用向量检测异常网络流量原理
🔍 案例-场景模拟
假设一个学校图书馆的人流量比作网络流量去分析,
正常情况: 学生们安静借书、阅读,每小时大约50人进出,平均每人借2本书;
异常情况: 突然有200人冲进来,到处乱跑,但很少有人真的借书;
需求:
我们要检测这种“异常涌入”情况,然后告警出来。
📊 数据收集(简单版)
我们只监控两个最简单的指标(就像监控摄像头计数):
- 每分钟访问人数(对应网络:数据包数量)
- 平均每人停留时间(对应网络:连接时长)
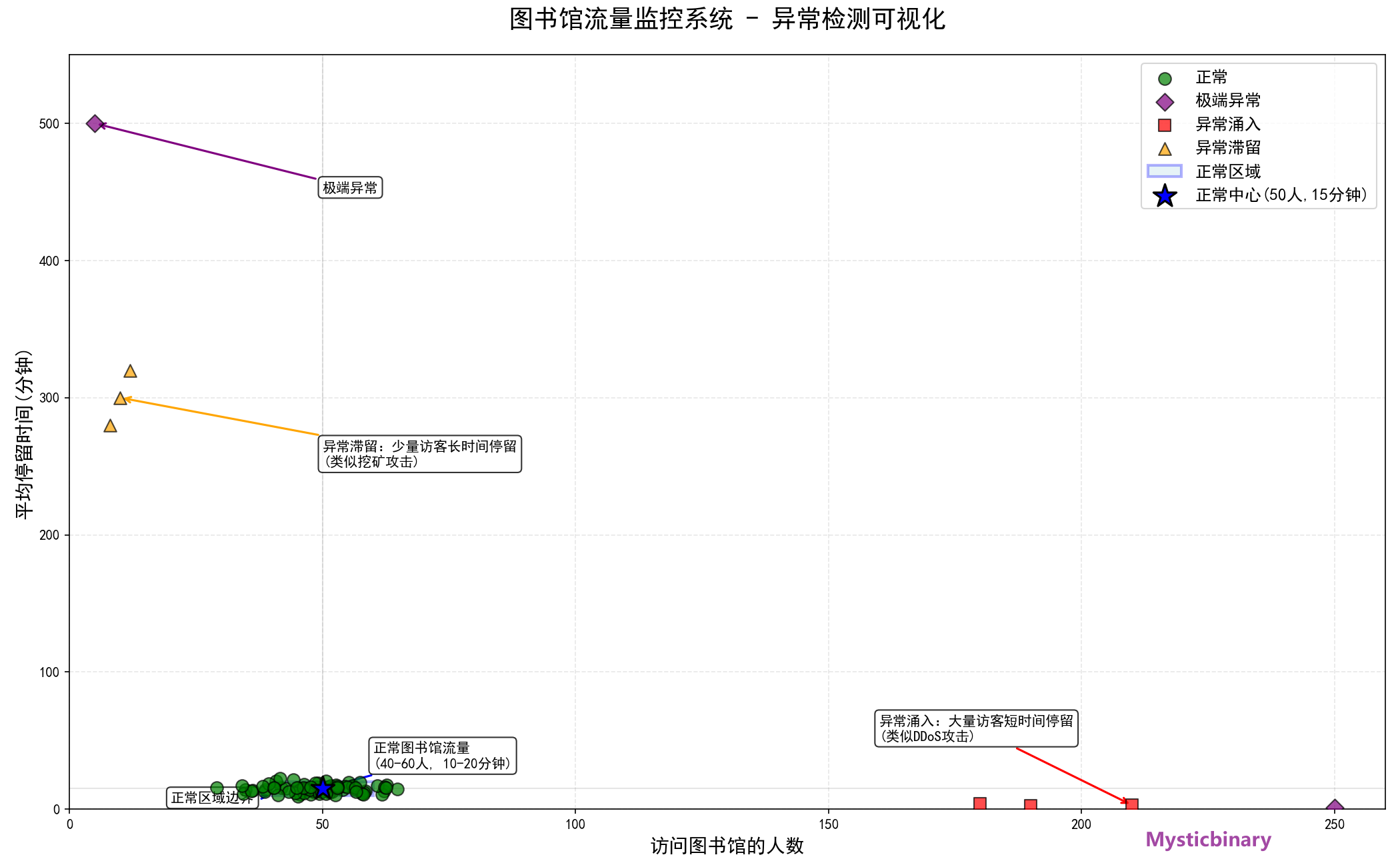
| 时间 | 访问人数 | 平均停留时间(分钟) | 状态 |
|---|---|---|---|
| 10:00 | 45 | 15 | 正常 |
| 10:01 | 52 | 12 | 正常 |
| 10:02 | 48 | 18 | 正常 |
| 10:03 | 210 | 3 | 异常 |
| 10:04 | 55 | 16 | 正常 |
🧮 向量表示
我们把每个时间点的数据变成一个“坐标点”(就是向量):
正常点: (45, 15)
正常点: (52, 12)
正常点: (48, 18)
异常点: (210, 3) ← 人数暴增,停留时间极短
🤖 简单检测规则(算法)
我们可以用距离公式(就像在坐标纸上量距离):
# 定义正常中心点(正常行为的平均值)
正常中心 = (50, 15) # 50人,15分钟
# 异常检测函数
def 是否异常(当前人数, 当前时间):
# 计算距离(简化版)
距离 = abs(当前人数 - 50) + abs(当前时间 - 15)
if 距离 > 100: # 阈值
return "🚨 异常警报!"
else:
return "正常"
测试一下:
- 输入 (45, 15):距离 = |45-50| + |15-15| = 5 → 正常
- 输入 (210, 3):距离 = |210-50| + |3-15| = 160+12=172 → 异常!
输出图形会显示:绿点聚集在一起,异常点明显偏离。
向量编写的自动化程序的作用:
- 向量就是“特征打包”:把多个测量值变成一个数学点;
- 异常检测就是找“离群点”:谁的行为和大家不一样?
- 距离衡量差异:数学上计算“有多不一样”;
- 自动化警报:电脑7x24小时盯着,比人眼可靠;
实际应用场景:
- 防火墙/IDS系统:实时计算当前流量向量
- 与历史正常模式比较:计算“距离”
- 超过阈值就报警:自动阻断或通知管理员
但实际做法会更复杂:
- 不止2个特征,可能是10-100个(包大小、协议类型、来源地区等)
- 用机器学习自动学习正常区域(不用手动设阈值)
- 使用向量数据库快速搜索相似历史攻击

 浙公网安备 33010602011771号
浙公网安备 33010602011771号