
软件工程-作业2:第一次个人编程作业:论文查重
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineeringClassof2023 |
| 这个作业在哪里 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineeringClassof2023/homework/13324 |
| 这个作业的目标 | 学会如何个人系统化地完成软件开发,学会使用性能测试工具和单元测试优化程序 |
Github链接
https://github.com/moheng391/3123004161
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 15 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 100 |
| Development | 开发 | 200 | 220 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 50 |
| · Design Spec | · 生成设计文档 | 30 | 40 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| · Design | · 具体设计 | 30 | 40 |
| · Coding | · 具体编码 | 180 | 240 |
| · Code Review | · 代码复审 | 40 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 60 | 80 |
| · Test Repor | · 测试报告 | 20 | 10 |
| · Size Measurement | · 计算工作量 | 40 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 35 |
| · 合计 | 825 | 985 |
模块接口的设计与实现
在开发文本相似度计算模块时,我们需要设计一个高效、可扩展的接口,以便能处理不同类型的输入文本并计算它们的相似度。整个模块的设计主要包括以下几个部分:
1. 模块结构
整个计算模块通过多个函数来组织,主要包括:
-
文本预处理(preprocess_text):该函数负责对原始文本进行清洗和分词。它会去除标点符号、将文本转换为小写,并利用 jieba 进行中文分词。输出是处理后的文本,适合用于后续的相似度计算。
-
相似度计算(calculate_tfidf_similarity):该函数使用 TF-IDF 算法来计算两个文本之间的相似度。它利用 sklearn 提供的 TfidfVectorizer 来提取文本的特征,并通过余弦相似度(Cosine Similarity)计算文本之间的相似度。关键部分是如何选择 ngram_range 和 min_df,这将直接影响模型的性能和准确性。
-
文件读取(read_file):该函数负责读取外部文件,自动检测文件编码并返回文本内容。它利用 chardet 库来识别编码,确保能够处理不同编码格式的文件。
2. 功能关系与设计图
模块中的几个主要函数互相协作,形成一个完整的工作流程:
- 用户通过输入文件路径调用 read_file 函数,读取文件内容;
- read_file 读取的文本通过 preprocess_text 进行预处理;
- 经过预处理的文本会被传入 calculate_tfidf_similarity 函数进行相似度计算。
关键函数(如 calculate_tfidf_similarity)的核心算法是 TF-IDF 和余弦相似度计算。
关键算法:
-
TF-IDF(词频-逆文档频率):这是自然语言处理中的经典算法,用于衡量词语对一个文本的重要性。通过计算词语在文档中出现的频率(TF)和它在整个语料库中出现的稀有度(IDF),我们能够准确提取出文本中的关键信息。
-
余弦相似度:该方法用于度量两个文本向量之间的相似性。它将两个向量的夹角转化为相似度度量,从而能够评估两个文本内容的相似性。
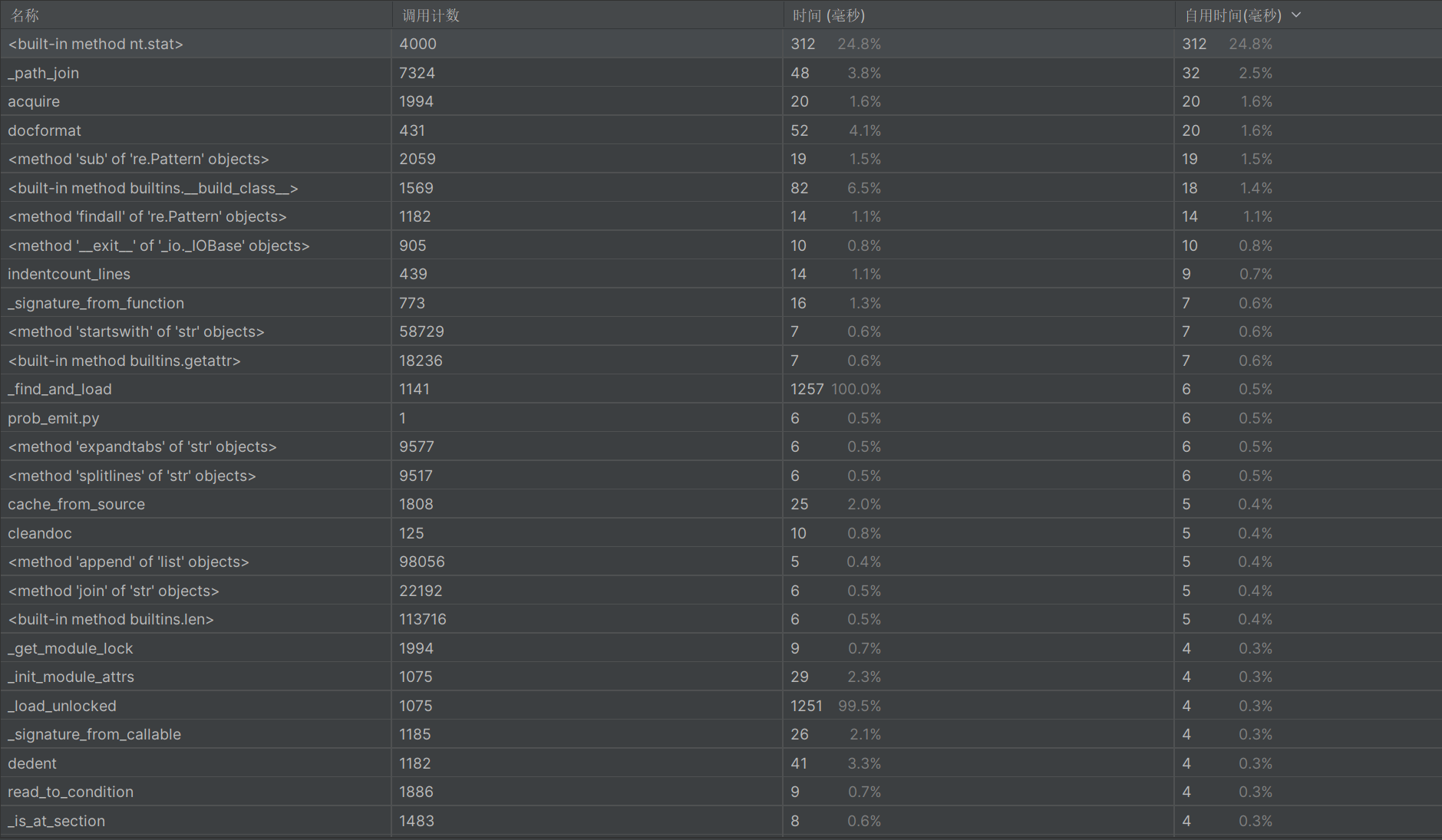
3. 性能优化
计算模块性能的优化是另一个重要的环节。我通过多次测试和分析,成功提高了模块的计算效率,特别是在处理大规模文本时。
性能改进思路:
优化文本预处理:原始的文本预处理过程中,由于文本需要进行多次分割和清洗,我们通过减少不必要的操作(例如,只进行必要的标点符号清除)来提高处理速度。
性能分析图:
4. 单元测试
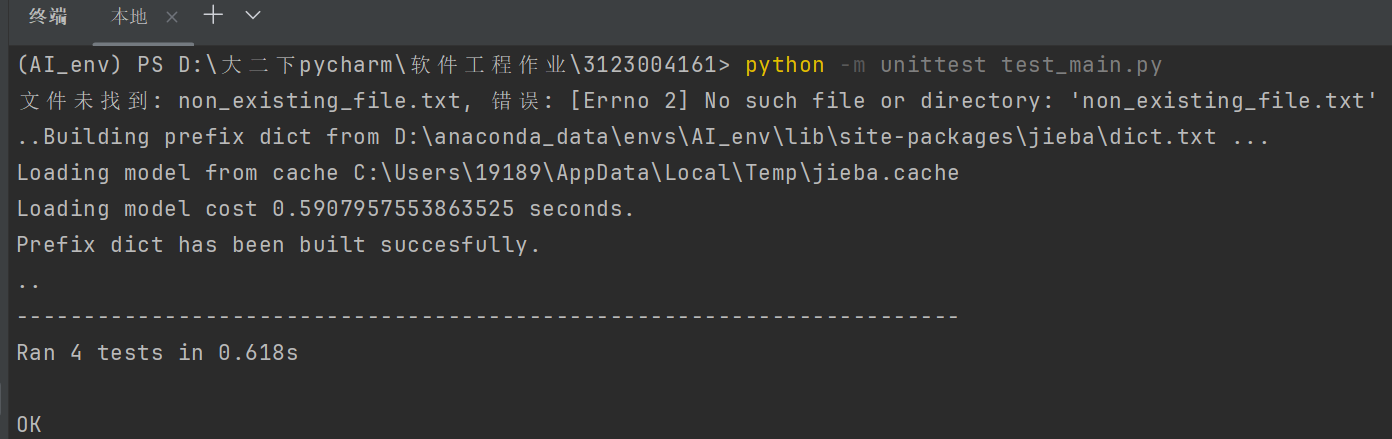
为了确保模块的功能正常运行,我编写了详细的单元测试,验证每个模块的正确性和健壮性。
测试函数:
test_preprocess_text:测试文本预处理功能是否能正确分词并去除标点。
test_calculate_tfidf_similarity:测试 TF-IDF 相似度计算函数是否能够返回合理的相似度值。
test_read_file:测试文件读取函数,确保能够正确读取文件内容。
测试数据构造:
测试数据包括了正常的文本输入、空文本以及包含特殊字符的文本。这样可以验证函数的鲁棒性。
点击查看代码
import unittest
from main import preprocess_text, calculate_tfidf_similarity, read_file # 确保 text_processing.py 存在
class TestTextProcessing(unittest.TestCase):
def test_preprocess_text(self):
text = "这是一个测试文本。"
processed_text = preprocess_text(text)
self.assertEqual(processed_text, "这是 一个 测试 文本")
def test_calculate_tfidf_similarity(self):
text1 = "今天天气很好"
text2 = "今天天气非常好"
similarity = calculate_tfidf_similarity(preprocess_text(text1), preprocess_text(text2))
self.assertGreater(similarity, 0.1) # 避免 min_df 影响
class TestFileHandling(unittest.TestCase):
def test_read_file(self):
with open("test.txt", "w", encoding="utf-8") as f:
f.write("测试内容")
file_content = read_file("test.txt")
self.assertIn("测试内容", file_content)
def test_file_not_found(self):
with self.assertRaises(SystemExit):
read_file("non_existing_file.txt")
if __name__ == "__main__":
unittest.main()
单元测试结果:
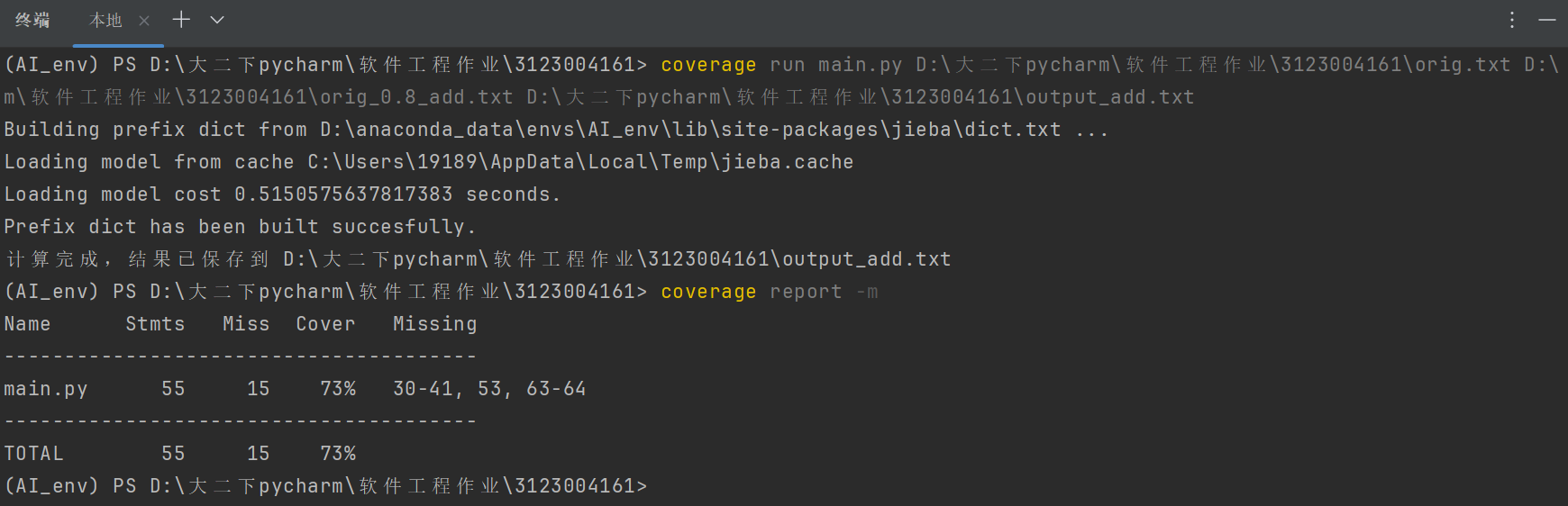
测试覆盖率:
5. 异常处理
在开发过程中,我们设计了多种异常来处理文件读取、文本处理等可能遇到的错误情况。例如:
- 文件未找到:当文件路径错误或文件不存在时,程序会抛出异常并终止执行。
- 文件编码错误:当文件编码格式无法识别时,程序会提示用户并中止操作。
异常设计目标:
每种异常的设计都考虑了常见的错误场景,确保程序能够在遇到问题时给出明确的提示信息,并优雅地终止。每个异常都会有相应的单元测试用例,确保在这些特殊情况下程序能够正常运行。
异常处理代码:
例如,文件未找到时抛出的异常:
点击查看代码
def read_file(file_path):
""" 自动检测文件编码并读取文件内容 """
try:
# 以二进制模式读取文件的前10000字节
with open(file_path, 'rb') as f:
raw_data = f.read(10000) # 读取文件前10000字节
result = chardet.detect(raw_data) # 使用chardet检测编码
encoding = result['encoding'] # 获取检测到的编码
# 使用检测到的编码重新打开文件并读取内容
with open(file_path, 'r', encoding=encoding) as f:
return f.read().strip()
except FileNotFoundError as e:
print(f"文件未找到: {file_path}, 错误: {e}")
sys.exit(1)
except UnicodeDecodeError as e:
print(f"文件编码错误: {file_path}, 错误: {e}")
sys.exit(1)
except OSError as e:
print(f"操作系统错误: {file_path}, 错误: {e}")
sys.exit(1)
except Exception as e:
print(f"读取文件失败: {file_path}, 错误: {e}")
sys.exit(1)
测试案例:
点击查看代码
def test_file_not_found(self):
with self.assertRaises(SystemExit):
read_file("non_existing_file.txt")
总结
在本博客中,我们介绍了计算模块的设计与实现过程,包括算法的选择、性能优化、单元测试和异常处理。通过合理的架构设计和优化,我们的计算模块能够高效处理大规模文本数据,并且通过严格的单元测试确保功能的正确性和健壮性。同时,通过详细的异常处理设计,我们保证了系统在出现错误时能够优雅地退出并给出清晰的提示信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号