
Socially-Aware Self-Supervised Tri-Training for Recommendation
SEPT
Socially-Aware Self-Supervised Tri-Training for Recommendation
ABSTRACT
自监督学习(Self-supervised learning, SSL)可以从原始数据中自动生成真实样本。
现有的大多数基于SSL方法的做法是:丢弃原本的节点\边对原始数据图进行干扰,生成新的数据视图,然后对不同的视图进行基于自判别的对比学习,学习泛化表示;
这个方案下,两个不同视图的节点之间只建立了一个双射映射,这意味着忽略了来自其他节点的自监督信号;
由于在推荐系统中广泛观察到的同源性,文章认为来自其他节点的监督信号也极有可能利于推荐系统的学习;
文章提出了一种综合了tri-training的通用社会性感知SSL框架。该框架首先使用用户社交信息来增强用户数据视图
在多视图编码的tri-training下,该框架在扩展视图的基础上构建了三图编码器,并利用其他两个编码器产生的来自其他用户的自监督信号来改进每个编码器;
INTRODUCTION
文章使用user-user和user-item交互中的三元结构来扩充两个补充数据视图,并将它们分别解释为描述用户在扩大社交圈和将所需项目分享给朋友方面的兴趣。
技术上,首先在三个视图上构建三个非对称图形编码器,其中两个仅用于学习用户表示并给出伪标签,而另一个处理用户-项目视图的编码器,还承担生成推荐的任务。对社交网络和用户-项目交互图进行动态扰动,以此创建一个未标记的样本集。遵循tri-training的机制,在每个十七,在其他两个视图上的编码器为当前视图的每个用户预测未标记示例集中最可能的语义正示例。该框架通过提出的基于邻域区分的对比学习,最大化当前视图中标记用户的表示与示例集之间的一致性,从而精化用户表示。
随着所有编码器在此过程中迭代改进,生成的伪标签也变得更具有信息性,反过来又递归地是编码器受益。因此,与只使用自区分SSL机制增强的推荐编码器相比,用户项目视图上的推荐编码器变得更强。
由于tri-training基于相同数据源的互补视图来学习自监督信号,因此将其命令为自监督tri-training。
2 RELATED WORK
2.1 Graph Neural Recommendation Models
2.2 Self-Supervised Learning in RS
3 PROPOSED FRAMEWORK
SEPT, SElf-suPervised Tri-training framework
3.1 Preliminaries
3.1.1 Notations
使用两个图,分别为:用户-项目交互图\(\mathcal{G}_r\),用户社交网络\(\mathcal{G}_s\)
\(\mathcal{U}=\{u_1,u_2,\ldots,u_m\}(|\mathcal{U}|=m)\)表示\(\mathcal{G}_r\)和\(\mathcal{G}_s\)中的用户节点
\(\mathcal{I}=\{i_1,i_2,\ldots,i_n\}(|\mathcal{I}|=n)\)表示\(\mathcal{G}_r\)中的项目节点
\(R\in \mathbb{R}^{m\times n}\)是\(\mathcal{G}_r\)的二进制矩阵
\(S\in \mathbb{R}^{m\times m}\)表示社交邻接矩阵,这个矩阵是二进制和对称的
\(P\in \mathbb{R}^{m\times d}\)和\(Q\in \mathbb{R}^{n\times d}\)分别表示用户和项目的embeddings
3.1.2 Tri-Training
3.2 Data Augmentation
3.2.1 View Augmentation
推荐系统中广发观察到的同质性,即,用户和项目有许多相似的对应物。为了捕获同质性以进行自监督,文章利用用户社交关系来进行数据扩充,因为社交网络通常被认为是同质性的反映(具有相似偏好的用户更有可能在社交网络中建立连接,反之亦然)
下图是SEPT的示意图:
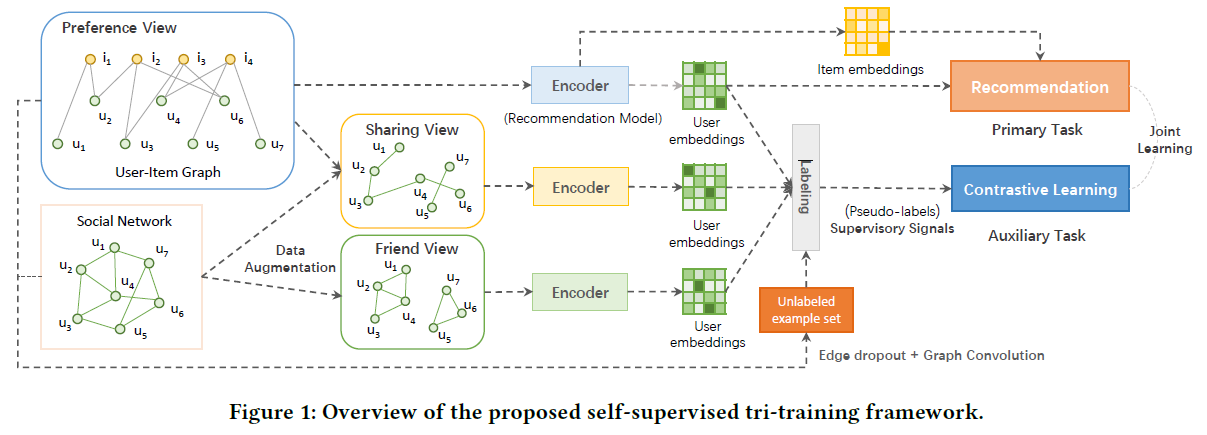
在社交推荐系统中,通过对齐用户-项目交互图\(\mathcal{G}_r\)和社交网络\(\mathcal{G}_s\),可以获得两种类型的三角形:
- 三个相互社交连接的用户(例如,上图中的\(u_1,u_2,u_4\))
- 具有相同购买物品的两个社交连接用户(例如,上图中的\(u_1,u_2,i_1\))
前者在社会上被解释为通过扩大社交圈来描述用户的兴趣,后者则是描述用户在与朋友分享所需物品方面的兴趣。
可以把这两种三角形视为加强的纽带,因为如果两个人在现实生活中有共同的朋友或共同的兴趣,他们更有可能有密切的关系
上述两种类型的三角形可以用矩阵乘法的形式有效地提取出来。让\(A_f\in \mathbb{R}^{m\times m}\),\(A_s\in \mathbb{R}^{m\times m}\)表示结合了两种类型三角关系的邻接矩阵,计算公式如下:
乘法\(SS(RR^\top)\)通过共享好友(项目),累计连接两个用户的路径数。哈达玛积\(\odot S\)使得这些paths变成三角形形式。\(\odot S\)保证\(A_f,A_s\)是关系S的子集。因为\(A_f,A_s\)不是二进制矩阵,公式(1)可以看成一种特殊的情况:在有R的补充信息的S上进行bootstrap采样。
- bootstrap sampling:是生成一系列bootstrap伪样本,每个样本是初始数据有放回抽样
给定\(A_f,A_s\)作为S和R的扩展,就有了三个视图从不同的角度描述了用户的偏好,并提供了一个融合tri-training和SSL的场景。将三个视图命名为:
- preference view(用户-项目交互图),用R表示
- friend view(三角形社交关系),用\(A_f\)表示
- sharing view(三角形用户项目关系),用\(A_s\)表示
3.2.2 Unlabeled Example Set
为了进行tri-training,需要一个位标记的样本集,遵循已有的工作,以一定概率\(\rho\)丢弃边,来扰动原始图,从而创建一个损坏图,从中学习到的用户描述被用作未标记的样例。公式如下:
其中\(\mathcal{N}_r,\mathcal{N}_s\)是节点,\(\varepsilon_r,\varepsilon_s\)是\(\mathcal{G}_r,\mathcal{G}_s\)的边,\(m\in \{0,1\}^{|\varepsilon_r\cup \varepsilon_s|}\)是mask向量来去除边。
- \(\mathcal{G}=(\mathcal{W},\mathcal{\varepsilon},\mathcal{R})\)是图的表示形式,\(\mathcal{W}\)是节点,\(\varepsilon\)是边,\(\mathcal{R}\)是关系
在这里对\(\mathcal{G}_r,\mathcal{G}_s\)都进行扰动,因为在前面提到的两个增强视图都包含了社交信息。
3.3 SEPT:Self-Supervised Tri-Training
3.3.1 Architecture
利用增强的视图和未标记的样本集,按照tri-training的设置构建了三个encoder。在体系结构上,提出的自监督训练框架可以是模型无关的,从而可以推广到其他的图神经推荐模型。文章使用了LightGCN作为编码器的基本结构,编码器的定义如下:
其中,H是encoder,\(Z\in \mathbb{R}^{m\times d}\) or \(\mathbb{R}^{(m+n)\times d}\)表示节点的最终表示。E具有相同的size,表示最底层的初始节点embeddings,\(\mathcal{V}\in \{R,A_s,A_f\}\)是三个视图中任一个。
SEPT是非对称的,\(H_f,H_s\)分别工作在friend view和sharing view,有两个作用:
- 学习用户表示
- 给出伪标签
\(H_r\)工作在preference view,承担推荐的任务,从而学习用户和项目表示
\(H_r\)是主要编码器,\(H_f,H_s\)是辅助编码器。这三个编码器都使用LightGCN。此外,为了从扰动图\(\tilde{\mathcal{G}}\)中学习未标记示例的表示,需要另外一个encoder,但它仅用于图卷积。
3.3.2 Constructing Self-Supervision Signals
通过对三个视图执行图卷积,encoder学习三组用户表示。由于每个视图反映了用户偏好的不同方面,自然会从其他两个视图中寻找监督信息,以改进当前视图的encoder。给定一个用户,文章使用来自其他两个视图的用户表示来预测其在未标记示例集中的语义正示例,以偏好视图中的用户u为例,标签表示为:
其中\(\phi\)是cosine操作,\(z_u^s,z_u^f\)是\(H_s,H_f\)学习的用户u表示,\(\tilde{Z}\)是图卷积获得的无标签示例集中的用户表示,$$表示在相应视图中每个用户在语义上是正例的预测概率。
tri-training机制下,只有\(H_s,H_f\)都同意将用户标记为正样本时,才标记,于是公式如下:
有了这些概率,可以选择置信度最高的K个阳性样本,公式如下:
在每次迭代中,对于不用的用户表示,使用随机边丢弃来重建\(\tilde{\mathcal{G}}\)。SEPT为每个视图中的每个用户动态地在该数据扩充上生成正的伪标签。然后,将这些标签用作监督信号,以此精化底层的embeddings
3.3.3 Contrastive Learning
有了生成的伪标签,在SEPT中开发了邻居区分对比学习方法来实现自监督。
在给定某个用户的情况下,要求他的节点表示与\(\mathcal{P}_{u+}\)中已标记的用户表示保持一致,并最小化其节点表示与未标记的用户表示之间的一致性。用户判别的思想是:给出当前视图的一个用户u,正向伪标签是这个用户u在另外两个视图的邻居或者潜在邻居,那么应该在当前的视图中把这些积极的配对,因为不同的观点之间存在同质性。这可以通过邻居-分歧对比学习来完成。具体实现采用以前的研究成果,InfoNCE,公式如下:
其中\(\psi(z_u^v,\tilde{z}_p)=exp(\phi(z_u^v\cdot \tilde{z}_p)/\tau),\phi(\cdot):\mathbb{R}^d\times \mathbb{R}^d\longmapsto \mathbb{R}\)是判别函数,\(\tau\)是方法判别效果的参数(\(\tau=0.1\)时效果最好)。相比自判别,使用邻居判别能够使用来自其他用户的监督信号。
当只使用一个正向示例,并且如果\(\tilde\)中用户在\(y_{u+}\)对自己有最高置信度时,邻居判别退化成自我判别。但是当正例的数量足够时,这两种方法可以一起使用。
实验训练过程中,没有将伪标签添加到邻接矩阵中用于后续的图卷积。相反,采用软而灵活的方式通过互信息最大化来指导用户表示。有两个好处:
- 重建邻接矩阵耗时长
- 早期的伪标签不会提供信息,重复使用会误导模型
3.4 Optimization
SEPT包含两个任务:
- recommendation
- neighbor-discrimination based on contrastive learning
BPR损失函数如下:
其中\(\mathcal{I}(u)\)是与u有交互的项目,\(\hat{r}_{ui}=P^\top_uQ_i\),P和Q从\(Z^r\)中获得,\(\lambda\)控制\(L_2\)正则化的系数。
SEPT的训练过程有两个阶段:
- 初始化
- 联合学习
首先通过优化\(\mathcal{L}_r\),使用推荐任务来预热模型,获得较好的embeddings后,自监督tri-training训练开始进行,作为辅助任务统一为联合学习目标,提高推荐任务的效果,联合学习的总体目标如下:
3.4 Discussion
4 EXPERIMENTAL RESULTS
4.1 Experimental Settings
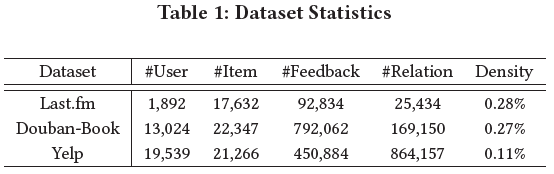
使用的数据集如下:
Baselines
- LightGCN
- DiffNet++
- MHCN
Metrics
- Precision@10
- Recall@10
- NDCG@10
Settings
4.2 Overall Performance Comparison
表2展示了不同层数的实验效果,如下:
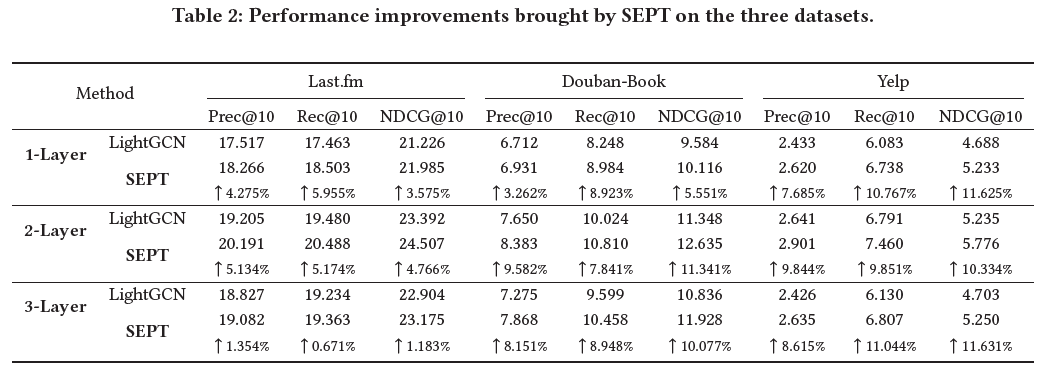
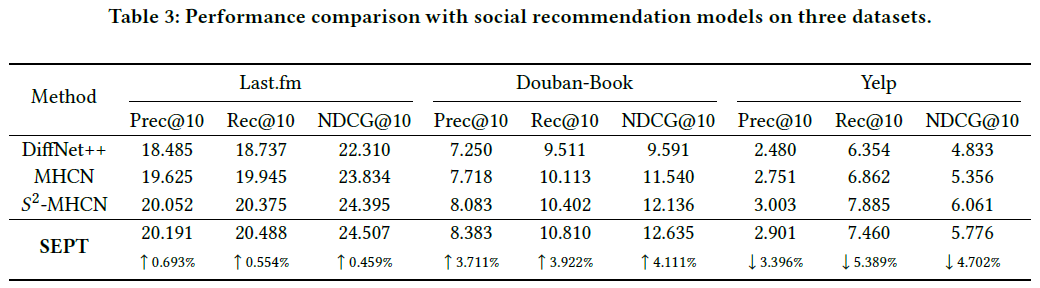
表3中所有方法都采用了两层设置,如下:
4.3 Self-Discrimination v.s. Neighbor-Discrimination
SEPT中,产生的正向示例会包括:
- 用户自身
- 未标记的样本集
此部分探究用户的自判别和没有用户自身的邻居判别。SEPT-SD表示自判别,SEPT-ND表示没有用户自身的邻居判别。实验结果如下图:
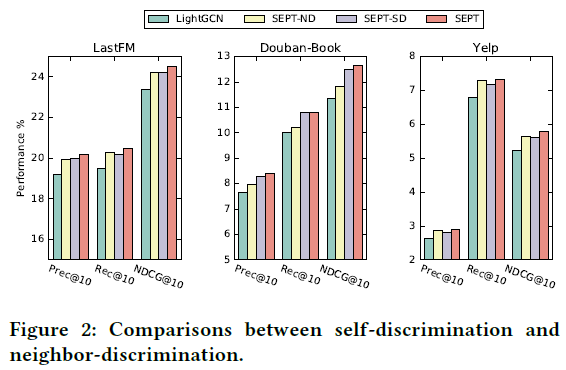
4.4 View Study
此部分研究两个增强视图的贡献,"Friend" or "Sharing"表示对应的视图被分离,实验结果如下图:
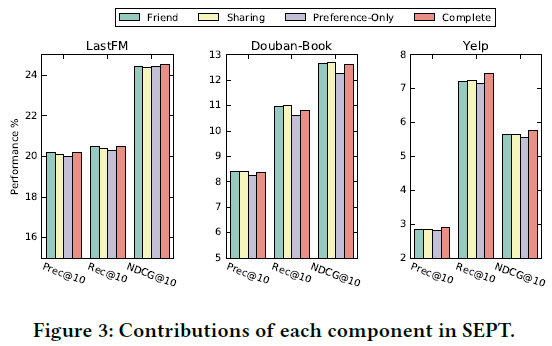
4.5 Parameter Sensitivity Analysis
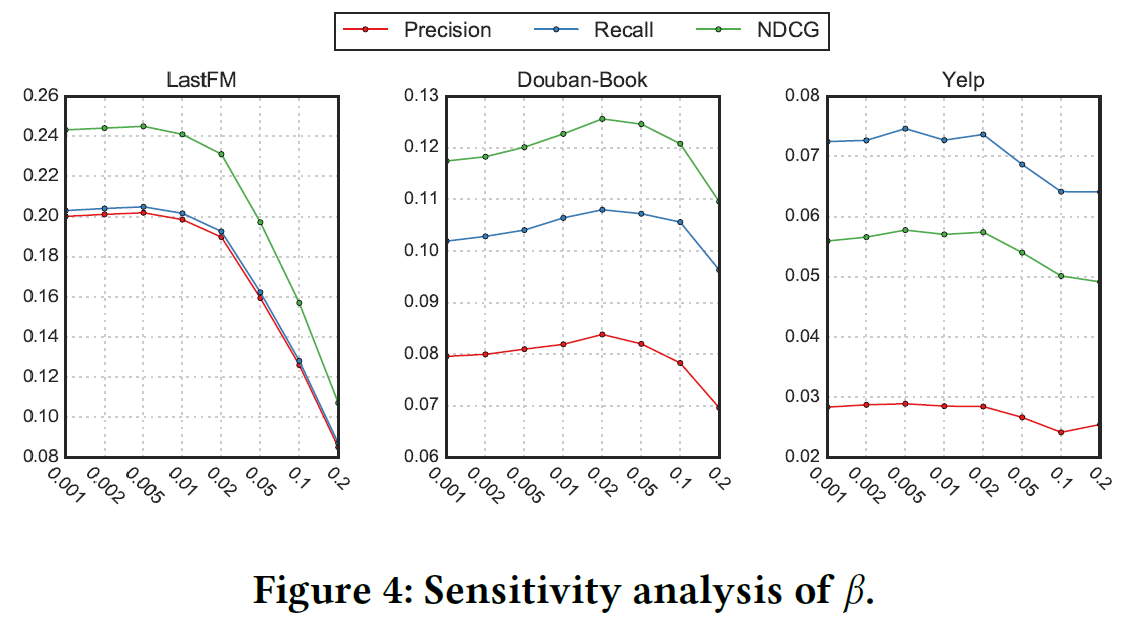
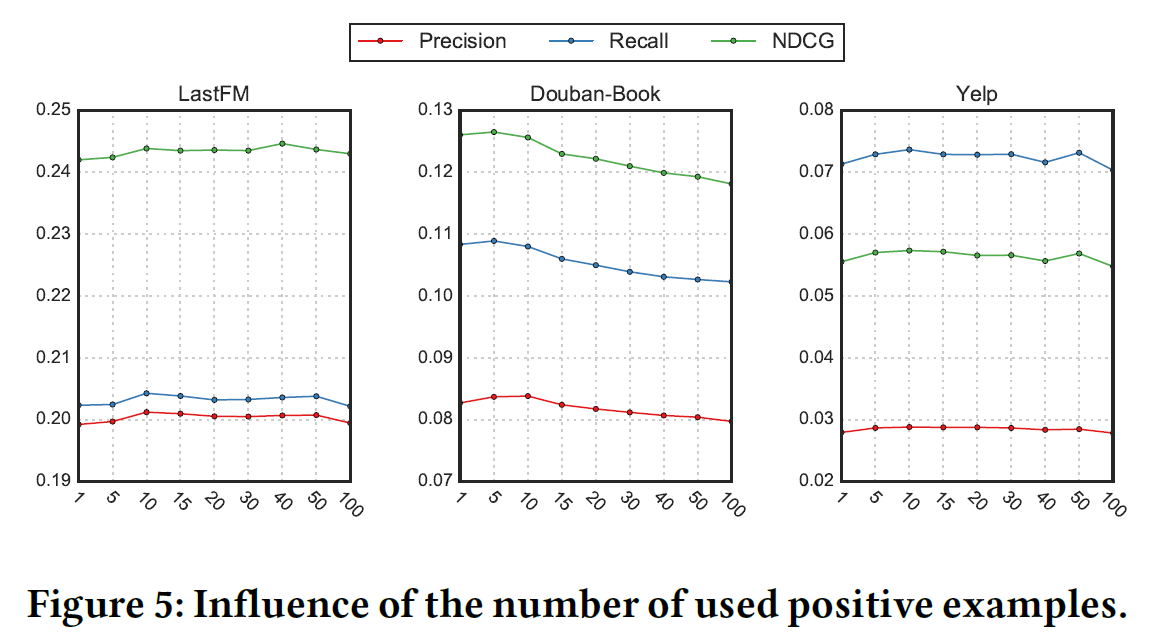
实验中使用到的超参数有三个:
- \(\beta\)来控制自监督tri-training的贡献
- K,是正向示例的数量
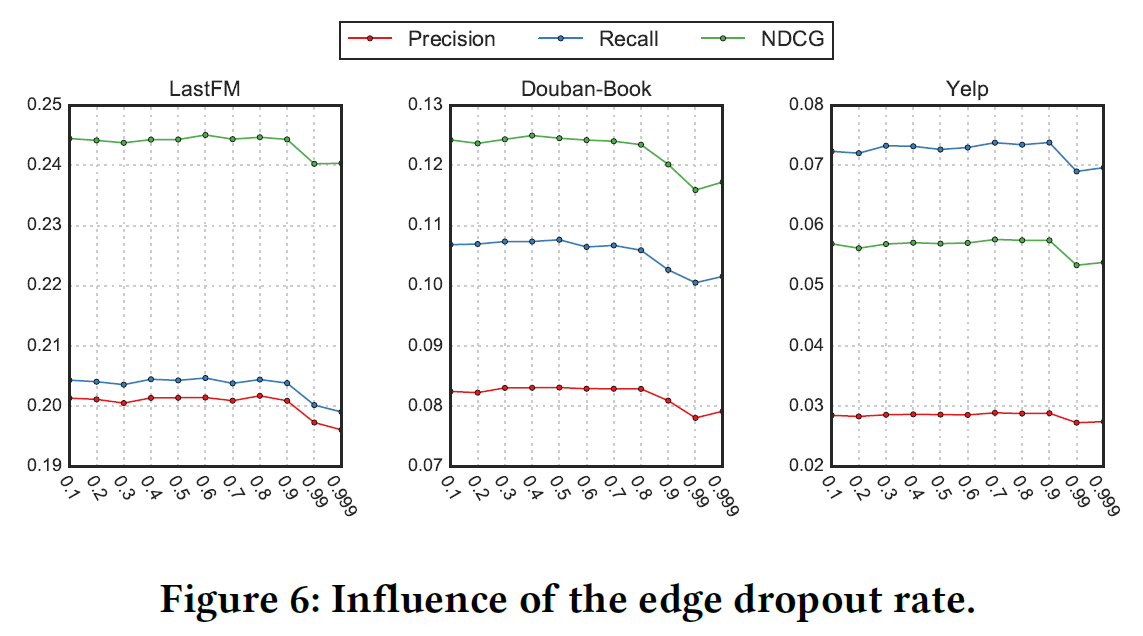
- \(\rho\)来控制边丢弃率
关于参数的影响如下图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号