LangChain分割器:递归字符分割器、语义分割器和其它一些有用的分割/转换器使用
一、递归字符分割器的原理及使用
RecursiveCharacterTextSpliter递归字符分割器,它弥补了固定大小的CharacterTextSpliter只能按照一个设定好的字符串进行分割,有可能造成某一些块过大或过小的问题。过程示意图:
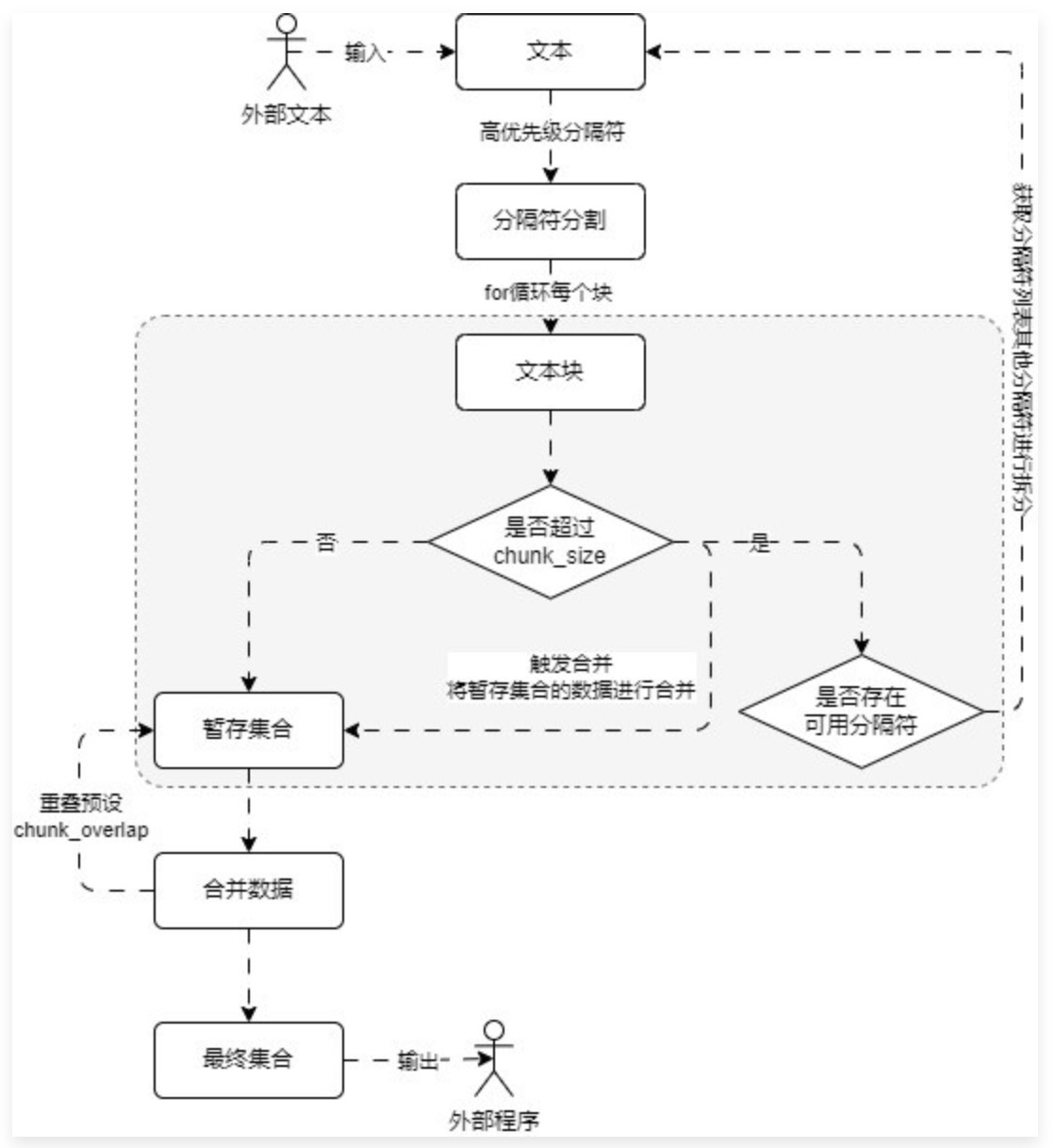
递归字符分割器的原理是,传入一组优先级逐级递减的分割符和设定好的大小,使用第一个分割符进行固定大小分割,如果一遍分割下来仍有过大的块,使用下一个分割符递归调用分割方法,直到暂存的集合中都是基本小于设定大小的块。此时再统一对数据进行有重叠区的合并。
使用时,只需要:
1 from langchain_community.document_loaders import UnstructuredMarkdownLoader 2 from langchain_text_splitters import RecursiveCharacterTextSplitter 3 4 loader = UnstructuredMarkdownLoader("./你的文档.md") 5 documents = loader.load() 6 7 text_splitter = RecursiveCharacterTextSplitter( 8 chunk_size=500, 9 chunk_overlap=50, 10 add_start_index=True, 11 ) 12 chunks = text_splitter.split_documents(documents) 13 14 for chunk in chunks: 15 print(f"块大小:{len(chunk.page_content)}, 块元数据:{chunk.metadata}")
二、语义分割器的原理
语义分割器,分为使用embedding的语义分割,和基于「自然语言处理」的分割器。
使用embedding的语义分割可能由于成本原因,目前已经不怎么使用了。原理是:根据固定的正则分隔符,先将输入文档直接正则匹配分割成块,再将每一个块embedding化,比较这些块的向量相似度比如余弦相似度,再把相似度高的合并(langchain已经不支持)。
自然语言处理的分割器,如:
NLTKTextSplitter:NLTK(The Natural Language Toolkit)是一套用 Python 编程语言编写的用于英语符号和统计自然语言处理(NLP)的库和程序。SpacyTextSplitter:spaCy 是一个用于高级自然语言处理的开源软件库,使用 Python 和 Cython 编程语言编写。
三、结构化分割器的原理及使用
根据具体的标题、子标题、列表、JSON结构等文档结构进行精确切割,适用于格式比较固定的专业领域文档,比如技术文档、说明书、法律条文等。
参考langchain的实现,可以将具体的标题路径放在已分割块的metadata中(HTMLHeaderTextSplitter 与 HTMLSectionSplitter),Markdown或者word文件的结构化切割同理。
或者对JSON进行分割的RecursiveJsonSplitter,它会深度优先地对JSON进行遍历,直到达到设定的块大小,并尽可能保证JSON结构完整,可能这样切割之后的块还会有比较大的,可以调用RecursiveCharacterTextSplitter进行二次分割。
四、问答转换器和翻译转换器
有的时候,DocumentTransformer的作用不只是分割文档,也包括了一些「转换」功能,如将一篇文章转换成一系列的问答合集,来更加匹配用户输入的问题(智能客服场景);
如:
1 import dotenv 2 from langchain_community.document_transformers import DoctranQATransformer 3 from langchain_core.documents import Document 4 5 dotenv.load_dotenv() 6 7 # 1.构建文档列表 8 page_content = """假如这是很长的一篇文章""" 9 documents = [Document(page_content=page_content)] 10 11 # 2.构建问答转换器并转换 12 qa_transformer = DoctranQATransformer(openai_api_model="gpt-3.5-turbo-16k") 13 transformer_documents = qa_transformer.transform_documents(documents) 14 15 # 3.输出内容 16 for qa in transformer_documents[0].metadata.get("questions_and_answers"): 17 print(qa)
这种形式比较适合于问答agent。
或者参考文档本身是英文的,检索到合适的块以后,需要翻译成中文再整理回答给用户。
如:
1 import dotenv 2 from langchain_community.document_transformers import DoctranTextTranslator 3 from langchain_core.documents import Document 4 5 dotenv.load_dotenv() 6 7 # 1.构建文档列表 8 page_content = """...""" 9 documents = [Document(page_content=page_content)] 10 11 # 2.构建翻译转换器并翻译 12 text_translator = DoctranTextTranslator(openai_api_model="gpt-3.5-turbo-16k") 13 translator_documents = text_translator.transform_documents(documents) 14 15 # 3.输出翻译内容 16 print(translator_documents[0].page_content)
这种转换都是文档到文档的,可以插入到任意的生成前的阶段,用来提升参考上下文的质量,提升大模型回答的准确性。
但是,大部分这种转换组件内部都有模型调用,需要注意成本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号