

python网页自动化之第三方库-requests、selenium
认识网页
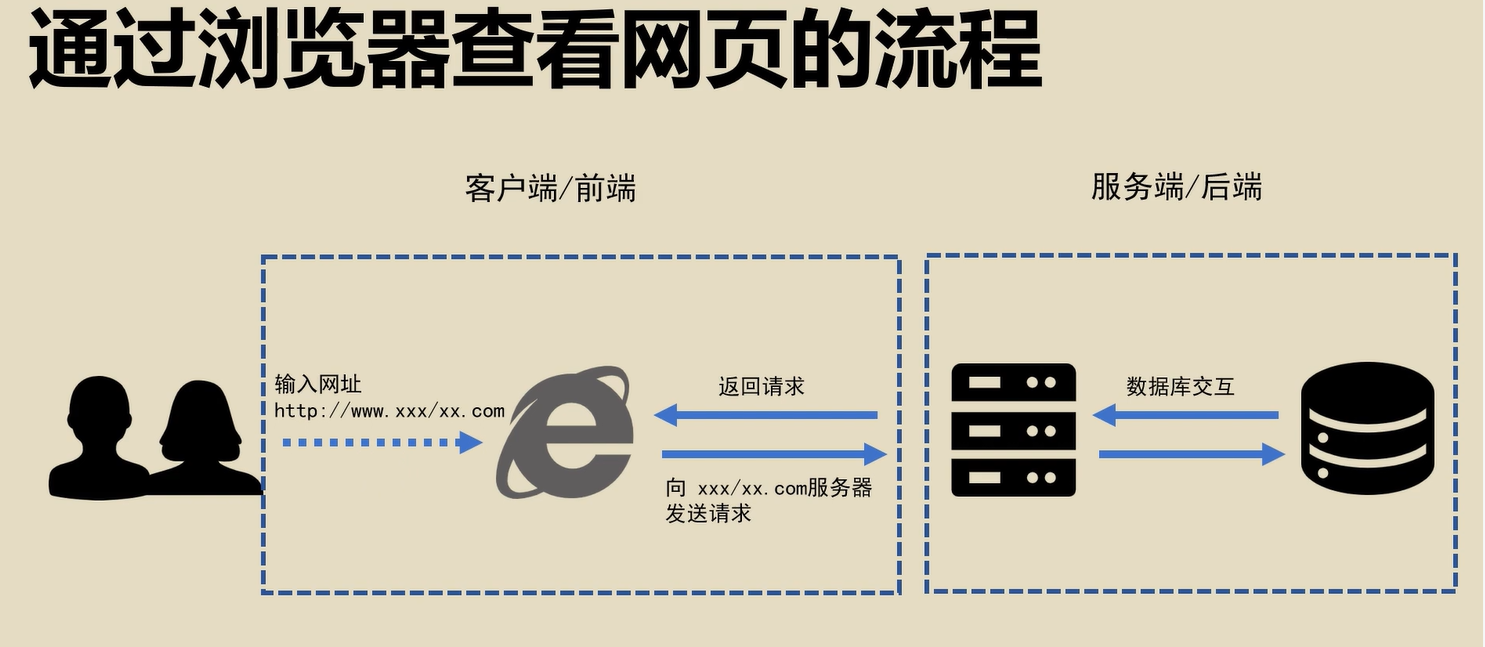
浏览器查看网页的过程
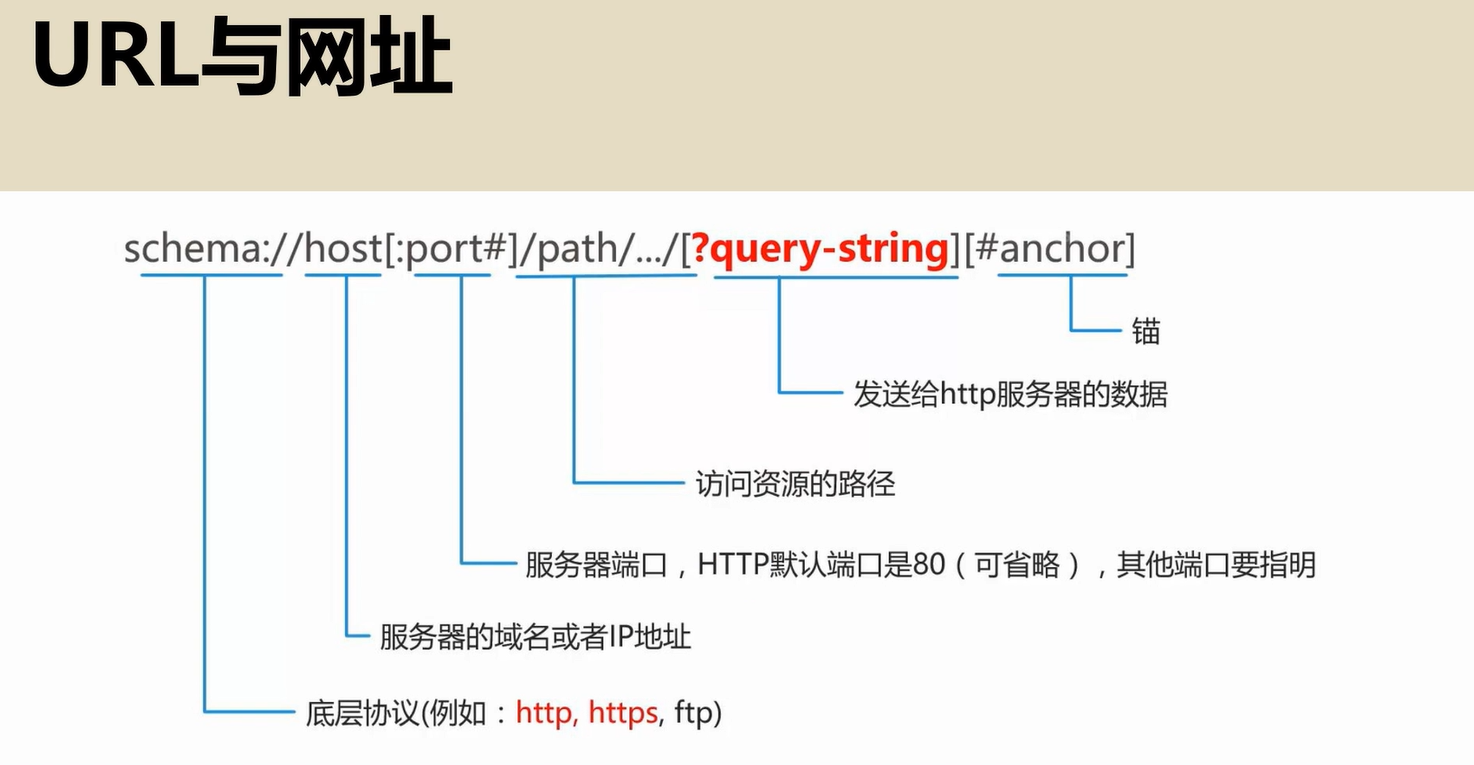
URL
http协议

https协议

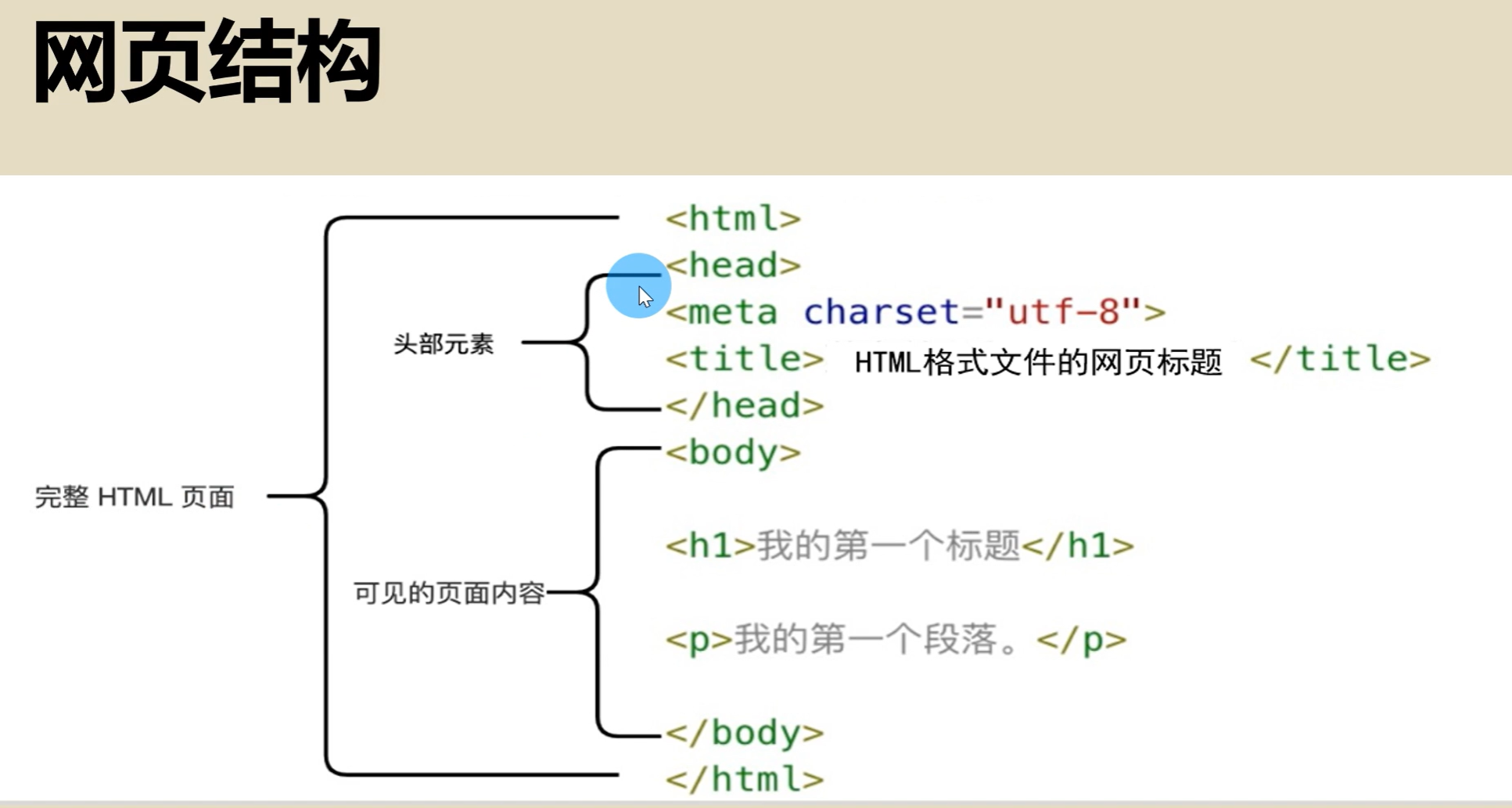
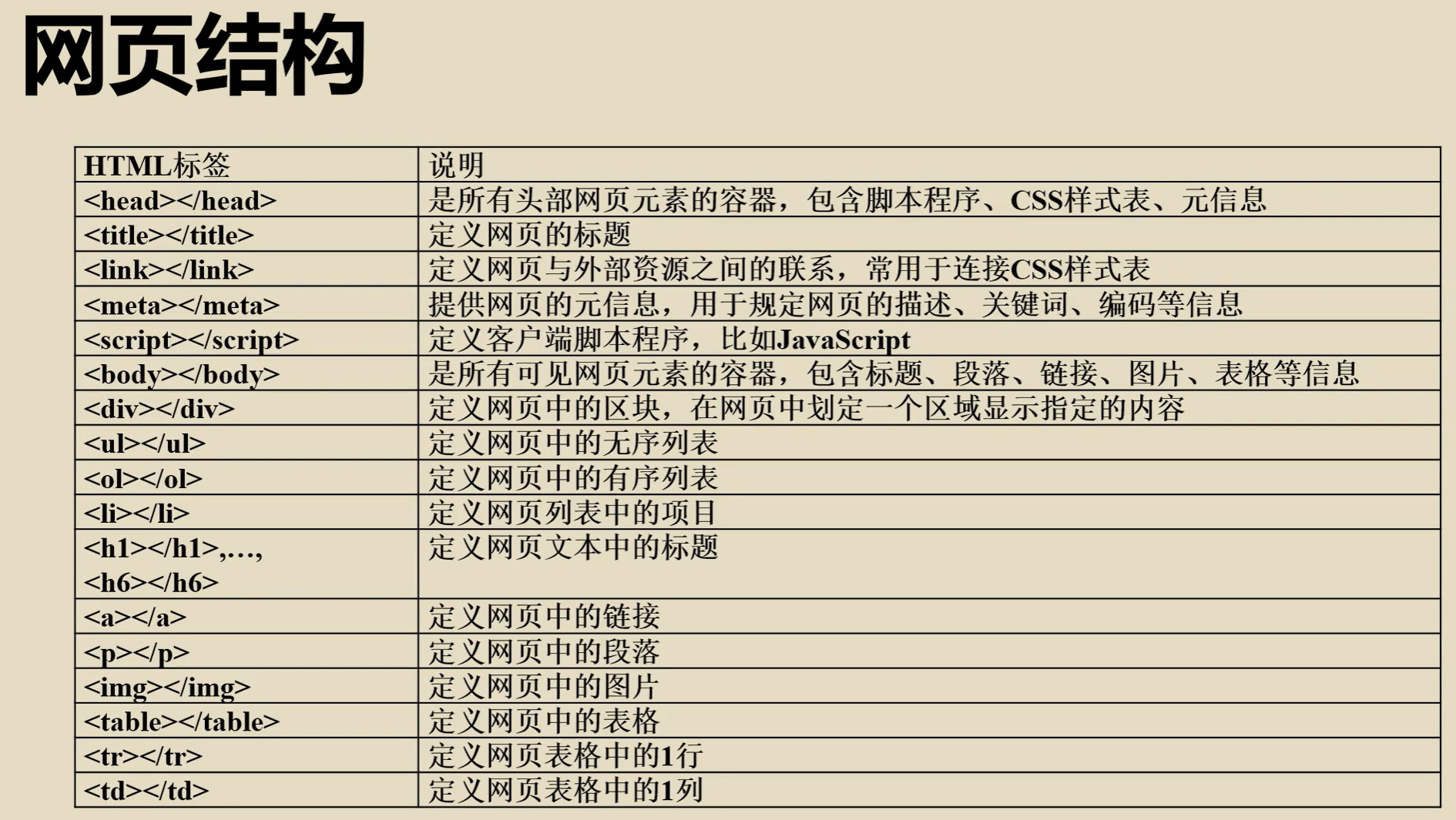
网页结构

requests库
爬取网页的三个模块

安装 requests库
1、查看是否已经安装
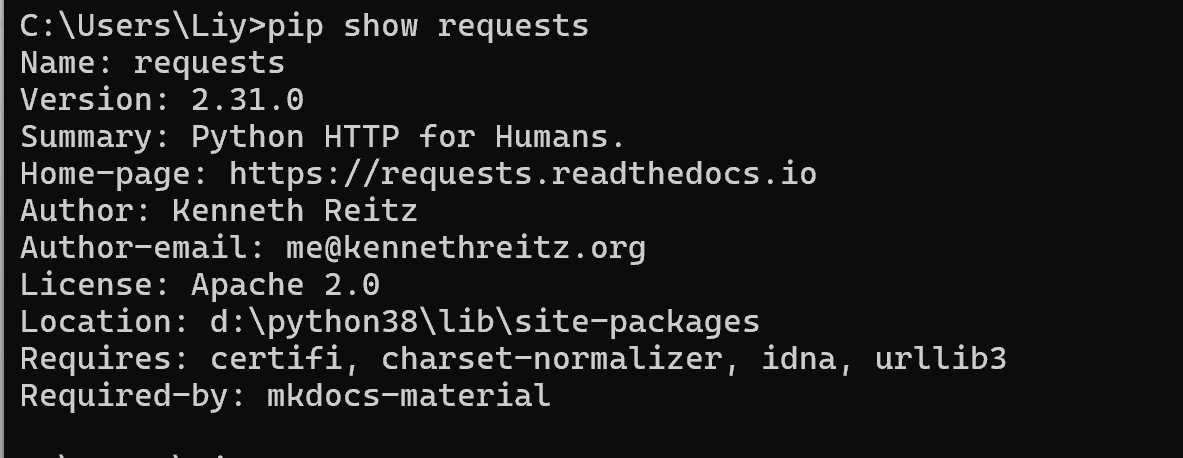
2、如果未安装

发送HTTP协议GET请求

练习7-1
import requests
response = requests.get('https://www.baidu.com')
print(response.status_code) #状态码
print(response.url) #请求url
print(response.headers) #头部信息
print(response.cookies) #cookie信息
coding = response.encoding #网页源代码编码方式
print(coding)
result = response.text #网页源代码
result = result.encode(coding).decode('utf-8') #将源代码按照原来编码方式转换为二进制,再进行utf-8编码
print(result)
设置请求头信息
获取请求头信息
通过浏览器开发者工具获取网页请求头信息,通过仿照请求头爬取信息
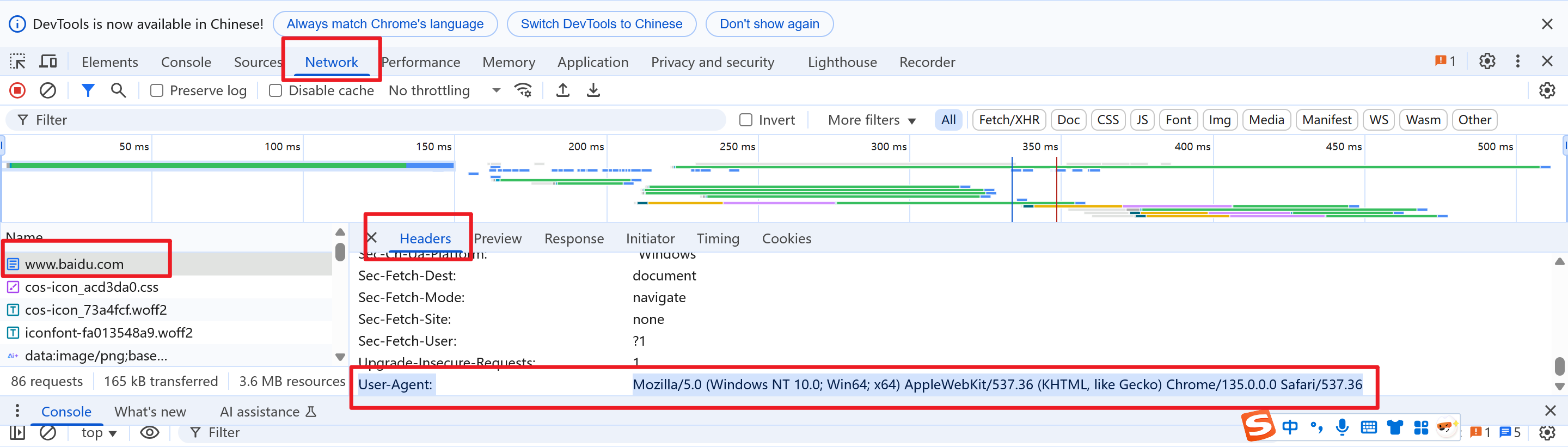
设置请求头信息,用于绕过反爬

练习7-2

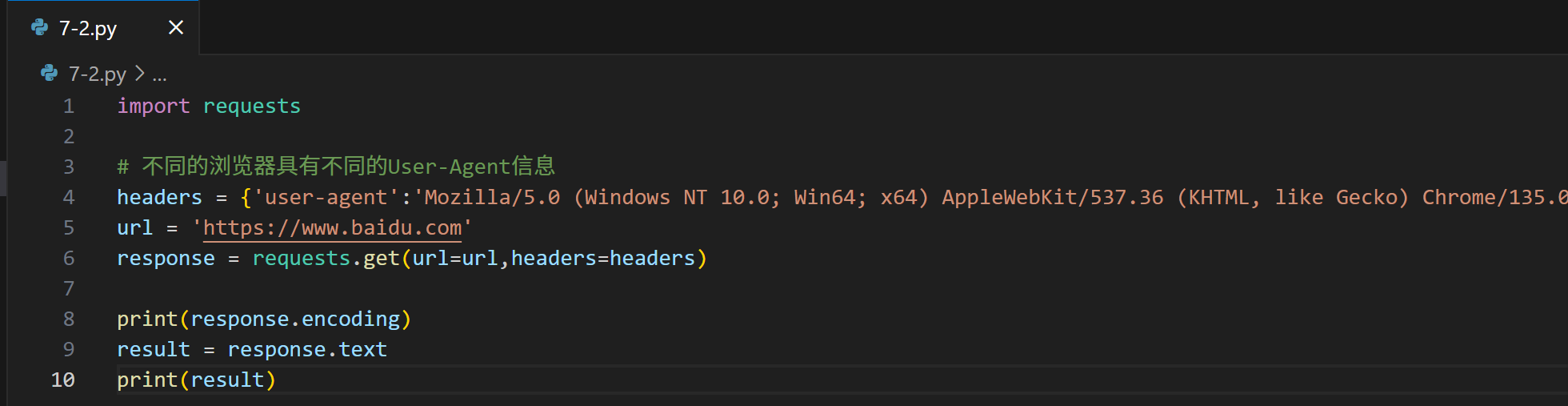
添加请求头信息后,获取的反馈信息明显变多了
网站反爬虫,无请求头编码ISO-8859-1,有请求头编码UTF-8
想要获取网页全面的信息必须添加请求头信息
response对象属性和方法

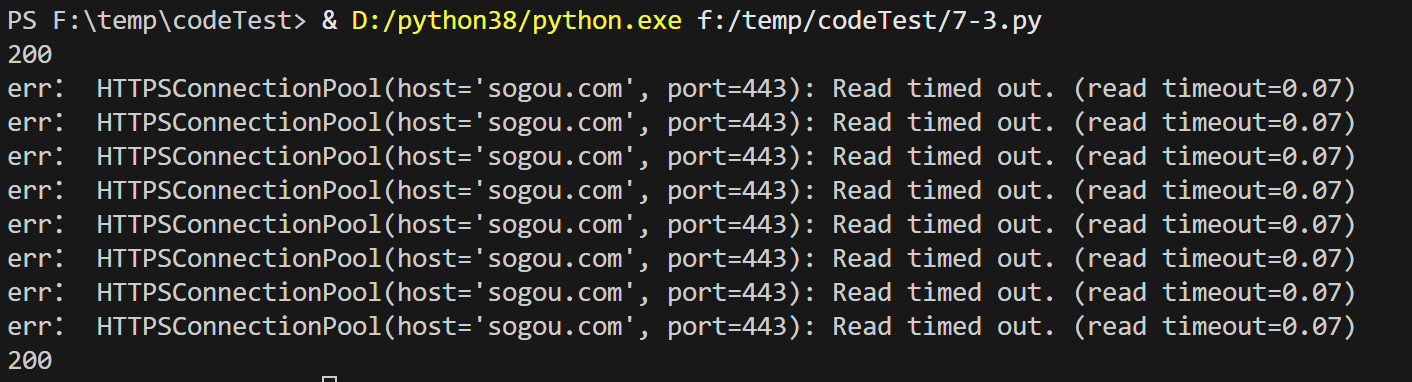
网页超时

实践演示

import requests
url = 'https://sogou.com' #设置访问url地址
for i in range(10): #循环访问url地址十次
try:
response = requests.get(url=url,timeout=0.07) #超过0.07秒视为网页访问超时
print(response.status_code) #输出响应码
except Exception as e:
print('err:',e) #打印报错信息
运行结果
requests下载图片
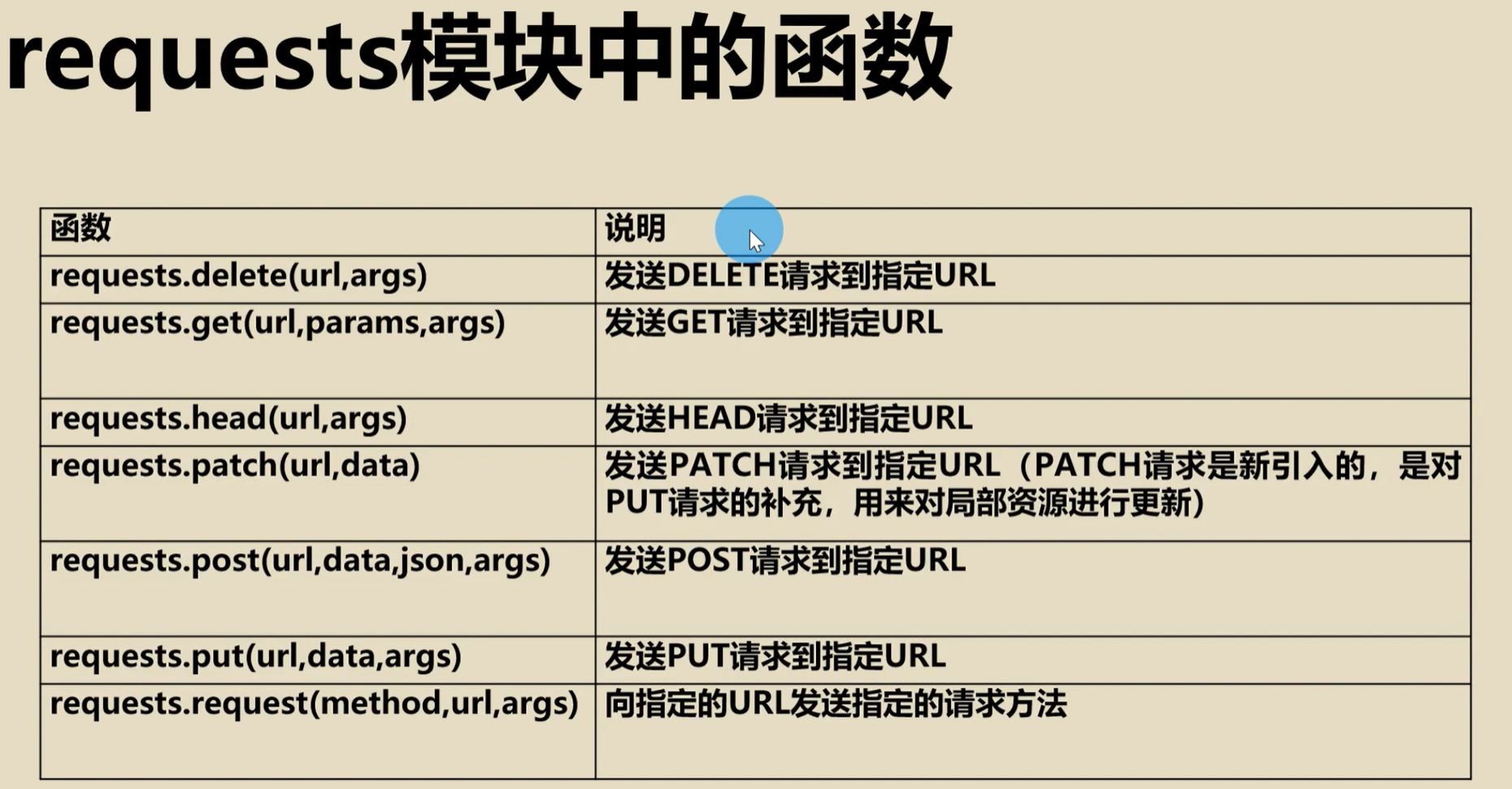
requests模块中的函数
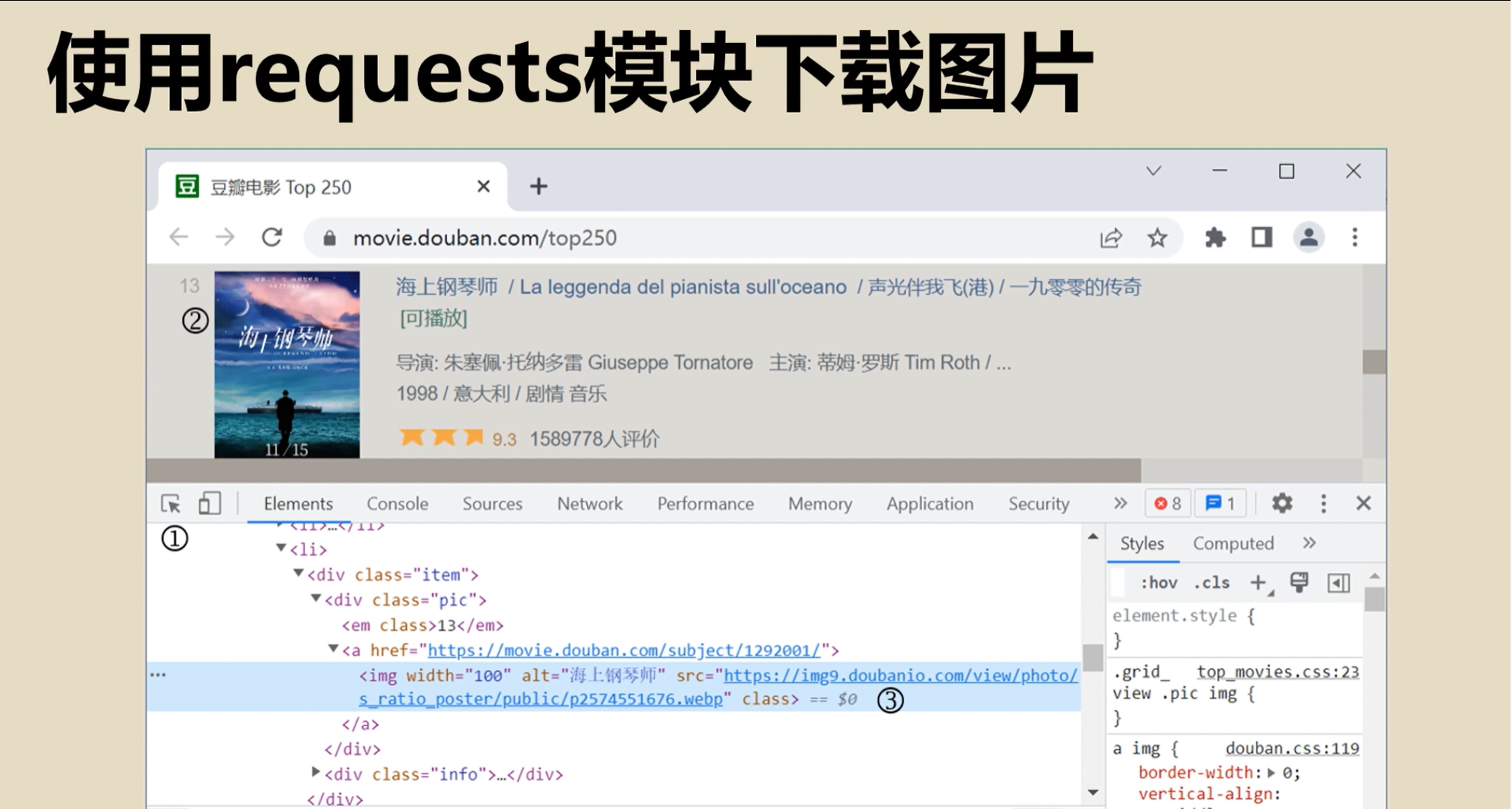
requests模块下载图片
豆瓣电影海上钢琴师为例,开发者工具找到图片地址代码,通过获取字节流下载图片

import requests
response = requests.get('https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2914698334.webp')
img1 = response.content
with open('F:\\temp\\codeTest\\img1.jpg','wb') as f:
f.write(img1)
requests模块使用正则表达式解析网页
正则表达式基本知识
正则表达式(RegularExpression)是一种可以用于模式匹配和替换的强有力的工具,是由一系列普通字符和特殊字符组成的能明确描述文本字符的文字匹配模式。
使用正则表达式可以提取和替换字符串中符合某种模式的子字符串。
正则表达式常用的普通字符

正则表达式常用的元字符

使用re模块应用正则表达式
使用re模块中的findallO函数可以在整个字符串中搜索符合正则表达式的字符串,并以列表的形式返回 re.findall(pattern,string,[flags])
pattern:表示匹配模式,主要由正则表达式构成;
string:表示要匹配的字符串;
flags:可选参数,表示标志位,用于控制匹配方式,比如是否区分大小写。


import re
str1 = "12345We_!@#你好"
match1 = re.findall('\w',str1)
match2 = re.findall('\W',str1)
print(match1)
print(match2)
使用正则表达式解析网页


import re
import requests
# 网页头
headers = {网页头}
# 网址
url = 'https://www.baidu.com'
# 发送GET请求获取网页内容
response = requests.get(url = url, headers = headers)
# 获取响应文本
result = response.text
# 正则表达式模式
pattern=r'<span class="title-content-title">(.*?)</span>'
# 使用正则匹配所有符合条件的内容
match1 = re.findall(pattern,result,re.S)
# 输出匹配结果
print(match1)


import re
import requests
hearders = {网页头}
url = 'https://www.cnblogs.com/'
responds = requests.get(url=url,headers=hearders)
result = responds.text
# 网页使用非贪婪模式匹配
pattner = r'<a class="post-item-title" href=".*?" target="_blank">(.*?)</a>'
match1 = re.findall(pattner,result,re.S)
print(match1)

reguests模块的不足
使用requests模块获取的是未经渲染的网页信息,不能获取动态渲染的网页信息。
selenium模块
selenium模块和浏览器驱动安装
一、安装 selenium模块
pip install selenium
安装慢挂梯子,或者找国内镜像
二、安装谷歌浏览器驱动
1)查看谷歌浏览器版本
地址栏输入:chrome://version/

2)安装对应版本驱动
# 谷歌浏览器驱动下载地址
https://googlechromelabs.github.io/chrome-for-testing/#stable
3)将谷歌浏览器驱动复制到python.exe路径下面
a、命令行窗口输入:where python 查询python.exe路径
b、将谷歌浏览器驱动复制到python.exe路径下面

c、命令行窗口输入:chromedriver 测试驱动是否安装成功

实验8-1
使用 selenium模块控制谷歌驱动使用谷歌浏览器访问百度官网
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 指定chrome浏览器驱动路径
webDriverPath = "F:\\codeTest\\autoWeb\\chromedriver-win64\\chromedriver.exe"
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
browser = webdriver.Chrome(service=Service(webDriverPath))
# 打开百度浏览器
browser.get('https://www.baidu.com')
# 4.加上这一句,防止代码跑完之后,运行结束关闭浏览器
input()
selenium模块获取网页源代码

实验8-2

from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 指定chrome浏览器驱动路径
webDriverPath = "F:\\codeTest\\autoWeb\\chromedriver-win64\\chromedriver.exe"
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
browser = webdriver.Chrome(service=Service(webDriverPath))
# 访问指定网址获取网页源代码,并打印
url = 'https://finance.sina.com.cn/realstock/company/sh000001/nc.shtml'
browser.get(url)
result = browser.page_source
print(result)
可以获取网页动态渲染的网页信息
设置无界面的浏览器模式

实验8-3

浏览器对象的方法和属性

使用Selenium模块模拟鼠标和键盘操作
确定Selenium模块的版本号
# 命令行窗口输入:pip show selenium
# python代码
import selenium
# 输出 selenium模块版本号
print(selenium.__version__)
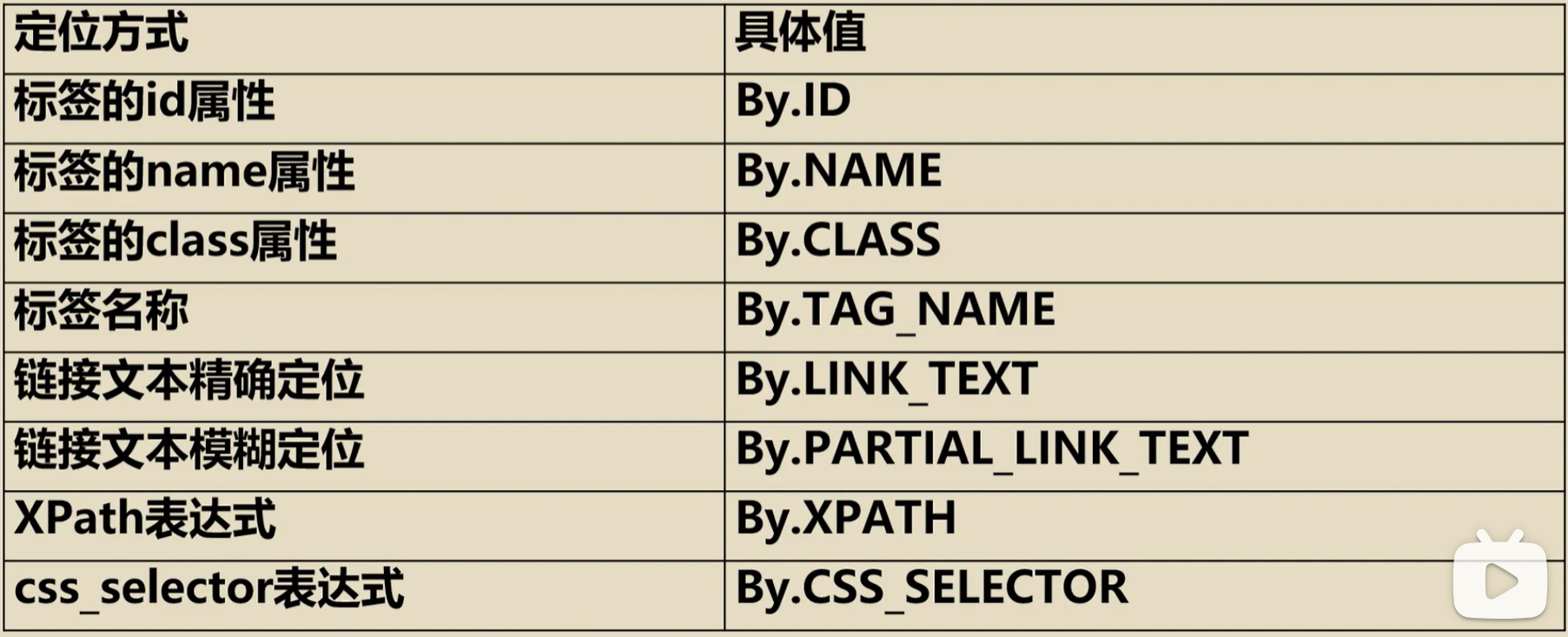
定位网页元素的第一种方法

参数By.ATTRIBUTE的具体值
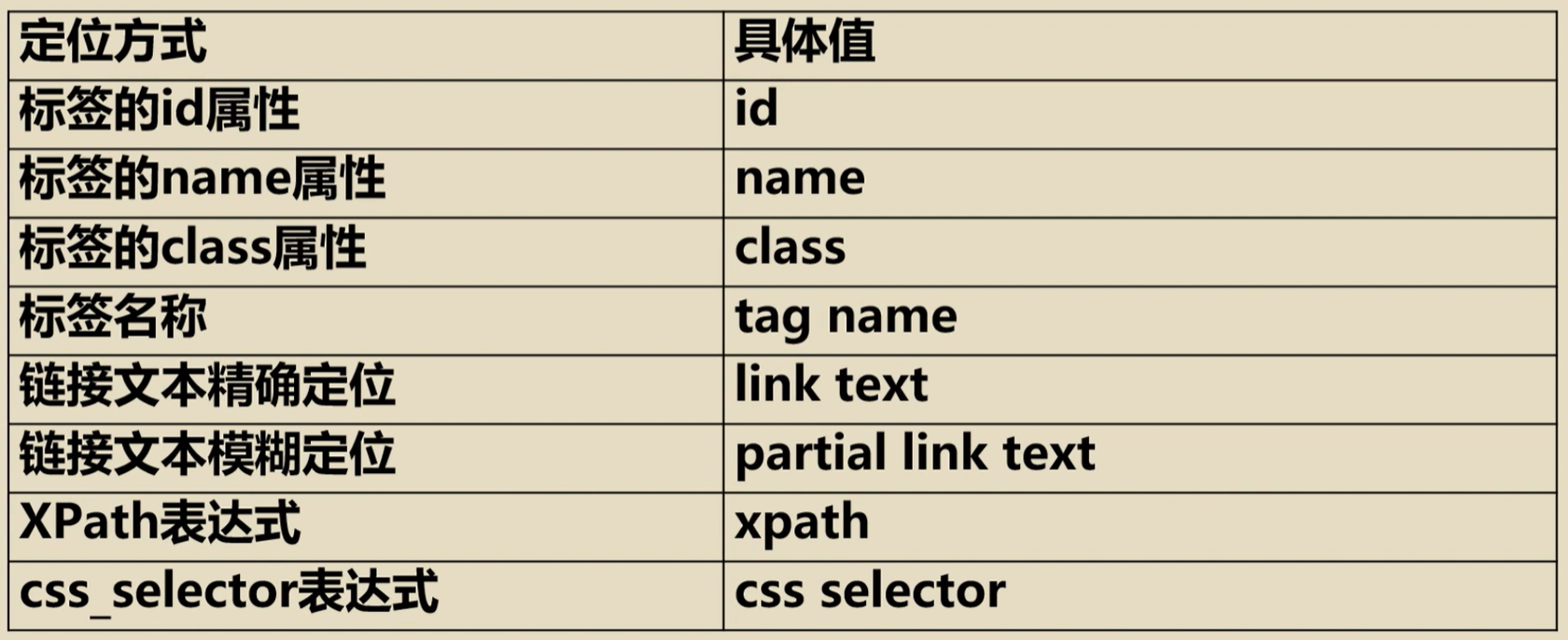
定位网页元素的第二种方法

参数attribute的具体值
实验8-4

from selenium.webdriver.chrome.service import Service
import time
# 指定chrome浏览器驱动路径
webDriverPath = "F:\\codeTest\\autoWeb\\chromedriver-win64\\chromedriver.exe"
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
browser = webdriver.Chrome(service=Service(webDriverPath))
# 指定要访问的网址
url = 'https://www.baidu.com'
browser.get(url)
# 搜索栏输入“两会”关键词
browser.find_element('xpath','//*[@id="kw"]').send_keys('两会')
time.sleep(5)
# 点击“百度一下”按钮
browser.find_element('xpath','//*[@id="su"]').click()
time.sleep(8)
实验8-5

# 指定chrome浏览器驱动路径
webDriverPath = "F:\\codeTest\\autoWeb\\chromedriver-win64\\chromedriver.exe"
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
browser = webdriver.Chrome(service=Service(webDriverPath))
# 指定要访问的网址
url = 'https://www.sogou.com/'
browser.get(url)
# 搜索栏输入“两会”关键词
browser.find_element('css selector','#query').send_keys('两会')
time.sleep(5)
# 点击“百度一下”按钮
browser.find_element('css selector','#stb').click()
time.sleep(8)
selenium模块不同版本说明

4.5版本保持浏览器常开,4.8及其以后得版本保持浏览器长关,也就是执行完代码后浏览器会自动关闭,可以使用如下代码保持浏览器常开。
实验8-6
浏览器常开
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# 关键配置:添加浏览器保持打开的选项
chrome_options = Options()
# 让浏览器在脚本结束后保持打开
chrome_options.add_experimental_option("detach", True)
# 指定chrome浏览器驱动路径
webDriverPath = "F:\\codeTest\\autoWeb\\chromedriver-win64\\chromedriver.exe"
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
browser = webdriver.Chrome(service=Service(webDriverPath), options=chrome_options)
# 指定要访问的网址
url = 'https://www.sogou.com/'
browser.get(url)
# 搜索栏输入“两会”关键词
browser.find_element('css selector','#query').send_keys('两会')
# 点击“百度一下”按钮
browser.find_element('css selector','#stb').click()
关闭网页:browser.quit()
requests模块和selenium模块的对比
1)Selenium模块可以爬取动态渲染网页的源代码,可以模拟键盘和鼠标操作,可以定位网页元素,代码比较简洁,但爬取速度比较慢。
2)requests模块不能爬取动态渲染的网页信息,但爬取速度比较快。
3)requests模块和Selenium模块的对比在实际应用中,一般优先考虑requests模块爬取网页,对于requests模块无法爬取的复杂网页,再使用Selenium 模块爬取。
本文来自博客园,作者:南舟树,转载请注明原文链接:https://www.cnblogs.com/nanzhoushu/p/18863946

 浙公网安备 33010602011771号
浙公网安备 33010602011771号