临时
多线程
- 多线程说一下
计算机网络:
1.分布式系统里面两个结点怎么通信
- 点对点之间的最基本、最底层的方式,是直接基于 TCP 或者 UDP 建立 Socket 连接。这样的连接相当于在两个机器之间建立一个字节流管道。
- 远程过程调用RPC(中间件)
- RPC 可以隐藏调用细节,让我们调用服务端子程序的感觉就像调用本地子程序一样
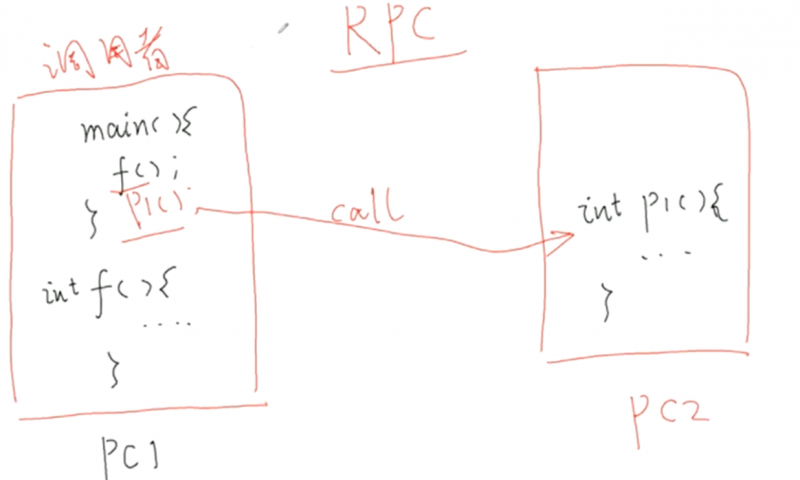
- 对于被调用者而言,其在被调用时也无法分辨该调用来自本地还是远程。
- RPC 将面向过程的通用编程模型扩展到了分布式环境。
- RPC 可以实现跨进程、跨语言、跨网络、跨平台的过程调用。
- gRPC 几乎可以实现所有主流编程语言互相调用
- RPC 强化了【面向接口编程】的编程风格。比如主程序和功能模块可以交给不同的人去做。这不同的人在正式开工之前要定义好接口。开工时就功能模块负责实现接口,主程序调用接口。
- 实现 RPC 必须有 RPC 中间件的支持。上面这几点能做好,都要靠中间件来进行支撑。底层通信细节就由中间件来实现。
2.给两个ip,怎么建立连接
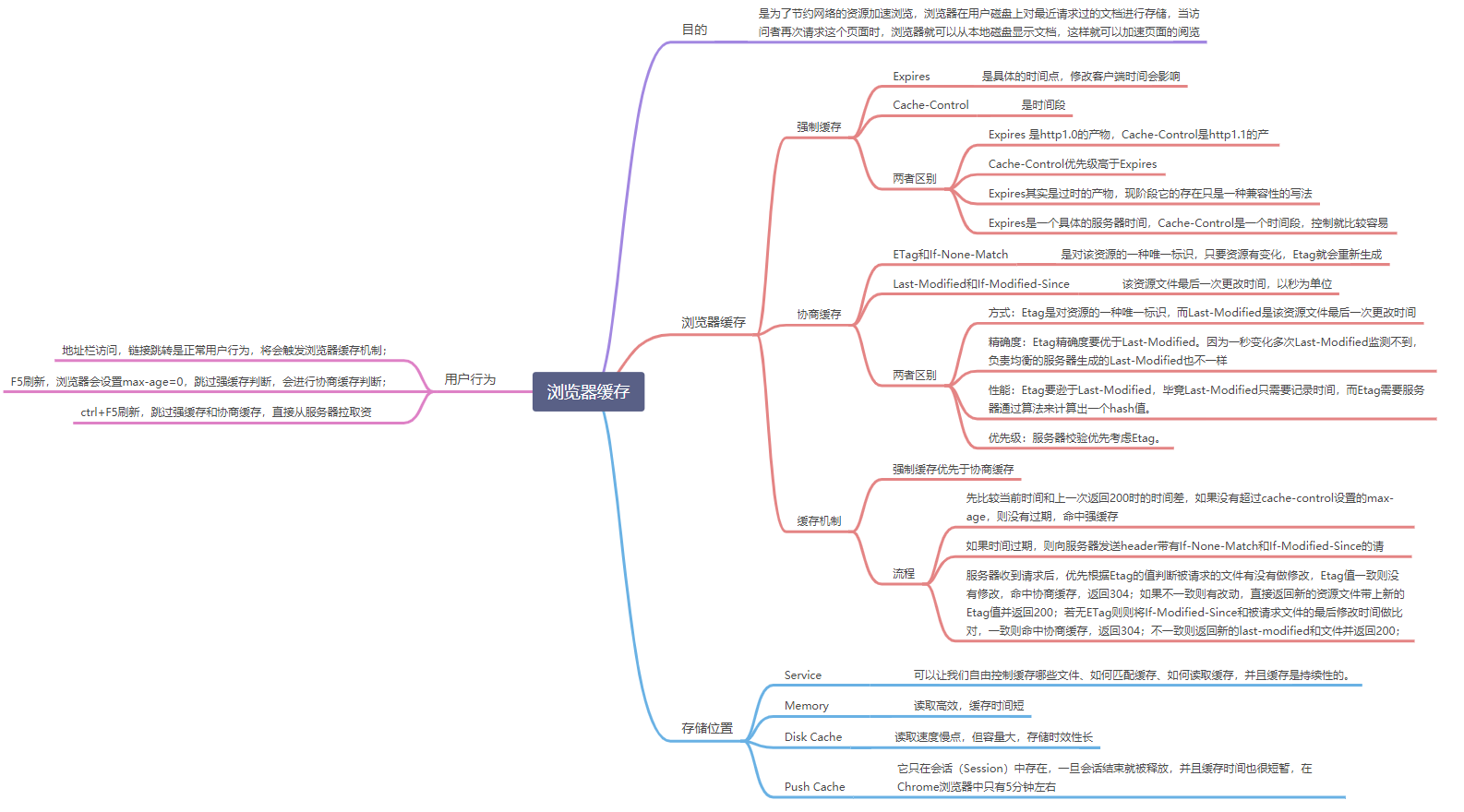
3.浏览器缓存有哪些?缓存机制?
- http缓存是基于HTTP协议的浏览器文件级缓存机制。
- websql这种方式只有较新的chrome浏览器支持,并以一个独立规范形式出现
- indexDB 是一个为了能够在客户端存储可观数量的结构化数据,并且在这些数据上使用索引进行高性能检索的 API
- Cookie一般网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)
- Localstoragehtml5的一种新的本地缓存方案,目前用的比较多,一般用来存储ajax返回的数据,加快下次页面打开时的渲染速度
- Sessionstorage和localstorage类似,但是浏览器关闭则会全部删除,api和localstorage相同,实际项目中使用较少。
- application cache 是将大部分图片资源、js、css等静态资源放在manifest文件配置中
- cacheStorage是在ServiceWorker的规范中定义的,可以保存每个serverWorker申明的cache对象
- flash缓存 这种方式基本不用,这一方法主要基于flash有读写浏览器端本地目录的功能
4.cookie和session和localStorage的区别?生命周期?
cookie和session的区别详见我另一篇博客
- session生命周期
Session何时生效
Sessinon在用户访问第一次访问服务器时创建,需要注意只有访问JSP、Servlet等程序时才会创建Session,只访问HTML、IMAGE等静态资源并不会创建Session,可调用request.getSession(true)强制生成Session。
Session何时失效
-
服务器会把长时间没有活动的Session从服务器内存中清除,此时Session便失效。Tomcat中Session的默认失效时间为20分钟。
-
调用Session的invalidate方法。
HttpSession session = request.getSession();
session.invalidate();//注销该request的所有session
session的过期时间是从什么时候开始计算的?是从一登录就开始计算还是说从停止活动开始计算?
从session不活动的时候开始计算,如果session一直活动,session就总不会过期。
从该Session未被访问,开始计时; 一旦Session被访问,计时清0;
设置session的失效时间
web.xml中
<session-config>
<session-timeout>30</session-timeout>
</session-config>
5.网络的tcp.udp区别,udp能不能像tcp一样实现可靠连接,能的话用什么方法。
- TCP是面向连接的,UDP是无连接的;
什么叫无连接?
UDP发送数据之前不需要建立连接
- TCP是可靠的,UDP不可靠;
什么是不可靠?
UDP接收方收到报文后,不需要给出任何确认
- TCP只支持点对点通信,UDP支持一对一、一对多、多对一、多对多;
- TCP是面向字节流的,UDP是面向报文的;
什么意思?
面向字节流是指发送数据时以字节为单位,一个数据包可以拆分成若干组进行发送,而UDP一个报文只能一次发完。
- TCP有拥塞控制机制,UDP没有。
- TCP首部开销(20字节)比UDP首部开销(8字节)要大
- UDP 的主机不需要维持复杂的连接状态表
1、RUDP(Reliable User Datagram Protocol)
RUDP 提供一组数据服务质量增强机制,如拥塞控制的改进、重发机制及淡化服务器算法等,从而在包丢失和网络拥塞的情况下, RTP 客户机(实时位置)面前呈现的就是一个高质量的 RTP 流。在不干扰协议的实时特性的同时,可靠 UDP 的拥塞控制机制允许 TCP 方式下的流控制行为。
2、RTP(Real Time Protocol)
RTP为数据提供了具有实时特征的端对端传送服务,如在组播或单播网络服务下的交互式视频音频或模拟数据。
应用程序通常在 UDP 上运行 RTP 以便使用其多路结点和校验服务;这两种协议都提供了传输层协议的功能。但是 RTP 可以与其它适合的底层网络或传输协议一起使用。如果底层网络提供组播方式,那么 RTP 可以使用该组播表传输数据到多个目的地。
RTP 本身并没有提供按时发送机制或其它服务质量(QoS)保证,它依赖于底层服务去实现这一过程。 RTP 并不保证传送或防止无序传送,也不确定底层网络的可靠性。 RTP 实行有序传送, RTP 中的序列号允许接收方重组发送方的包序列,同时序列号也能用于决定适当的包位置,例如:在视频解码中,就不需要顺序解码。
3、UDT(UDP-based Data Transfer Protocol)
基于UDP的数据传输协议(UDP-basedData Transfer Protocol,简称UDT)是一种互联网数据传输协议。UDT的主要目的是支持高速广域网上的海量数据传输,而互联网上的标准数据传输协议TCP在高带宽长距离网络上性能很差。
顾名思义,UDT建于UDP之上,并引入新的拥塞控制和数据可靠性控制机制。UDT是面向连接的双向的应用层协议。它同时支持可靠的数据流传输和部分可靠的数据报传输。由于UDT完全在UDP上实现,它也可以应用在除了高速数据传输之外的其它应用领域,例如点到点技术(P2P),防火墙穿透,多媒体数据传输等等。
6.网络有几层,介绍一下
7层,从上到下:应用层、表示层、会话层、运输层、网络层、数据链路层、物理层
5层,从上到下:应用层、运输层、网络层、数据链路层、物理层
TCP/IP4层,从上到下:应用层、运输层、网络层、网络接口层
常见协议
- 应用层:常见协议:
- FTP(21端口):文件传输协议
- SSH(22端口):远程登陆
- TELNET(23端口):远程登录
- SMTP(25端口):发送邮件
- POP3(110端口):接收邮件
- HTTP(80端口):超文本传输协议
- DNS(53端口):运行在UDP上,域名解析服务
- 传输层:TCP/UDP
- 网络层:IP、ARP、NAT、RIP...
- 数据链路层:MAC:MAC是物理地址
7.网络链路层协议有哪些
8.HTTP和https协议介绍一下
9.最大报文长度(mss)是多少?
数据库:
1.什么情况下建索引
- 频繁作为where条件语句查询的字段
- 关联字段需要建立索引,例如外键字段,student表中的classid, classes表中的schoolid 等
- 排序字段可以建立索引
- 分组字段可以建立索引,因为分组的前提是排序
2.什么情况下不能用索引
- 数据唯一性差的字段不要使用索引
比如性别,只有两种可能数据。意味着索引的二叉树级别少,多是平级。这样的二叉树查找无异于全表扫描。 - 频繁更新的字段不要使用索引
比如logincount登录次数,频繁变化导致索引也频繁变化,增大数据库工作量,降低效率。 - 字段不在where语句出现时不要添加索引
只有在where语句出现,mysql才会去使用索引 - 数据量少的表不要使用索引
使用了改善也不大
5)参与列计算的列不适合建索引
3.知道哪些索引
- 单列索引和组合索引
- 单列索引:即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。
- 组合索引:即一个索包含多个列。
- 主键索引和二级索引(辅助索引)
- 主键列使用的索引是主键索引,一个表只能有一个主键,不能重复不能为null
- 二级索引也被称为辅助索引,二级索引的叶子节点中放的数据是主键。即通过二级索引可以定位主键的位置(回表)
- 二级索引有唯一索引、普通索引、前缀索引和全文索引
- 聚集索引和非聚集索引
- 聚集索引的数据和索引一起放(会把表中的每行数据存储到索引的叶子节点中)
- 非聚集索引的数据和索引分开放
- 主键索引属于聚集索引;二级索引属于非聚集索引
- 聚集索引优缺点
- 优点:查询速度快,定位到了key就可以立刻拿到数据,不用回表
- 缺点:维护成本高,一旦数据发生修改,对应的索引也要进行修改
- 非聚集索引优缺点
- 优点:维护成本低
- 缺点:可能需要回表,查询速度变慢
- 注:回表:根据行号返回表中查找数据,扫描表是最慢的
- 覆盖索引:查询列和索引列是一致的
4.InnoDB
- InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,(所以最好把多条SQL语言放在begin和commit之间,组成一个事务);
- InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败
- InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构)。 MyISAM是非聚集索引,也是使用B+Tree作为索引结构,索引和数据文件是分离的。
- InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快
- 那么为什么InnoDB没有了这个变量呢?
- 因为InnoDB的事务特性,在同一时刻表中的行数对于不同的事务而言是不一样的,因此count统计会计算对于当前事务而言可以统计到的行数,而不是将总行数储存起来方便快速查询。
- InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁
- InnoDB的行锁是实现在索引上的,而不是锁在物理行记录上。如果访问没有命中索引,也无法使用行锁,将要退化为表锁。
- InnoDB表必须有主键(用户没有指定的话会自己找或生产一个主键),而Myisam可以没有
- Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI
- Innodb:frm是表定义文件,ibd是数据文件
- Myisam:frm是表定义文件,myd是数据文件,myi是索引文件
5.varchar和%nn%哪个不能用索引
%nn%,模糊查询中,%在前会导致索引失效
6.数据库是如何搭建的
create database
7.慢sql优化
8.sql语句:以系进行划分求平均分大于80的系。
9.事务是什么?有什么作用?
10.基本的sql语句,检索全部行
11.包括数据库AICD.索引的实现方式.b+树.左链接右链接等。
特性
- 原子性:一系列操作要么都执行,要么都不执行
- 一致性:事务执行前后数据完整性不变,如转账前后总金额不变
- 隔离性:多个事务并发访问数据库,事务之间互相隔离
- 持久性:事务提交后,在数据库中的改变是持久的,即使发生故障也一样
索引实现
hash、B+树
连接
-
left join会返回左表的所有行,即使在右表中没有匹配的数据
-
right join会返回右表所有行,即使在左表中没有匹配的数据
-
inner join会返回两个表共有的数据
-
full join会返回两个表所有行,即使没有匹配
数据结构和算法
- 给你一个有序数组,怎么查找某个值,时间复杂度
- 一个数组里有几个数,要求把奇数排到前面,偶数排到后面
- 你了解的排序算法有哪些,具体说一下快排的原理 (快排 ×3)
集合
- ArrayList和linkedList区别
- Java中的容器了解吗
Linux
- 常用命令
- linux系统中修改文件权限,为什么要用4 2 1表示读写执行。
框架
- spring是如何整合mybatis的。 ×2
- SpringMVC装配过程
- springBoot比起SSM框架的优势
- 用过微服务嘛,自己搭过微服务框架嘛
- 微服务框架了解吗
- Mybatis的xml文件的命名
疑惑?命名?命名难道还有文章吗?笔者才疏学浅不知道命名有什么知识点,有知道的小伙伴请告诉我一下
这里我以命名空间namespace来看这个问题吧
- Spring和Springboot你使用的时候觉得有什么区别
- 用过mybatis吧?那么maybatis和hibernate的区别有哪些?分别有哪些优势?
- 用过spring吧?那么spring的特点有哪些?如何整合?
- .xml中的属性的值如何获得?
java基础
- 重写跟重载
- 抽象类和接口的联系和区别是什么
其他
- 用过的git命令都有哪些?
- 解释一下什么是锁?有哪些锁,作用分别是什么?(不知道这个问题是问到数据库还是多线程)
- 对restful的理解?
- 测试的基本方法?
- 用过Python吗?用过什么自动化测试工具?
- 如何保证测试的全面性?
- 一根绳子能被一刀切成五段吗?
- 你和我在圆形棋盘下棋,棋盘没有格子,怎样下可以让你必胜?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号