

拟合回归树
这一节,我们尝试用另一种模型拟合数据,这种模型称作回归树(regression tree)
(https://en.wikipedia.org/wiki/Decision_tree_learning),它是一种机器学习模型。它不是简单
的线性回归,而是用决策树来拟合数据。
假设我们想根据太阳辐射(Solar.R)、平均风速(Wind)和日最高温度(Temp)来预
测每日空气质量(Ozone),并用内置数据集 airquality 作为训练集。图 7-34 展示了拟合的
回归树是如何运作的。
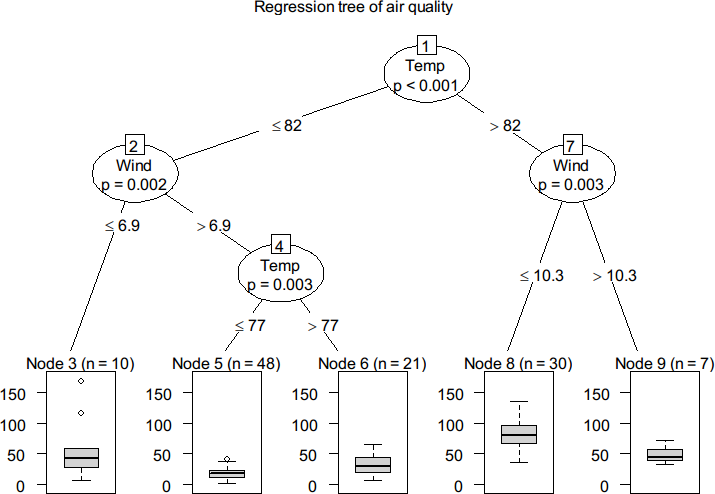
图 7-34
在回归树中,每个圆圈表示一个问题,这个问题有两个可能的答案。要预测空气质量
Ozone,我们需要沿着回归树从上到下地提出问题,最后每个观测数据都会落到最底端的
某一情形中。每个底部的结点都有与其他结点不同的分布,并且都用箱线图表示。每个箱
线图的中位数或均值就是考虑了各种情况的合理预测值。
其实,有很多扩展包可以实现决策树学习算法。在这里,我们用一个简单的扩展包 party
(https://cran.r-project.org/web/packages/party)。若还没安装该扩展包,运行install.packages
("party")进行安装。
现在我们使用同样的公式和数据来训练这个回归树模型。我们采用 air_time 没有缺
失值的部分数据,因为 ctree( )不接受带有缺失值的响应变量:
model4 <- party::ctree(air_time ~distance + month + dep_time,
data = subset(flights_train, !is.na(air_time)))
predict4_train <- predict(model4, flights_train)
error4_train <- flights_train$air_time -predict4_train[, 1]
evaluate_ _error(error4_train)
## abs_err std_dev
## 7.418982 10.296528
似乎 model4 比 model3 表现更好。接下来,我们看一下它的样本外表现:
predict4_test <- predict(model4, flights_test)
error4_test <- flights_test$air_time - predict4_test[, 1]
evaluate_ _error(error4_test)
## abs_err std_dev
## 7.499769 10.391071
以上输出结果表示,对于这个问题,平均来说,回归树能作出更好的预测。图 7-35 所
示的密度图将 model3 和 model4 的样本外预测的误差分布做出一个对比。
plot(density(error3_test, na.rm = TRUE),
ylim = range(0, 0.06),
main = "Empirical distributions of out-of-sample errors")
lines(density(error4_test, na.rm = TRUE), lty = 2)
legend("topright", legend = c("model3", "model4"),
lty = c(1, 2), cex = 0.8,
x.intersp = 0.6, y.intersp = 0.6)
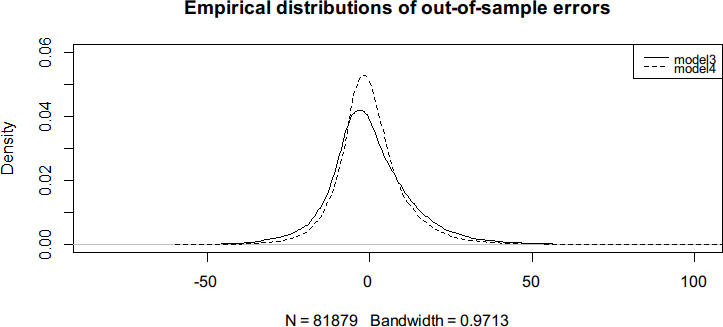
图 7-35
我们可以发现 model4 预测误差的方差比 model3 低。
上面的例子可能存在许多问题,因为我们在使用线性模型和机器学习模型时,没有认
真地检查数据。因为本章节的重点不是模型,而是向大家展示用 R 做模型拟合的一般流程
和对应接口。在解决实际问题时,你需要对数据做更仔细的分析,而不是直接套用任意一
个模型,然后得出结论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号