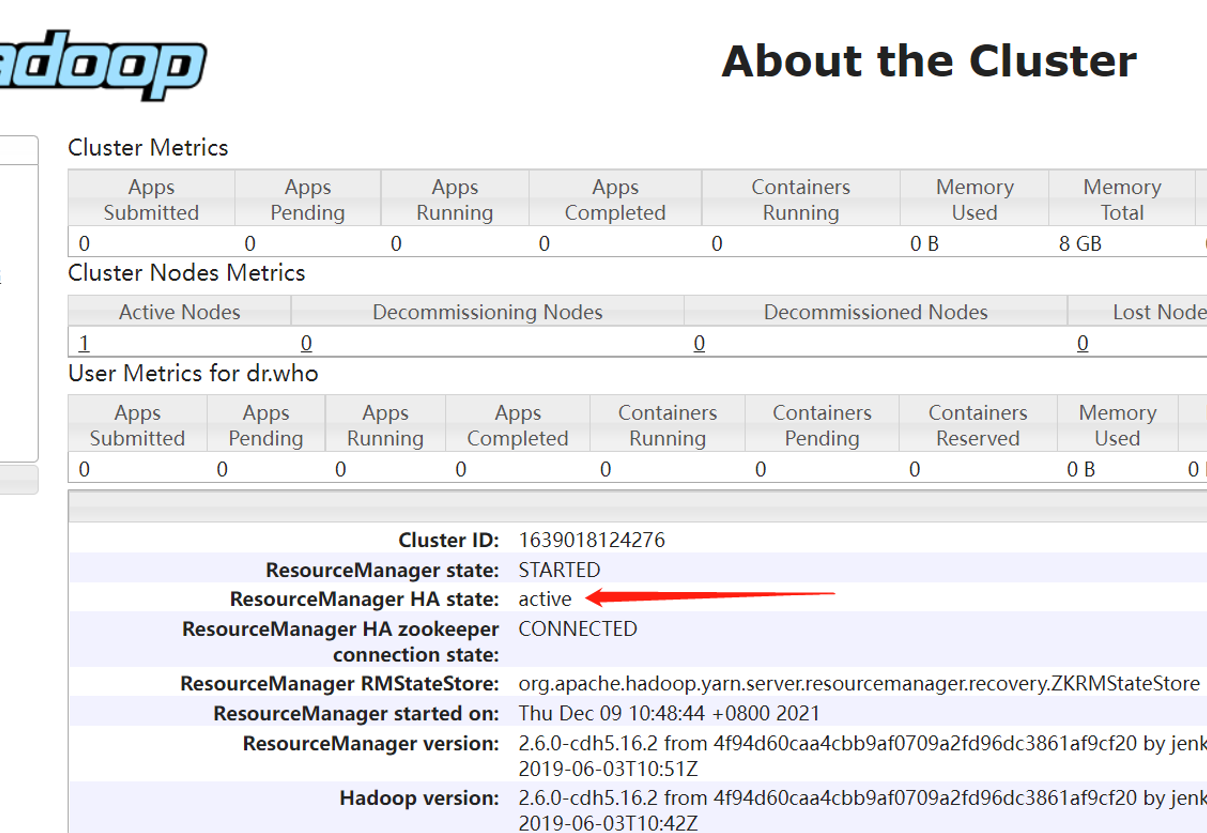
hadoop03上的ResourceManager则处于备用状态:
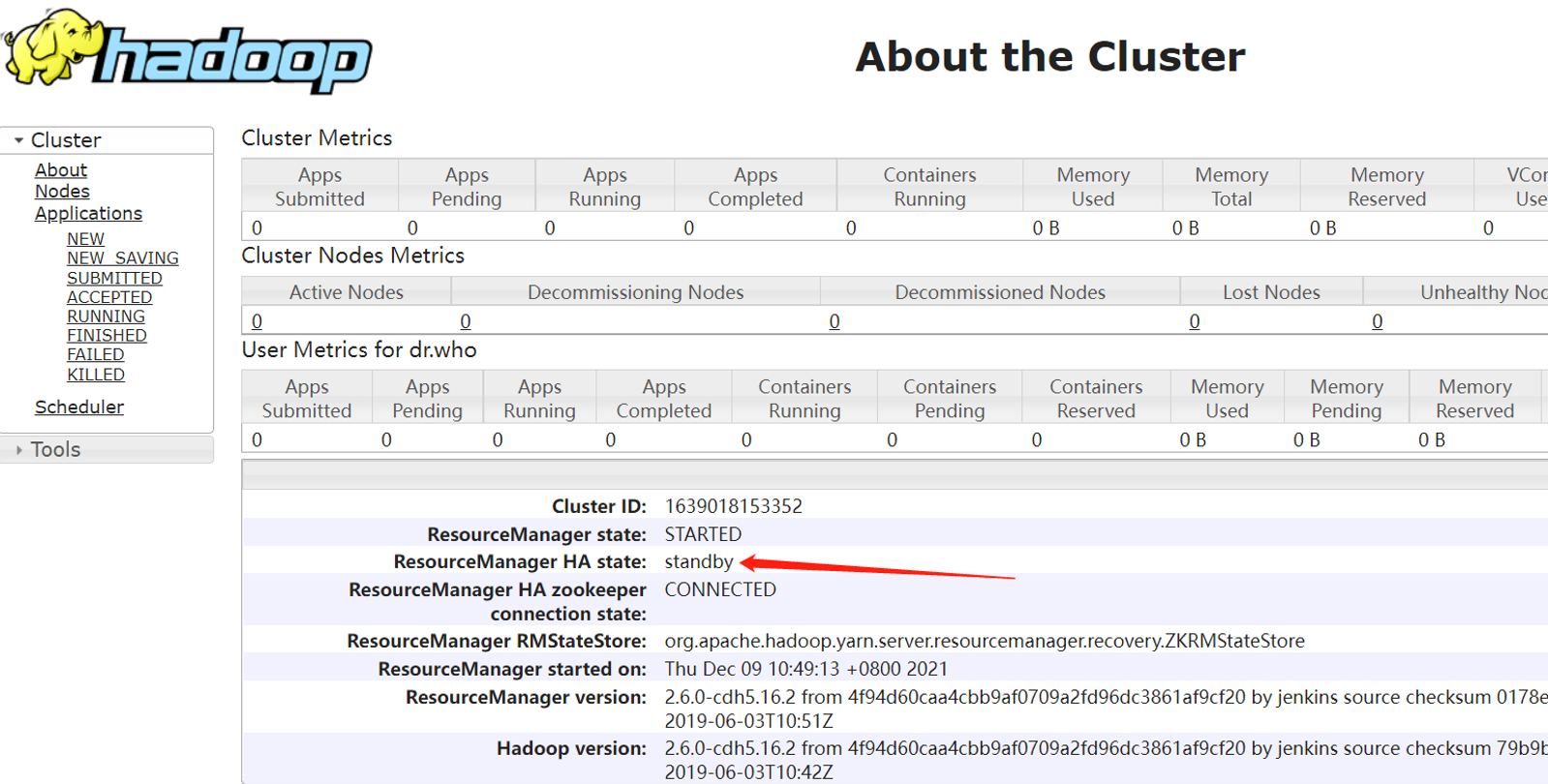
(注意修改win电脑的hosts文件,添加主机名与ip地址的对应关系,可以直接使用ip+端口的形式)
#如访问不了,注意看是不是防火墙没开
六、 集群的二次启动
上面的集群初次启动涉及到一些必要初始化操作,所以过程略显繁琐。但是集群一旦搭建好后,想要再次启用它是比较方便的,步骤如下(首选需要确保ZooKeeper集群已经启动):
- 在hadoop01启动 HDFS,此时会启动所有与 HDFS 高可用相关的服务,包括 NameNode,DataNode 和 JournalNode:
start-dfs.sh
- 在hadoop02启动YARN:
start-yarn.sh
- 这个时候hadoop03上的ResourceManager服务通常还是没有启动的,需要手动启动:
yarn-daemon.sh start resourcemanager
七、 集群的停止
可根据启动的方案顺序停止,如:
- 在hadoop01停止 HDFS:
stop-dfs.sh
- 在hadoop02停止YARN:
stop-yarn.sh
- 这个时候hadoop03上的ResourceManager服务如果还没有停止,需要手动停止:
yarn-daemon.sh stop resourcemanager
- 可根据实际情况执行停止脚本
# 或者执行stop-all.sh脚本,一次到位
八、 HA验证
- NN验证
主NN(hadoop01)上kill掉NameNode进程
[root@hadoop01 sbin]# jps
4512 DFSZKFailoverController
3714 JournalNode
4114 NameNode
3668 QuorumPeerMain
5012 DataNode
4639 NodeManager
kill 4114
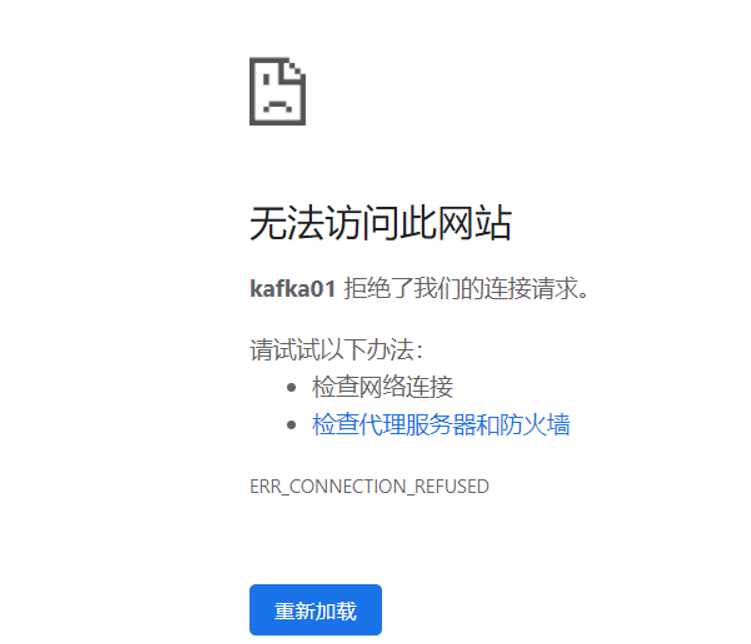
浏览器访问结果如下:
- 可以看到主NN监控已经无法访问了
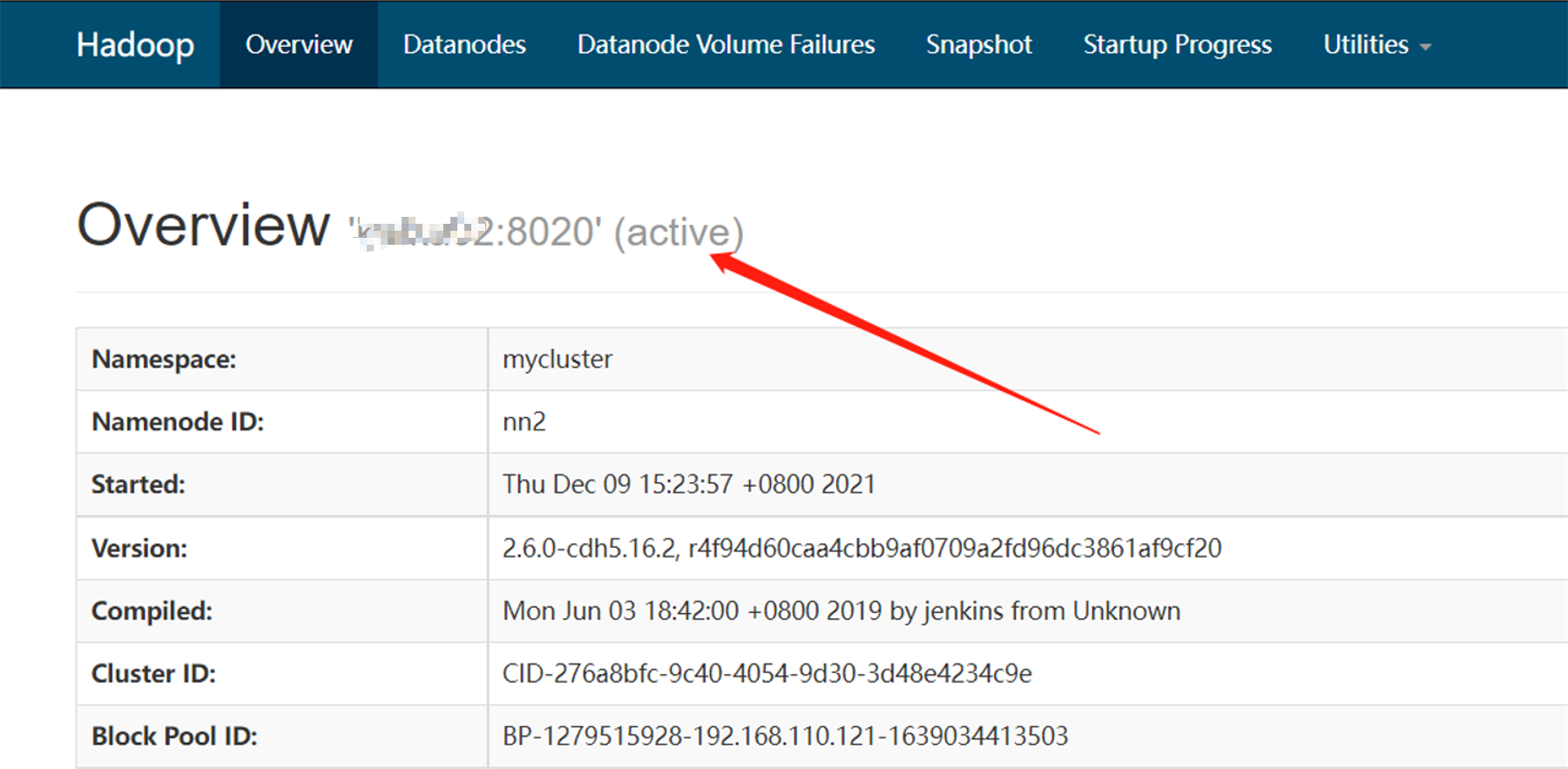
- 备NN自动切换,已经激活了
- RM验证
[root@ hadoop02 sbin]# jps
4499 ResourceManager
4595 NodeManager
3465 QuorumPeerMain
3705 NameNode
3915 DFSZKFailoverController
5211 DataNode
3533 JournalNode
kill 4499
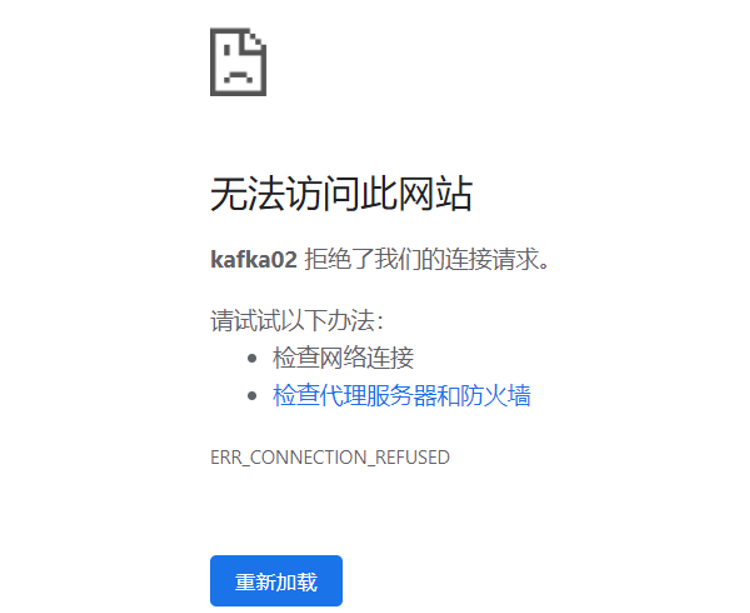
浏览器访问结果如下:
- 可以看到主RM监控已经无法访问了
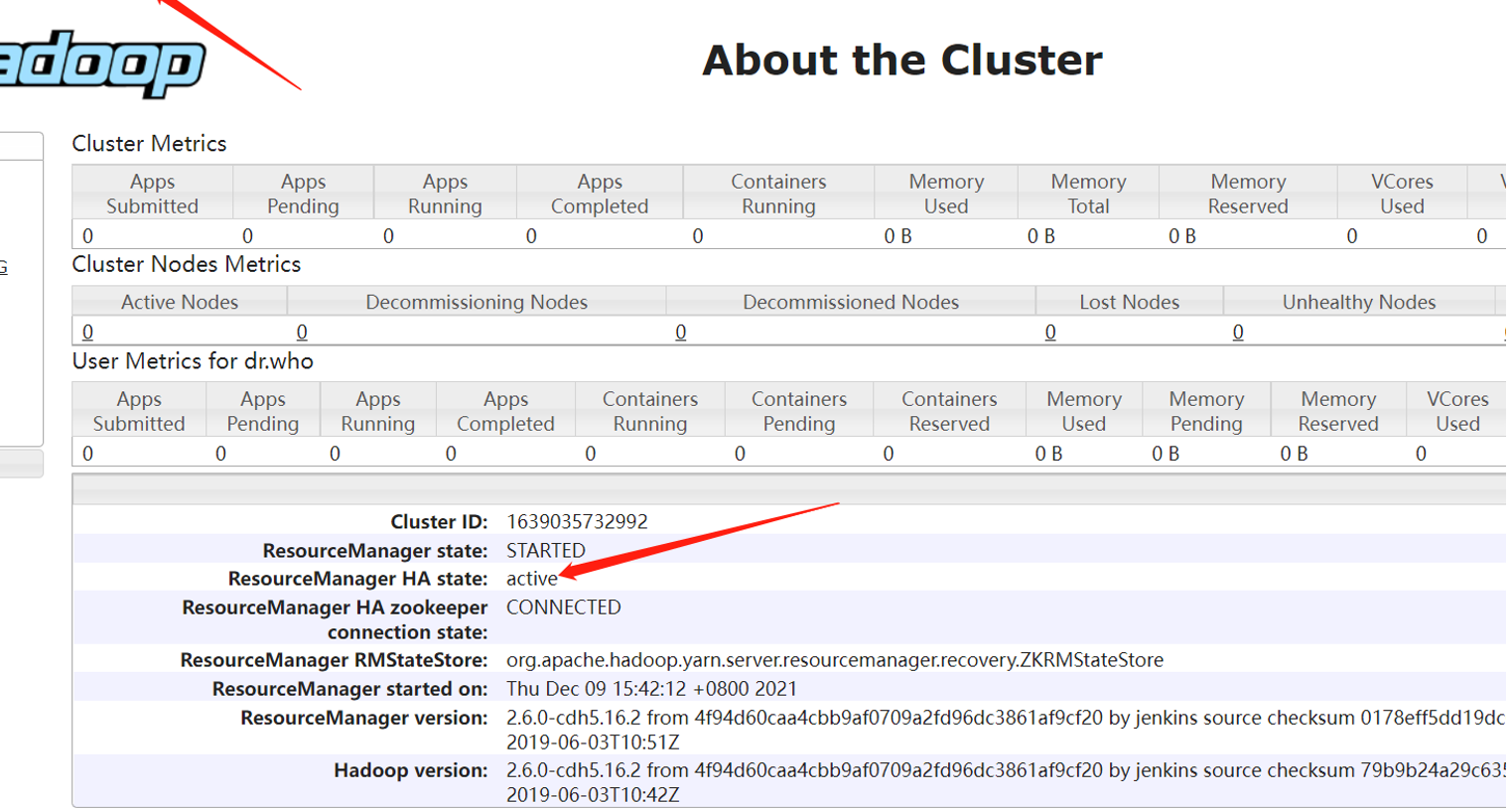
- 备RM自动切换,已经激活了
九、 单独启动某个服务:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
停止命令将start改成stop即可
十、 问题解决
l Namenode高可用失败
根据测试环境遇到的问题解决思路如下
#查看日志,namenode日志、zk日志 (zkfc)
/home/tom/hadoop/logs
#根据 namenode的日志查看可知是hdis-site xml 里的免密配置路径有问题,修正,
#再启动、杀掉 namenode(acvce)。浏览器查看备用服务器并没有激活
#查看 zkfc 日志.可以看出是ssh连接的时候:algorithm negotiation Fair错误,造成该问题
的原因是:ssh 升级后,为了安全,默认不再采用原来一些加密算法,既然没有了,那就手
动加迸去
步骤如下:
1 执行命令:ssh-Q cipher,查看支持的cipher用逗号隔开连接起来,如下:
Ciphers aes128-cbc,aes192-cbc,aes256-cbc,aes128-ctr,aes192-ctr,aes256-ctr,3des-cbc,arcfour128,arcfour256,arcfour,blowfish-cbc,cast128-cbc
2 执行命令:ssh-Q MACs,查看支持的MAC用逗号隔开连接起来,如下:
MACs hmac-md5,hmac-sha1,umac-64@openssh.com,hmac-ripemd160,hmac-sha1-96,hmac-md5-96
3 执行命令:ssh-Q KexAlgorithms,查看支持的KexAlgorithm用逗号隔开连接起来,如下:
KexAlgorithms diffie-hellman-group1-sha1,diffie-hellman-group14-sha1,diffie-hellman-group-exchange-sha1,diffie-hellman-group-exchange-sha256,ecdh-sha2-nistp256,ecdh-sha2-nistp384,ecdh-sha2-nistp521,diffie-hellman-group1-sha1,curve25519-sha256@libssh.org
#将前面3个命令的结果放到“/etc/ssh/sshd_config”文件最末尾
sudo vim /etc/ssh/sshd_config
#以下3行放到最末尾
Ciphers aes128-cbc,aes192-cbc,aes256-cbc,aes128-ctr,aes192-ctr,aes256-ctr,3des-cbc,arcfour128,arcfour256,arcfour,blowfish-cbc,cast128-cbc
MACs hmac-md5,hmac-sha1,umac-64@openssh.com,hmac-ripemd160,hmac-sha1-96,hmac-md5-96
KexAlgorithms diffie-hellman-group1-sha1,diffie-hellman-group14-sha1,diffie-hellman-group-exchange-sha1,diffie-hellman-group-exchange-sha256,ecdh-sha2-nistp256,ecdh-sha2-nistp384,ecdh-sha2-nistp521,diffie-hellman-group1-sha1,curve25519-sha256@libssh.org
#重启sshd服务器
sudo service sshd restart
#“start-dfs.sh”重新hdfs,杀掉active状态的namenode,备用namenode立即状态切换成功,问题解决

 浙公网安备 33010602011771号
浙公网安备 33010602011771号