

一、判断oracle所在的服务器是 大端 还是 小端 (目前方法尽限Linux,AIX和UNIX的还在查找)
方法一
echo -n I | od -o | head -n1 | cut -f2 -d" " | cut -c6
- 输出:1为小端模式,0为大端模式;
- 解析:od命令的作用为将指定内容以八进制、十进制、十六进制、浮点格式或ASCII编码字符方式显示;
方法二
echo -n I | od -o | head -n1 | awk '{print $2}'| cut -c6
- 输出:1为小端模式,0为大端模式;
- 解析:awk命令为文本处理。
方法三
lscpu | grep -i byte
- 输出:Byte Order: Little Endian;
- 解析:grep -i 为不区分大小写匹配;
- 注意:在低版本的Linux可能不支持lscpu命令。
二、确认系统是32-bit还是64bit(大端、小端)
如下命令在mount下是可以执行的:
SYS @testdb> select PLATFORM_ID,PLATFORM_NAME from v$database;
PLATFORM_ID PLATFORM_NAME
----------- ------------------------------
13 Linux x86 64-bit
SYS @testdb> select * from v$transportable_platform;
PLATFORM_ID PLATFORM_NAME ENDIAN_FORMAT
----------- -------------------------------------------------- ------------------------------------------
1 Solaris[tm] OE (32-bit) Big
2 Solaris[tm] OE (64-bit) Big
7 Microsoft Windows IA (32-bit) Little
10 Linux IA (32-bit) Little
6 AIX-Based Systems (64-bit) Big
3 HP-UX (64-bit) Big
5 HP Tru64 UNIX Little
4 HP-UX IA (64-bit) Big
11 Linux IA (64-bit) Little
15 HP Open VMS Little
8 Microsoft Windows IA (64-bit) Little
9 IBM zSeries Based Linux Big
13 Linux x86 64-bit Little
16 Apple Mac OS Big
12 Microsoft Windows x86 64-bit Little
17 Solaris Operating System (x86) Little
18 IBM Power Based Linux Big
19 HP IA Open VMS Little
20 Solaris Operating System (x86-64) Little
21 Apple Mac OS (x86-64) Little
20 rows selected.
三、推进内存中的SCN
语法和过程:
startup mount oradebug setmypid oradebug DUMPvar SGA kcsgscn --查看当前内存中的SCN (这个内存中的SCN,控制文件的当前SCN,数据文件头的start SCN --具体是什么关系,暂时待定。) oradebug poke 【内存地址】 【长度】 【要修改的内容】
关于db中scn存储方式的解释:
scn=scnwrap * power(2,32) + scnbase (2^32 = 4294967296)
SCN分为两部分存储,scnwrap和scnbase,每当scnbase增长到2^32之后,scnwarp加1,然后scnbase清零。
scnwrap和scnbase都由4个字节组成,一共占用8字节。
(一个字节为8个bit,最小为0,最大为256,因此一个字节可以用两个16进制数(16*16)来表示,所以整个SCN显示出来应该是16个16进制数,两个16进制数表示一个字节。eg:0016CE5E 00000000)
在64-bit小字端中:前4位为scnbase,后4位为scnwrap
在64-bit大字端中:前4为为scnwrap,后4为为scnbase
根据以上的方法,修改对应的scnbase或者scnwrap就好。

由于我的系统是小字端,所以前4个字节为base,后4个字节为wrap
实验一: 修改scnbase

当前的SCN为 1357882
我们给他改成1500000

因为当前SCN和我们要更改的目标SCN都没有超过一个wrap,因此wrap位是0,更改base为16e360即可,因此我们从SCN地址06001AE70,往后推4位,为base。

再次查看更改后的SCN:

接下来启动数据库,查看SCN,我们预计是比1500000大一点的:

实验二: 更改scnwrap
2^32 = 4294967296 , 我们直接把 wrap更新为 10(hex A),base为0,这时候,我们预计开库后的SCN应该是 42949672960 大一点。
查看scn在内存中的地址位置

修改scnwrap为A,因为我们是小端,所以wrap为后四位,从地址位06001AE70+4 开始修改,后推4位:

其中 06001AE74 = 06001AE70 + 4
再次产看SCN:

wrap为10 , base为0
期待开库SCN为 2^32*10 = 42949672960 :
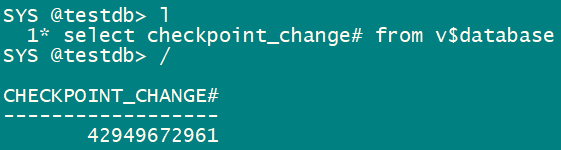
我看了好多更改SCN的文章,包括贴子,他们给定了一些规矩通用的计算方法,如下:
POKE计算方法
64位小字端,修改前8位:
select to_char(5080542,'xxxxxxxxx') from dual; --4d85de
oradebug poke 0x060019598 8 0x4d85de;
64位大字端,SCN WARP加1
select to_char(5080542,'xxxxxxxxx') from dual; --4d85de
oradebug poke 0x060019598 8 0x00000001004d85de;
32位小字端,POKE地址加4,修改后8位:
select to_char(5080542,'xxxxxxxxx') from dual; --4d85de
oradebug poke 0x06001959C 4 0x4d85de;
!!!但我想说的是,真正了解了 SCNbase 和SCNwrap 找到他们所在的位置,我就可以随心所欲的修改了。^_^

 浙公网安备 33010602011771号
浙公网安备 33010602011771号