朴素贝叶斯算法预测中文钓鱼邮件
下文以一个检测钓鱼邮件的案例来学习这个算法的原理。
需求:
收到一封新邮件,程序怎么自动判断它是否为钓鱼邮件?
大致步骤
第一步:准备工具(训练模型)
目的:先让计算机学会识别钓鱼邮件的特征。
-
收集历史邮件数据:
- 1000封已知类型的邮件
- 其中:300封钓鱼邮件,700封正常邮件。
学校邮件中30%是钓鱼邮件(这是你的先验知识)。
-
提取关键特征:
我们关注邮件中是否出现某些关键词:["免费", "账号", "验证", "点击", "紧急", "赢取", "密码", "链接"] -
计算基础概率:
P(钓鱼) = 300/1000 = 0.3 P(正常) = 700/1000 = 0.7 -
计算每个词的条件概率:
以"免费"这个词为例:- 在300封钓鱼邮件中,270封包含"免费" →
P(免费|钓鱼) = 270/300 = 0.9 - 在300封钓鱼邮件中,240封包含"账号" →
P(账号|钓鱼) = 240/300 = 0.8 - 在700封正常邮件中,70封包含"免费" →
P(免费|正常) = 70/700 = 0.1 - ......(用同样方法计算其他词的概率)
- 在300封钓鱼邮件中,270封包含"免费" →
第二步:分析目标邮件(实际判断)
现在你要判断这封具体的邮件:
主题:账户安全通知
内容:尊敬的客户,您的账号存在异常登录,请立即点击下方链接验证身份,否则将被暂停使用。
对邮件主题和内容进行中文分词的过程,这里忽略掉了。
判断过程如下:
1. 提取这封邮件的特征
检查邮件中是否包含我们的关键词:
- 包含"账号":✓
- 包含"验证":✓
- 包含"点击":✓
- 包含"链接":✓
- 包含"免费":✗
- 包含"赢取":✗
- 包含"密码":✗
- 包含"紧急":✓("立即"可视为紧急)
2. 计算两种可能性得分
我们需要计算:这封邮件是钓鱼的可能性 vs 这封邮件是正常的可能性
计算公式简化版:
得分(钓鱼) = P(钓鱼) × P(特征1|钓鱼) × P(特征2|钓鱼) × ...
得分(正常) = P(正常) × P(特征1|正常) × P(特征2|正常) × ...
实际计算(使用训练阶段的数据):
A. 假设钓鱼可能性计算:
P(钓鱼) = 0.3
P(账号|钓鱼) = 0.8 (假设值)
P(验证|钓鱼) = 0.7 (假设值)
P(点击|钓鱼) = 0.85 (假设值)
P(链接|钓鱼) = 0.9 (假设值)
P(免费|钓鱼) = 0.9,但邮件中没有"免费" → 用(1-0.9)=0.1
P(紧急|钓鱼) = 0.75 (假设值)
得分_钓鱼 = 0.3 × 0.8 × 0.7 × 0.85 × 0.9 × 0.1 × 0.75
= 0.3 × 0.0003213 ≈ 0.0000964
B. 假设正常可能性计算:
P(正常) = 0.7
P(账号|正常) = 0.1 (假设值)
P(验证|正常) = 0.05 (假设值)
P(点击|正常) = 0.08 (假设值)
P(链接|正常) = 0.12 (假设值)
P(免费|正常) = 0.1,但邮件中没有"免费" → 用(1-0.1)=0.9
P(紧急|正常) = 0.15 (假设值)
得分_正常 = 0.7 × 0.1 × 0.05 × 0.08 × 0.12 × 0.9 × 0.15
= 0.7 × 0.00000648 ≈ 0.00000454
3. 做出判断
比较两个得分:
- 钓鱼得分:0.0000964
- 正常得分:0.00000454
因为 0.0000964 > 0.00000454,所以判断这封邮件很可能是钓鱼邮件。
第三步:现实中的优化
实际应用中,为了避免数值太小和未出现词的问题,会做以下调整:
-
使用对数计算(避免小数点太多):
log(得分_钓鱼) = log(0.3) + log(0.8) + log(0.7) + ... log(得分_正常) = log(0.7) + log(0.1) + log(0.05) + ...比较对数分数,结果相同但更稳定。
-
拉普拉斯平滑:
如果某个词在训练数据中从未在钓鱼邮件中出现过(概率为0),我们会给它一个很小的概率(如0.001),避免整个乘积为0。
朴素贝叶斯算法定义
朴素贝叶斯是一种基于概率论的分类算法,其核心思想是利用贝叶斯定理来预测一个样本属于哪个类别。 它的“朴素”之处在于假设样本的各个特征之间是相互独立、互不影响的,尽管这一假设在现实中往往不成立,但它极大地简化了计算,使得算法在很多复杂场景下仍然表现出色。
虽然独立事件往往并不能反映现实生活,但计算独立事件的概率要比计算非独立事件的概率容易得多。这种算法广泛应用于文本分类、垃圾邮件过滤和情感分析等领域。
假设有一个数据集,由两类组成(简化问题),对于每个样本的分类,我们都已经知晓。数据分布如下图:
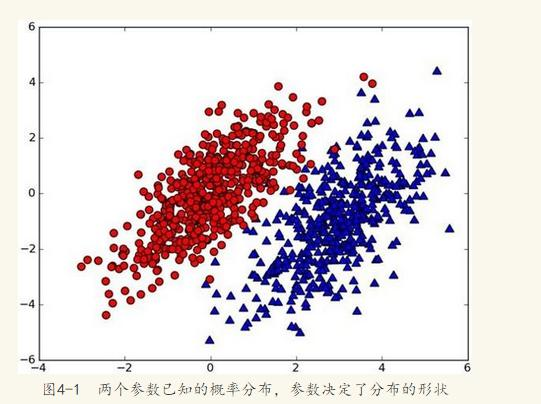
现在出现一个新的点new_point (x,y),其分类未知。我们可以用p1(x,y)表示数据点(x,y)属于红色一类的概率,同时也可以用p2(x,y)表示数据点(x,y)属于蓝色一类的概率。那要把new_point归在红、蓝哪一类呢?
我们提出这样的规则:
如果p1(x,y) > p2(x,y),则(x,y)为红色一类。
如果p1(x,y) <p2(x,y), 则(x,y)为蓝色一类。
换人类语言来描述这一规则:
选择概率高的一类作为新点的分类。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
用条件概率的方式定义这一贝叶斯分类准则:
如果p(red|x,y) > p(blue|x,y), 则(x,y)属于红色一类。
如果p(red|x,y) < p(blue|x,y), 则(x,y)属于蓝色一类。
也就是说,在出现一个需要分类的新点时,我们只需要计算这个点的:
max(p(c1 | x,y),p(c2 | x,y),p(c3 | x,y)...p(cn| x,y))
// 其对于的最大概率标签,就是这个新点的分类了。
Reference
朴素贝叶斯算法 & 应用实例
http://www.cnblogs.com/marc01in/p/4775440.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号