


MQ-RabbitMQ
这里有两种解决方案:
-
方案1:每当后台对商品做增删改操作,同时要修改索引库数据及静态页面
-
方案2:搜索服务和商品页面服务对外提供操作接口,后台在商品增删改后,调用接口
以上两种方式都有同一个严重问题:就是代码耦合,后台服务中需要嵌入搜索和商品页面服务,违背了微服务的独立原则。
所以,我们会通过另外一种方式来解决这个问题:消息队列
消息队列是典型的:生产者、消费者模型。生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。因为消息的生产和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的侵入,这样就实现了生产者和消费者的解耦。
-
商品服务对商品增删改以后,无需去操作索引库或静态页面,只是发送一条消息,也不关心消息被谁接收。
-
搜索服务和静态页面服务接收消息,分别去处理索引库和静态页面。
如果以后有其它系统也依赖商品服务的数据,同样监听消息即可,商品服务无需任何代码修改
MQ是消息通信的模型,并发具体实现。现在实现MQ的有两种主流方式:AMQP、JMS。(https://blog.csdn.net/tuzongxun/article/details/82782528)
AMQP(advanced message queuing protocol)在2003年时被提出,最早用于解决金融领不同平台之间的消息传递交互问题。
顾名思义,AMQP是一种协议,更准确的说是一种binary wire-level protocol(链接协议)。这是其和JMS的本质差别,AMQP不从API层进行限定,而是直接定义网络交换的数据格式。
这使得实现了AMQP的provider天然性就是跨平台的。意味着我们可以使用Java的AMQP provider,同时使用一个python的producer加一个rubby的consumer。
JMS(Java MessageService)实际上是指JMS API。JMS是由Sun公司早期提出的消息标准,旨在为java应用提供统一的消息操作,包括create、send、receive等。JMS已经成为Java Enterprise Edition的一部分。
从使用角度看,JMS和JDBC担任差不多的角色,用户都是根据相应的接口可以和实现了JMS的服务进行通信,进行相关的操作。
两者间的区别和联系:
-
JMS是定义了统一的接口,来对消息操作进行统一;AMQP是通过规定协议来统一数据交互的格式
-
JMS限定了必须使用Java语言;AMQP只是协议,不规定实现方式,因此是跨语言的。
-
JMS规定了两种消息模型;而AMQP的消息模型更加丰富
RabbitMQ是基于AMQP的一款消息管理系统(https://blog.csdn.net/hellozpc/article/details/81436980)
AMQP,即Advanced Message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然
RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C/C++、PHP、node.js、ActionScript、XMPP、STOMP等,支持AJAX。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
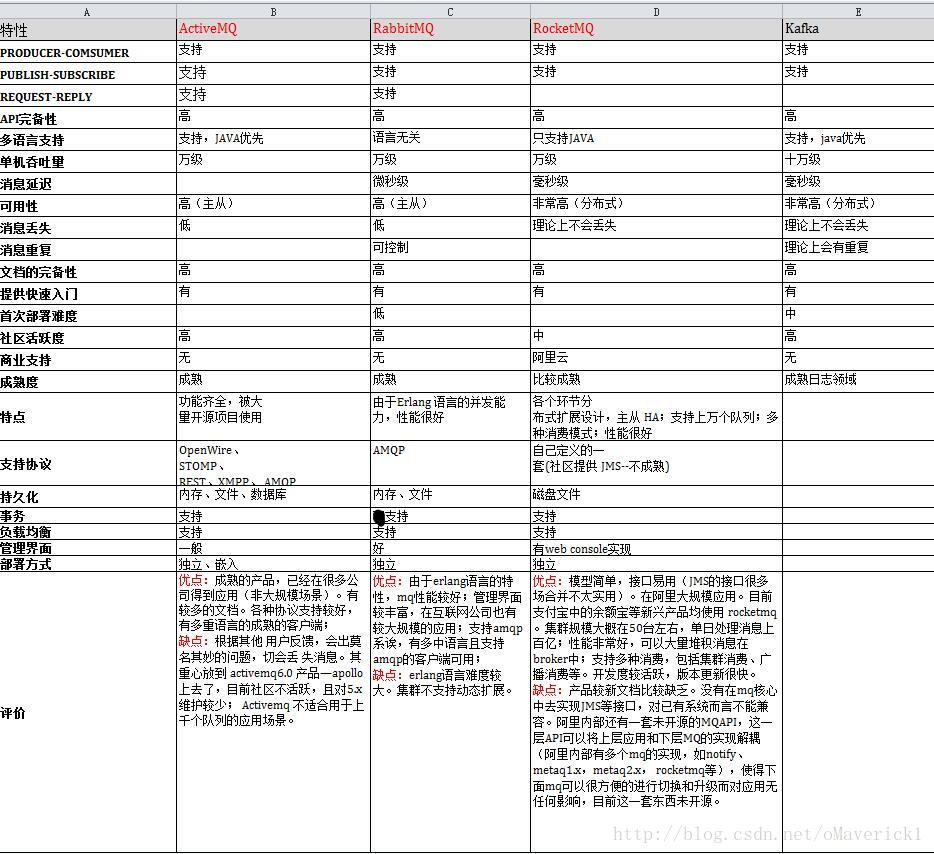
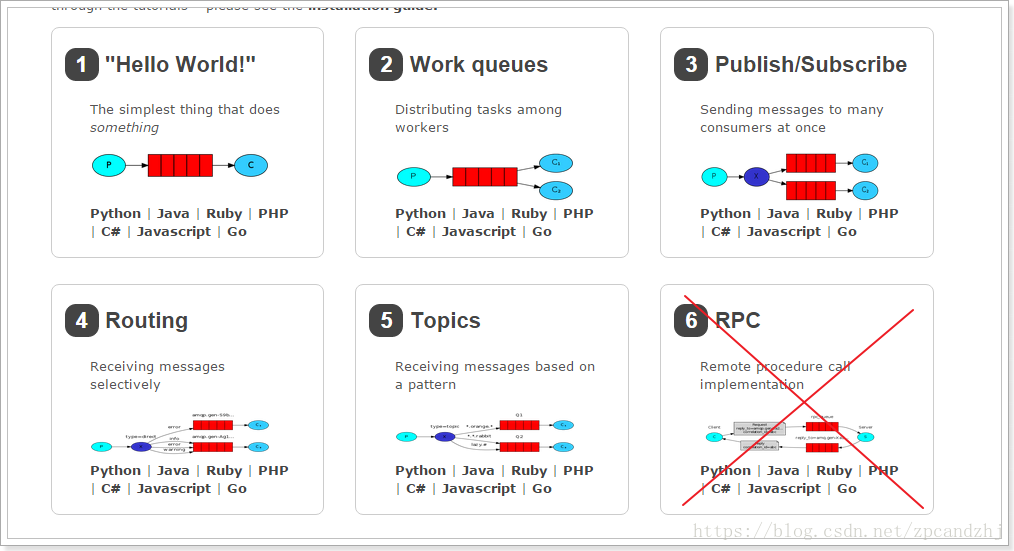
RabbitMQ提供了6种消息模型,但是第6种其实是RPC,并不是MQ
其实3、4、5这三种都属于订阅模型,只不过进行路由的方式不同
官方文档说明:
RabbitMQ是一个消息的代理者(Message Broker):它接收消息并且传递消息。
你可以认为它是一个邮局:当你投递邮件到一个邮箱,你很肯定邮递员会终究会将邮件递交给你的收件人。与此类似,RabbitMQ 可以是一个邮箱、邮局、同时还有邮递员。
不同之处在于:RabbitMQ不是传递纸质邮件,而是二进制的数据
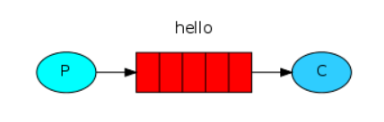
基本消息模型图:
-
-
C:消费者:消息的接受者,会一直等待消息到来。
-
queue:消息队列,图中红色部分。类似一个邮箱,可以缓存消息;生产者向其中投递消息,消费者从其中取出消息。
消费者的消息确认机制(Acknowlage)
通过刚才的案例可以看出,消息一旦被消费者接收,队列中的消息就会被删除。
那么问题来了:RabbitMQ怎么知道消息被接收了呢?
这就要通过消息确认机制(Acknowlege)来实现了。当消费者获取消息后,会向RabbitMQ发送回执ACK,告知消息已经被接收。不过这种回执ACK分两种情况:
-
自动ACK:消息一旦被接收,消费者自动发送ACK
-
根据消息的重要性:
-
如果消息不太重要,丢失也没有影响,那么自动ACK会比较方便
-
如果消息非常重要,不容丢失。那么最好在消费完成后手动ACK,否则接收消息后就自动ACK,RabbitMQ就会把消息从队列中删除。如果此时消费者宕机,那么消息就丢失了。
在刚才的基本模型中,一个生产者,一个消费者,生产的消息直接被消费者消费。比较简单。
Work queues,也被称为(Task queues),任务模型。
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。此时就可以使用work 模型:让多个消费者绑定到一个队列,共同消费队列中的消息。队列中的消息一旦消费,就会消失,因此任务是不会被重复执行的。
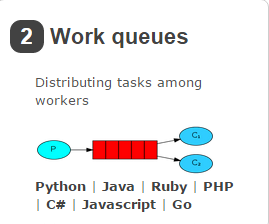
角色:
-
P:生产者:任务的发布者
-
C1:消费者,领取任务并且完成任务,假设完成速度较慢
-
C2:消费者2:领取任务并完成任务,假设完成速度快
轮询分发 :平均每个消费者获得相同数量的消息。这种方式分发消息机制称为Round-Robin(轮询)。
“能者多劳”:关闭自动应答,改为手动应答。
按照每个消费者的能力分配消息,联合使用 Qos 和 Acknowledge 就可以做到。
basicQos 方法设置了当前信道最大预获取(prefetch)消息数量为1。消息从队列异步推送给消费者,消费者的 ack 也是异步发送给队列,从队列的视角去看,总是会有一批消息已推送但尚未获得 ack 确认,Qos 的 prefetchCount 参数就是用来限制这批未确认消息数量的。设为1时,队列只有在收到消费者发回的上一条消息 ack 确认后,才会向该消费者发送下一条消息。prefetchCount 的默认值为0,即没有限制,队列会将所有消息尽快发给消费者。
消息的确认模式
模式1:自动确认
只要消息从队列中获取,无论消费者获取到消息后是否成功消息,都认为是消息已经成功消费。
模式2:手动确认
消费者从队列中获取消息后,服务器会将该消息标记为不可用状态,等待消费者的反馈,如果消费者一直没有反馈,那么该消息将一直处于不可用状态。
前面2个模型中,只有3个角色:
-
P:生产者,也就是要发送消息的程序
-
C:消费者:消息的接受者,会一直等待消息到来。
-
queue:消息队列,图中红色部分。类似一个邮箱,可以缓存消息;生产者向其中投递消息,消费者从其中取出消息。
而在订阅模型中,多了一个exchange角色,而且过程略有变化:
-
P:生产者,也就是要发送消息的程序,但是不再发送到队列中,而是发给X(交换机)
-
C:消费者,消息的接受者,会一直等待消息到来。
-
Queue:消息队列,接收消息、缓存消息。
-
Exchange:交换机,图中的X。一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。Exchange有以下3种类型:
-
Fanout:广播,将消息交给所有绑定到交换机的队列
-
Direct:定向,把消息交给符合指定routing key 的队列
-
Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
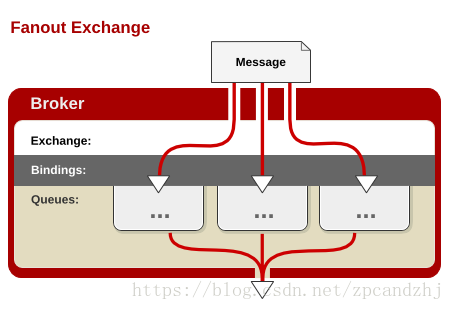
1)订阅模型-Fanout
Fanout,也称为广播。

在广播模式下,消息发送流程是这样的:
-
1) 可以有多个消费者
-
2) 每个消费者有自己的queue(队列)
-
3) 每个队列都要绑定到Exchange(交换机)
-
4) 生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定。
-
5) 交换机把消息发送给绑定过的所有队列
-
6) 队列的消费者都能拿到消息。实现一条消息被多个消费者消费
注意:一个消费者队列可以有多个消费者实例,只有其中一个消费者实例会消费
生产者
两个变化:
-
1) 声明Exchange,不再声明Queue
-
2) 发送消息到Exchange,不再发送到Queue
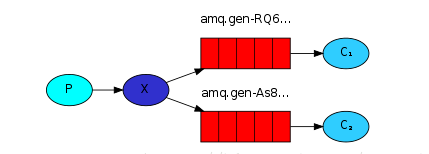
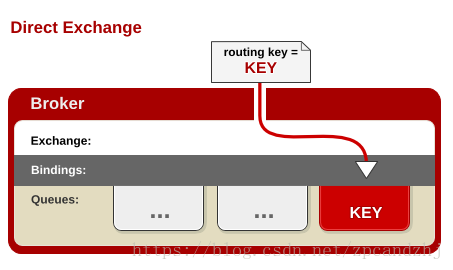
在Direct模型下:
-
队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) -
消息的发送方在 向 Exchange发送消息时,也必须指定消息的
RoutingKey。 -
Exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
图解:
-
P:生产者,向Exchange发送消息,发送消息时,会指定一个routing key。
-
X:Exchange(交换机),接收生产者的消息,然后把消息递交给 与routing key完全匹配的队列
-
C1:消费者,其所在队列指定了需要routing key 为 error 的消息
-
C2:消费者,其所在队列指定了需要routing key 为 info、error、warning 的消息
生产者
模拟商品的增删改,发送消息的RoutingKey分别是:insert、update、delete
通配符规则:
`#`:匹配一个或多个词
`*`:匹配不多不少恰好1个词

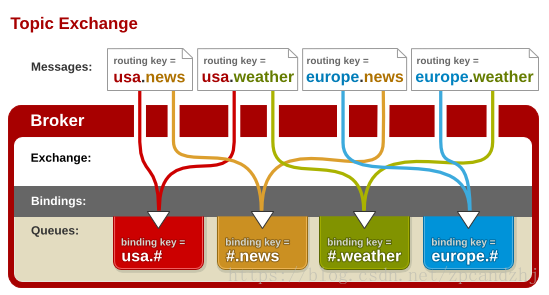
解释:
-
红色Queue:绑定的是
usa.#,因此凡是以usa.开头的routing key都会被匹配到 -
黄色Queue:绑定的是
#.news,因此凡是以.news结尾的routing key都会被匹配
生产者
使用topic类型的Exchange,发送消息的routing key有3种: ie.isnert、ie.update、ie.delete:
如何避免消息丢失?
1) 消费者的ACK机制。可以防止消费者丢失消息。
2) 但是,如果在消费者消费之前,MQ就宕机了,消息就没了
为什么会需要消息队列(MQ)?(http://www.cnblogs.com/xuyatao/p/6864109.html)
主要原因是由于在高并发环境下,由于来不及同步处理,请求往往会发生堵塞,比如说,大量的insert,update之类的请求同时到达MySQL,直接导致无数的行锁表锁,甚至最后请求会堆积过多,从而触发too many connections错误。通过使用消息队列,我们可以异步处理请求,从而缓解系统的压力。
MQ(消息队列)常见的应用场景解析(https://www.cnblogs.com/joylee/p/8916460.html)
MQ特点
- 先进先出
不能先进先出,都不能说是队列了。消息队列的顺序在入队的时候就基本已经确定了,一般是不需人工干预的。而且,最重要的是,数据是只有一条数据在使用中。 这也是MQ在诸多场景被使用的原因。 - 发布订阅
发布订阅是一种很高效的处理方式,如果不发生阻塞,基本可以当做是同步操作。这种处理方式能非常有效的提升服务器利用率,这样的应用场景非常广泛。 - 持久化
持久化确保MQ的使用不只是一个部分场景的辅助工具,而是让MQ能像数据库一样存储核心的数据。 - 分布式
在现在大流量、大数据的使用场景下,只支持单体应用的服务器软件基本是无法使用的,支持分布式的部署,才能被广泛使用。而且,MQ的定位就是一个高性能的中间件。
应用场景
应用解耦(异步)
系统之间进行数据交互的时候,在时效性和稳定性之间我们都需要进行选择。基于线程的异步处理,能确保用户体验,但是极端情况下可能会出现异常,影响系统的稳定性,而同步调用很多时候无法保证理想的性能,那么我们就可以用MQ来进行处理。上游系统将数据投递到MQ,下游系统取MQ的数据进行消费,投递和消费可以用同步的方式处理,因为MQ接收数据的性能是非常高的,不会影响上游系统的性能,那么下游系统的及时率能保证吗?当然可以,不然就不会有下面的一个应用场景。
通知
这里就用到了前文一个重要的特点,发布订阅,下游系统一直在监听MQ的数据,如果MQ有数据,下游系统则会按照 先进先出 这样的规则, 逐条进行消费 ,而上游系统只需要将数据存入MQ里,这样就既降低了不同系统之间的耦合度,同时也确保了消息通知的及时性,而且也不影响上游系统的性能。
限流
上文有说了一个非常重要的特性,MQ 数据是只有一条数据在使用中。 在很多存在并发,而又对数据一致性要求高,而且对性能要求也高的场景,如何保证,那么MQ就能起这个作用了。不管多少流量进来,MQ都会让你遵守规则,排除处理,不会因为其他原因,导致并发的问题,而出现很多意想不到脏数据。
数据分发
MQ的发布订阅肯定不是只是简单的一对一,一个上游和一个下游的关系,MQ中间件基本都是支持一对多或者广播的模式,而且都可以根据规则选择分发的对象。这样上游的一份数据,众多下游系统中,可以根据规则选择是否接收这些数据,这样扩展性就很强了。
PS:上文中的上游和下游,在MQ更多的是叫做生产者(producer)和消费者(consumer)。
分布式事务
分布式事务是我们开发中一直尽量避免的一个技术点,但是,现在越来越多的系统是基于微服务架构开发,那么分布式事务成为必须要面对的难题,解决分布式事务有一个比较容易理解的方案,就是二次提交。基于MQ的特点,MQ作为二次提交的中间节点,负责存储请求数据,在失败的情况可以进行多次尝试,或者基于MQ中的队列数据进行回滚操作,是一个既能保证性能,又能保证业务一致性的方案,当然,这个方案的主要问题就是定制化较多,有一定的开发工作量。
我为什么要选择RabbitMQ ,RabbitMQ简介,各种MQ选型对比(https://www.sojson.com/blog/48.html)
消息中间件(一)MQ详解及四大MQ比较(https://blog.csdn.net/wqc19920906/article/details/82193316)
消息队列mq总结(https://blog.51cto.com/13904503/2173827)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号